


{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
TextToSpeech and Back Again avec AWS (2ème partie)
Il s'agit de la deuxième partie d'une série sur la transformation de contenu entre texte et discours sur AWS. Dans la première partie nous avons utilisé Amazon Polly pour commenter les billets de blog et incorporer le contenu dans un site Web à l'aide d'une balise audio. Dans cet article, nous utiliserons la synthèse vocale pour rédiger des transcriptions de podcasts et des interviews pour publication. Enfin, nous évaluerons la précision globale de ces technologies de transformation de format en analysant quelques échantillons lors de transcriptions aller-retour
Projet discours-texte
En 2012, Patrick McKenzie ( patio11 ]de Kalzumeus et de Stripe ) et de Ramit Sethi (de Je t'apprendrai à être riche ) s'assirent et enregistrèrent des podcasts d'une durée de deux heures. En tant que fan de leur travail, j’aurais probablement écouté les podcasts, mais je ne les aurais certainement pas écoutés plusieurs fois. Les transcriptions, par contre, je peux les relire et les consulter à ma guise. Je recommande aussi librement la série lorsque je parle aux gens de la pige, sachant que je leur donne une ressource dont la lecture prend un quart du temps qu'il faut pour l'écouter. Même si le contenu des podcasts et des transcriptions est exactement le même, la combinaison est 10 fois plus utile que le podcast seul.
Dans la première transcription McKenzie dit qu'il a payé 75 dollars et a attendu quelques jours pour que le podcast soit retranscrit par un service professionnel. Son autre option était de le transcrire lui-même. Quand je travaillais pour le journal de mon collège, je traduisais souvent des interviews. Au fil du temps, je me suis davantage exercée à la technique et je suis passée de quatre minutes de transcription audio à trois minutes par minute. Bien que j'imagine qu'un professionnel disposant d'un équipement spécialisé et d'une vitesse de frappe plus rapide puisse chuter en dessous de deux minutes par minute, un transcripteur amateur, McKenzie, s'est probablement épargné cinq ou six heures de travail en payant pour le service.
Sept ans plus tard, il semble avoir besoin d’une autre option: une transcription automatisée avec Amazon Web Services. Comme nous le verrons, la transcription nécessiterait beaucoup plus d’édition avant d’être prête pour la publication, mais la transcription automatisée a deux caractéristiques qui la rendent plus coûteuse que l’embauche d’un professionnel: il aurait récupéré la transcription en temps réel pour environ un dollar. Dans cet article, j’expliquerai comment vous pouvez utiliser la synthèse vocale sur AWS pour facilement rendre votre contenu multi-format et vos idées pour utiliser Amazon Transcribe dans des applications plus complexes.
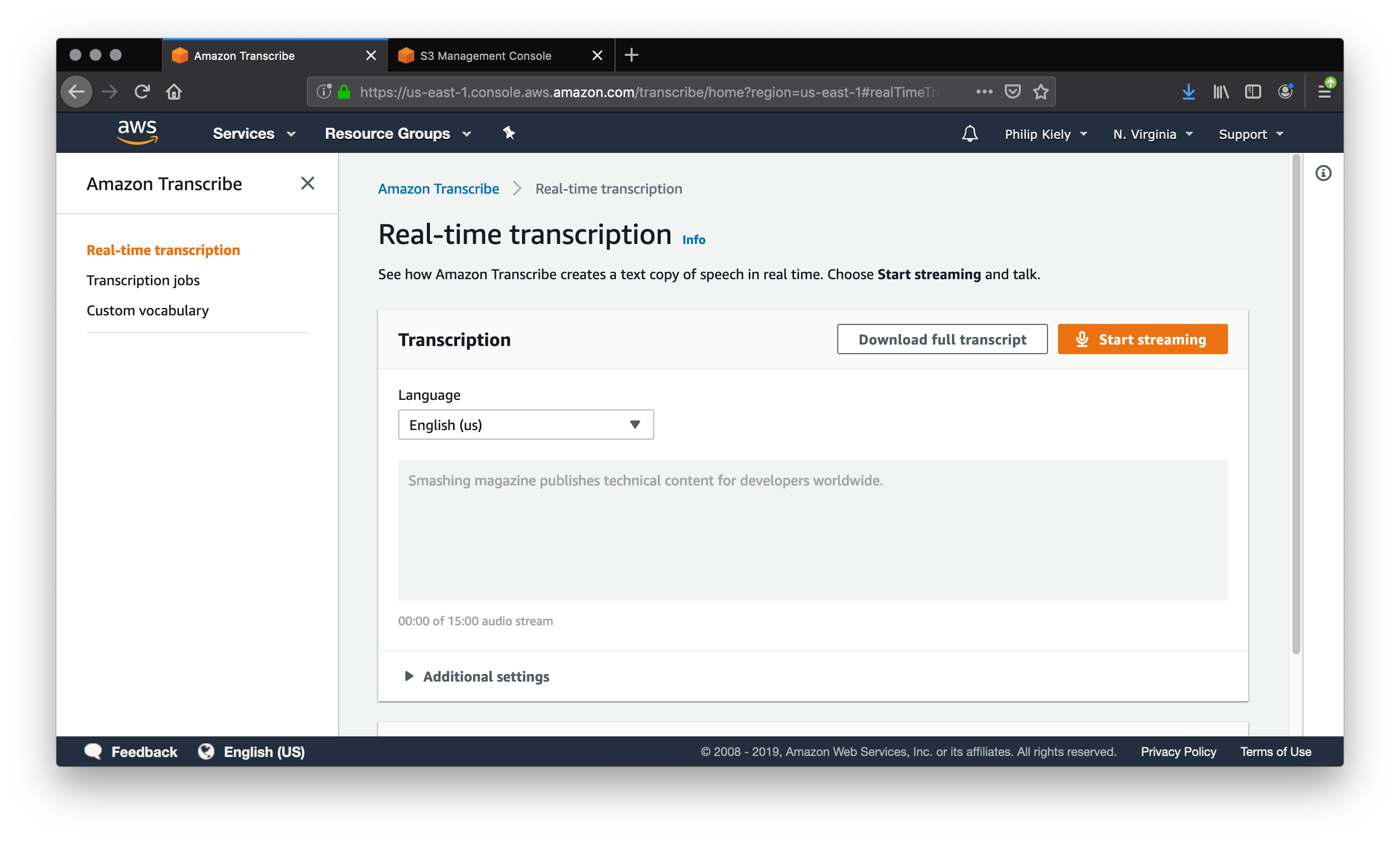
Amazon fournit une console pour expérimenter Transcribe. Pour accéder à la console, connectez-vous à votre compte AWS et recherchez «Transcribe» dans le champ de recherche de services. La console expose toute la puissance de Transcribe. Si vous envisagez de ne transcrire que quelques éléments de contenu par semaine, alors utiliser la console est une solide option à long terme. La console de transcription vous offre deux options: transmission audio en continu et téléchargement d'un fichier.

L'onglet “transcription en temps réel” offre la possibilité de parler dans le microphone et d'obtenir une transcription générée en temps réel. De façon délibérée, et avec le microphone intégré à mon ordinateur, j’ai pu transcrire la phrase «Smashing Magazine publie du contenu technique pour les développeurs du monde entier» au premier essai. Cependant, lorsque j'ai essayé de transcrire le paragraphe précédent à une vitesse et une articulation plus conversationnelles, de nombreuses erreurs ont été commises.
«Amazon fournit un consul pour expérimenter l'accès transcrit. La console se connecte à un compte ws et la recherche est transcrite dans le champ de recherche de services. Le consul expose toute la puissance de la transcription. Et si vous ne prévoyez que de transcrire quelques éléments de contenu par semaine que d’utiliser le consul, c’est une solide option à long terme. Le Conseil de transcription vous propose deux options pour diffuser l'audio en continu et télécharger un fichier. ”
En plus de manquer quelques mots, Transcribe a des problèmes d'homophones et de ponctuation. Dans la première phrase, il transcrit «console» en «consul». Cette erreur d’homophone ne peut être corrigée qu’en évaluant chaque mot transcrit dans le contexte de la phrase et en l’ajustant en fonction de la meilleure hypothèse de l’algorithme. La première phrase se mêle également à la seconde, qui jette de côté la structure grammaticale et la signification de tout le reste du paragraphe. Au-delà des indices contextuels, Amazon Transcribe semble utiliser des pauses pour déterminer la ponctuation. Cela dit, j’utilise un microphone intégré, la transcription en temps réel, et pour être honnête, je n’ai pas la voix la plus claire. Voyons si nous pouvons trouver des améliorations en atténuant chacun de ces facteurs.
J’ai utilisé un Blue Yeti, un microphone d’enregistrement polyvalent de milieu de gamme, pour diffuser de l’audio dans la console. Comme vous pouvez le voir dans l'image ci-dessous, l'amélioration de la qualité audio n'a pas significativement amélioré la qualité de la transcription. Je suppose que si une entrée audio de mauvaise qualité dégraderait davantage la précision du texte, une amélioration dépassant le seuil d'un microphone intégré ou d'une webcam bon marché ne fournit pas la transcription de qualité que nous recherchons.

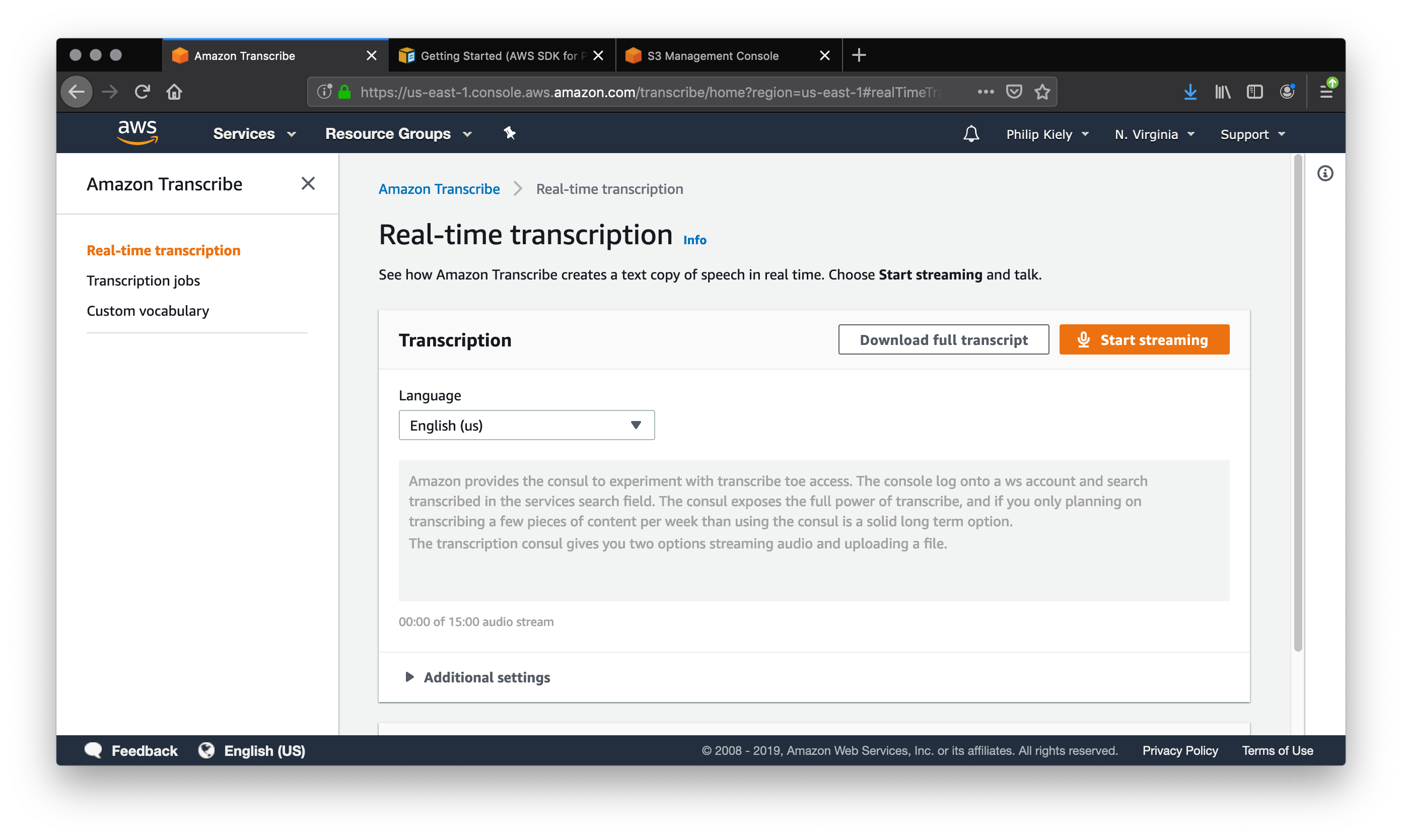
En utilisant le même microphone, j’enregistrais le même paragraphe qu’un fichier .mp3 et le téléchargeais pour la transcription. Pour faire de même, accédez au panneau «Travaux de transcription», puis cliquez sur le bouton orange avec le texte «Créer un travail». Cela vous mènera à un formulaire dans lequel vous pourrez configurer le travail de transcription.
![Formulaire de travail de transcription en haut à moitié [19659011] Un travail de transcription requiert un titre, une langue, une source d'entrée et un format de fichier. (<a href=](https://i0.wp.com/cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/799ad029-589d-4006-9d36-25e9296205c1/aws-transcribe-job-1.png?ssl=1) Grand aperçu )
Grand aperçu ) Le nom du travail est arbitraire. Choisissez un élément qui aura du sens pour vous lorsque vous passerez en revue les travaux terminés. Vous pouvez choisir parmi une douzaine de langues, l'anglais et l'espagnol étant disponibles en variantes régionales. Le service de transcription tire ses entrées de S3. Vous devez donc télécharger votre fichier audio sur le service de stockage avant de pouvoir exécuter le travail. Vous pouvez télécharger le fichier dans un des quatre formats pris en charge: .mp3 .mp4 .wav et .flac . [19659022] Formulaire de travail de transcription, moitié inférieure « />
Si vous souhaitez conserver les données de sortie dans un emplacement permanent, définissez «Emplacement des données» sur «Spécifié par le client» et entrez le nom d'un compartiment S3 dans lequel vous pouvez écrire. Enfin, vous pouvez choisir entre deux options d’identification. Les étiquettes d’identification de canal entrent avec le canal dont il provient dans le fichier audio, alors que «Identification du haut-parleur» tente de reconnaître des voix distinctes dans l’audio. Si vous transcrivez un podcast ou une interview à plusieurs personnes, l'identification du locuteur est une fonction utile, mais elle ne s'applique pas à ce simple test.
L'inspection de la sortie révèle malheureusement que la transcription n'est pas plus précise que la réalité. transcription de la console de temps. Toutefois, l'exécution d'un travail de transcription fournit davantage de données. En plus du texte de transcription, le travail génère JSON avec chaque mot, son indice de confiance et les autres mots considérés, le cas échéant. Si vous voulez écrire votre propre code de traitement en langage naturel pour améliorer la lisibilité de la sortie, ces données vous donneront ce dont vous avez besoin pour commencer.
Enfin, j'avais un ami qui anime une émission de radio locale qui raconte la même paragraphe pour la transcription en direct. Malgré son rythme soutenu et son énonciation claire, le texte résultant n'était pas plus précis que mes tentatives de transcription en direct. Bien qu'un narrateur professionnel puisse parvenir à une prononciation encore plus précise, la technologie n'est vraiment utile que si elle est largement utilisable.
Malheureusement, il semble que la qualité de la transcription soit trop faible pour automatiser complètement notre cas d'utilisation proposé. Selon votre vitesse de frappe, exécuter l'audio via Amazon Transcribe, puis l'édition manuelle peut s'avérer plus rapide que la simple transcription manuelle, mais il ne s'agit pas d'une solution clé en main pour la synthèse vocale qui se compare à celle existant pour la synthèse textuelle. Pour des domaines spécifiques, vous pouvez définir des vocabulaires personnalisés afin d'améliorer la précision de la transcription, mais le service est insuffisamment développé.
Comme pour la plupart de ses services, AWS offre une API pour utiliser Transcribe. À moins que vous ayez un grand nombre de fichiers à transcrire ou que vous ayez besoin de transcrire de l'audio en réponse à des événements, je vous recommande d'utiliser la console et de gagner du temps pour la configuration de l'accès par programme.
Pour utiliser Transcribe à partir de l'AWS CLI, vous Vous aurez besoin d'un fichier JSON et d'une commande de terminal.
aws transcribe start-transcription-job
--region YOUR_REGION_HERE
--cli-input-json YOUR_FILE_PATH.json Dans YOUR_FILE_PATH.json vous aurez besoin d’un fichier .json contenant quatre informations. Comme ci-dessus, vous pouvez définir toute chaîne explicite en tant que TranscriptionJobName et toute langue prise en charge en tant que LanguageCode. La CLI prend en charge les mêmes quatre formats de fichier multimédia et lit toujours le fichier multimédia à partir de S3.
{
"TranscriptionJobName": "ID de la demande",
"LanguageCode": "en-US",
"MediaFormat": "mp3",
"Médias": {
"MediaFileUri": "https: //YOUR_S3_BUCKET/YOUR_MEDIA_FILE.mp3"
}
} Ce type d'accès est également disponible via un SDK Python. Amazon recommande Transcribe pour les supports d'analyse vocale, de recherche et de conformité, de publicité et de sous-titrage. Dans chacun de ces cas, le texte transcrit est une entrée vers un autre système tel qu'Amazon Comprehend plutôt que la sortie finale. Par conséquent, en tant que développeur, il est important de concevoir votre système et de limiter ses cas d'utilisation afin de tolérer le nombre d'erreurs que Transcribe introduira dans votre application.
Note : Pour en savoir plus sur l'utilisation de Amazon Transcribe et d'autres services par programme, consultez Le guide de démarrage d'Amazon .
Précision d'aller-retour
Bien que les performances en direct d'Amazon Transcribe aient été quelque peu décevantes, nous pouvons examiner la précision théorique du système. en transcrivant quelque chose qui a été lu par Amazon Polly. Les deux services doivent utiliser des bibliothèques de prononciation et des rythmes de parole compatibles. Par conséquent, la saisie de texte dans Amazon Polly doit être préservée plus ou moins intacte. Bien sûr, nous nous en tiendrons au même paragraphe d’essai.
Et voilà, c’est la seule stratégie qui a sensiblement amélioré la transcription:
«Amazon fournit une console d’expérimentation avec la transcription. Pour accéder à la console, connectez-vous à votre compte AWS et recherchez la transcription du champ de recherche du service. La console expose toute la puissance de la transcription, et si vous envisagez de ne transcrire que quelques éléments de contenu par semaine, l’utilisation de la console est une solide option à long terme. Le conseil de transcription vous offre deux options. Lecture audio en continu et téléchargement d'un fichier. ”
Des erreurs persistantes persistent (“ conseil ”contre“ console ”avec une confiance de 70%), mais dans l'ensemble, le texte ne peut être utilisé que quelques modifications. Cependant, comme la plupart d'entre nous ne parlent pas comme des robots synthétisés, cette qualité ne nous est pas disponible au moment de la rédaction.
Conclusion
Bien que la qualité de la production de la parole et du texte soit sensiblement inférieure à celle d'une personne, ces services coûtent si peu qu'ils constituent une alternative solide pour de nombreuses applications. La synthèse vocale, à 4 dollars par million de caractères (16 dollars par million pour les voix neurales supérieures), permet de raconter des articles en quelques secondes pour quelques centimes. La parole à texte, à 0,04 centime par seconde, permet de transcrire des podcasts en quelques minutes pour environ un dollar. Bien sûr, les prix peuvent évoluer avec le temps, mais au fil du temps, les technologies comme celles-ci s'améliorent et tendent à devenir moins onéreuses et plus efficaces.
En raison de leur faible coût, vous pouvez expérimenter avec ces technologies, par exemple pour améliorer votre productivité personnelle. Il est impossible de taper des notes ou d’esquisser un projet en vélo ou en voiture, mais parler et transcrire automatiquement une narration de flux de conscience nécessiterait beaucoup de planification. Les journalistes transcrivent souvent de longues interviews, un processus qu'AWS peut automatiser en balisant les voix des personnes s'exprimant dans un enregistrement. De l'autre côté du processus d'écriture, le fait de lire votre travail de manière robotique et régulière peut vous aider à identifier les erreurs et les phrasés maladroits.
Ces technologies ont déjà un certain nombre de cas d'utilisation, mais cela ne fera qu'augmenter avec le temps. à mesure que les technologies s'améliorent. Si la prononciation de la synthèse vocale atteint une précision presque parfaite, en particulier si elle est assistée par des alphabets et des balises de prononciation, la voix synthétisée ne semble toujours pas totalement naturelle. Les systèmes de synthèse vocale sont assez efficaces pour transcrire des discours clairs, mais ont encore du mal à respecter la ponctuation, les homophones et même les discours modérément rapides. Une fois que les technologies auront surmonté ces défis, je prévois que la plupart des applications pourront être utilisées par au moins une d'entre elles.
 (dm, yk, il)
(dm, yk, il) Source link