
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
L'IA apprend maintenant à évoluer comme des formes de vie terrestres

Cet article fait partie de nos revues d'articles de recherche sur l'IA une série de publications qui explorent les dernières découvertes en matière d'intelligence artificielle.
Des centaines de millions d'années d'évolution ont béni notre planète avec un grande variété de formes de vie, chacune intelligente à sa manière. Chaque espèce a évolué pour développer des compétences innées, des capacités d'apprentissage et une forme physique qui assurent sa survie dans son environnement.
Mais en dépit d'être inspiré par la nature et l'évolution, le domaine de l'intelligence artificielle s'est largement concentré sur la création des éléments de l'intelligence. séparément et en les fusionnant après le développement. Bien que cette approche ait donné d'excellents résultats, elle a également limité la flexibilité des agents d'IA dans certaines des compétences de base trouvées même dans les formes de vie les plus simples.
Dans un nouvel article publié dans la revue scientifique Nature, Des chercheurs en IA de l'Université de Stanford présentent une nouvelle technique qui peut aider à franchir certaines de ces limites. Intitulée « Deep Evolutionary Reinforcement Learning », la nouvelle technique utilise un environnement virtuel complexe et un apprentissage par renforcement pour créer des agents virtuels qui peuvent évoluer à la fois dans leur structure physique et leurs capacités d’apprentissage. Les résultats peuvent avoir des implications importantes pour l'avenir de la recherche en IA et en robotique.
Dans la nature, le corps et le cerveau évoluent ensemble. À travers de nombreuses générations, chaque espèce animale a traversé d'innombrables cycles de mutation pour développer des membres, des organes et un système nerveux afin de soutenir les fonctions dont elle a besoin dans son environnement. Les moustiques ont une vision thermique pour détecter la chaleur corporelle. Les chauves-souris ont des ailes pour voler et un appareil d'écholocalisation pour naviguer dans les endroits sombres. Les tortues marines ont des nageoires pour nager et un système de détection de champ magnétique pour parcourir de très longues distances. Les humains ont une posture droite qui libère leurs bras et leur permet de voir l'horizon lointain, des mains et des doigts agiles qui peuvent manipuler des objets, et un cerveau qui fait d'eux les meilleures créatures sociales et résolveurs de problèmes sur la planète.
Fait intéressant, tout cela. Les espèces descendent de la première forme de vie apparue sur Terre il y a plusieurs milliards d'années. Sur la base des pressions de sélection causées par l'environnement, les descendants de ces premiers êtres vivants ont évolué dans de nombreuses directions différentes.
L'étude de l'évolution de la vie et de l'intelligence est intéressante. Mais le reproduire est extrêmement difficile . Un système d'IA qui voudrait recréer une vie intelligente de la même manière que l'évolution l'a fait devrait rechercher un très grand espace de morphologies possibles, ce qui est extrêmement coûteux en calcul. Cela nécessiterait de nombreux cycles d'essais et d'erreurs parallèles et séquentiels.
Les chercheurs en IA utilisent plusieurs raccourcis et fonctionnalités prédéfinies pour surmonter certains de ces défis. Par exemple, ils corrigent l'architecture ou la conception physique d'une IA ou d'un système robotique et se concentrent sur l'optimisation des paramètres d'apprentissage. Un autre raccourci est l'utilisation de l'évolution Lamarckienne plutôt que darwinienne, dans laquelle les agents d'IA transmettent leurs paramètres appris à leurs descendants. Une autre approche consiste à former séparément différents sous-systèmes d'IA (vision, locomotion, langage, etc.), puis à les assembler dans un système final d'IA ou de robotique. Bien que ces approches accélèrent le processus et réduisent les coûts de formation et d'évolution des agents d'IA, elles limitent également la flexibilité et la variété des résultats qui peuvent être obtenus. Crédit : Ben Dickson / TechTalks
Dans leurs nouveaux travaux, les chercheurs de Stanford visent à rapprocher la recherche en IA de la véritable évolution processus tout en maintenant les coûts aussi bas que possible. "Notre objectif est d'élucider certains principes régissant les relations entre la complexité environnementale, la morphologie évoluée et la capacité d'apprentissage du contrôle intelligent", écrivent-ils dans leur article.
Leur cadre s'appelle Deep Evolutionary Reinforcement Learning. Dans le DERL, chaque agent utilise un apprentissage par renforcement approfondi pour acquérir les compétences nécessaires pour maximiser ses objectifs au cours de sa vie. DERL utilise l'évolution darwinienne pour rechercher dans l'espace morphologique des solutions optimales, ce qui signifie que lorsqu'une nouvelle génération d'agents d'IA est engendrée, ils n'héritent que des traits physiques et architecturaux de leurs parents (avec de légères mutations). Aucun des paramètres appris n'est transmis d'une génération à l'autre.
« DERL ouvre la porte à la réalisation d'expériences in silico à grande échelle pour fournir des informations scientifiques sur la façon dont l'apprentissage et l'évolution créent en coopération des relations sophistiquées entre la complexité environnementale, l'intelligence morphologique et la capacité d'apprentissage. des tâches de contrôle », écrivent les chercheurs.
Simulation d'évolution
Leur espace de conception s'appelle UNIversal aniMAL (UNIMAL), dans lequel le but est de créer des morphologies qui apprennent des tâches de locomotion et de manipulation d'objets dans une variété de terrains.
Chaque agent dans l'environnement est composé d'un génotype qui définit ses membres. et articulations. Le descendant direct de chaque agent hérite du génotype du parent et subit des mutations qui peuvent créer de nouveaux membres, supprimer des membres existants ou apporter de petites modifications à des caractéristiques telles que les degrés de liberté ou la taille des membres.
Chaque agent est entraîné avec. apprentissage par renforcement pour maximiser les récompenses dans divers environnements. La tâche la plus élémentaire est la locomotion, dans laquelle l'agent est récompensé pour la distance qu'il parcourt au cours d'un épisode. Les agents dont la structure physique est mieux adaptée pour traverser le terrain apprennent plus rapidement à utiliser leurs membres pour se déplacer.
Pour tester les résultats du système, les chercheurs ont généré des agents dans trois types de terrains : plat (FT), variable (VT) et terrains variables avec objets modifiables (MVT). Le terrain plat exerce une pression de sélection moindre sur la morphologie des agents. Les terrains variables, en revanche, obligent les agents à développer une structure physique plus polyvalente qui peut gravir des pentes et contourner les obstacles. La variante MVT présente le défi supplémentaire d'exiger des agents qu'ils manipulent des objets pour atteindre leurs objectifs.
Les avantages de DERL
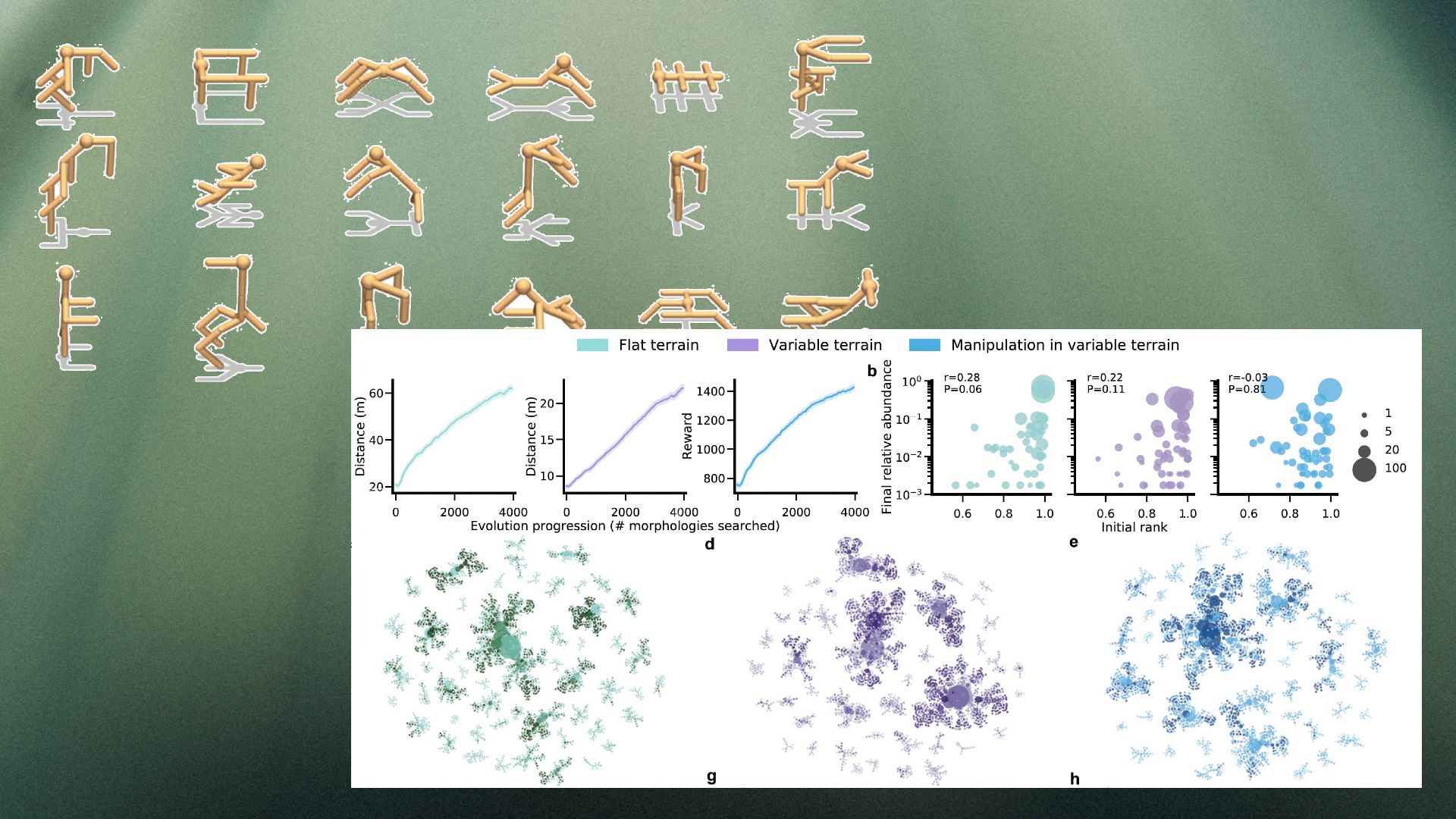

L'une des découvertes intéressantes du DERL est la diversité des résultats. D'autres approches de l'IA évolutive ont tendance à converger vers une solution, car les nouveaux agents héritent directement du physique et des apprentissages de leurs parents. Mais dans DERL, seules les données morphologiques sont transmises aux descendants, le système finit par créer un ensemble diversifié de morphologies réussies, y compris des bipèdes, des tripèdes et des quadrupèdes avec et sans bras.
En même temps, le système montre des traits de caractère. l'effet Baldwinqui suggère que les agents qui apprennent plus rapidement sont plus susceptibles de se reproduire et de transmettre leurs gènes à la génération suivante. Le DERL montre que l'évolution "sélectionne des apprenants plus rapides sans aucune pression de sélection directe pour le faire", selon l'article de Stanford.
" Curieusement, l'existence de cet effet Baldwin morphologique pourrait être exploitée dans de futures études pour créer des agents complexité de l'échantillon et capacité de généralisation plus élevée », écrivent les chercheurs.
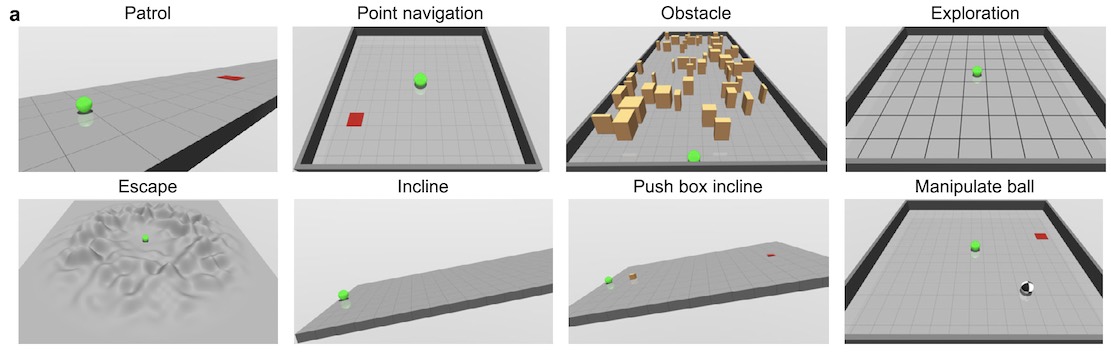
Enfin, le cadre DERL valide également l'hypothèse que des environnements plus complexes donneront naissance à des agents plus intelligents. Les chercheurs ont testé les agents évolués sur huit tâches différentes, notamment la patrouille, l'évasion, la manipulation d'objets et l'exploration. Leurs résultats montrent qu'en général, les agents qui ont évolué sur des terrains variables apprennent plus rapidement et fonctionnent mieux que les agents d'IA qui n'ont connu que des terrains plats.
Leurs résultats semblent être conformes à une autre hypothèse des chercheurs de DeepMind ] qu'un environnement complexe, une structure de récompense adaptée et un apprentissage par renforcement peuvent éventuellement conduire à l'émergence de toutes sortes de comportements intelligents. monde. "Bien que DERL nous permette de faire un pas en avant significatif dans la mise à l'échelle de la complexité des environnements évolutifs, une ligne importante de travaux futurs impliquera la conception d'environnements évolutifs plus ouverts, physiquement réalistes et multi-agents", écrivent les chercheurs.[19659002] À l'avenir, les chercheurs élargiront l'éventail des tâches d'évaluation pour mieux évaluer comment les agents peuvent améliorer leur capacité à apprendre des comportements pertinents pour l'homme.
Le travail peut avoir des implications importantes pour l'avenir de l'IA et de la robotique et pousser les chercheurs d'utiliser des méthodes d'exploration beaucoup plus similaires à l'évolution naturelle.
« Nous espérons que nos travaux encourageront d'autres explorations à grande échelle de l'apprentissage et de l'évolution dans d'autres contextes afin de fournir de nouvelles connaissances scientifiques sur l'émergence de comportements intelligents rapidement apprenants, ainsi que comme de nouvelles avancées techniques dans notre capacité à les instancier dans des machines », écrivent les chercheurs.
Cet article a été publié à l'origine par Ben Dickson sur TechTalksune publication qui examine les tendances technologiques, comment elles affectent notre façon de vivre et de faire des affaires, et les problèmes qu'elles résolvent. Mais nous discutons également du côté pervers de la technologie, des implications plus sombres des nouvelles technologies et de ce que nous devons rechercher. Vous pouvez lire l'article originalici.
Source link