
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Concepts de base (partie 1) —

Après près de cinq ans de développement, le nouveau protocole HTTP/3 approche de sa forme finale. Les itérations précédentes étaient déjà disponibles en tant que fonctionnalité expérimentale, mais vous pouvez vous attendre à ce que la disponibilité et l'utilisation de HTTP/3 proprement dite s'intensifient en 2021. Alors, qu'est-ce que HTTP/3 exactement ? Pourquoi était-ce nécessaire si peu de temps après HTTP/2 ? Comment pouvez-vous ou devez-vous l'utiliser? Et surtout, comment améliore-t-il les performances Web ? Découvrons-le.
Vous avez peut-être lu des articles de blog ou entendu des conférences sur ce sujet et pensez connaître les réponses. Vous avez probablement entendu des choses comme : « HTTP/3 est beaucoup plus rapide que HTTP/2 en cas de perte de paquets », ou « les connexions HTTP/3 ont moins de latence et prennent moins de temps à configurer », et probablement « HTTP/3 peuvent envoyer des données plus rapidement et peuvent envoyer plus de ressources en parallèle ».
Ces déclarations et articles ignorent généralement certains détails techniques cruciauxmanquent de nuances et ne sont généralement que partiellement corrects. Souvent, ils donnent l'impression que HTTP/3 est une révolution des performances, alors qu'il s'agit en réalité d'une évolution plus modeste (mais toujours utile !) . C'est dangereux, car le nouveau protocole ne sera probablement pas à la hauteur de ces attentes élevées dans la pratique. Je crains que cela ne conduise de nombreuses personnes à être déçues et à ce que les nouveaux arrivants soient désorientés par des tas de désinformation perpétuée aveuglément.
J'ai peur de cela parce que nous avons vu exactement la même chose avec HTTP/2. Il a été présenté comme une révolution des performances étonnante, avec de nouvelles fonctionnalités intéressantes telles que le serveur push, les flux parallèles et la hiérarchisation. Nous aurions pu arrêter de regrouper les ressources, arrêter de partager nos ressources sur plusieurs serveurs et rationaliser considérablement le processus de chargement des pages. Les sites Web deviendraient comme par magie 50 % plus rapides en appuyant simplement sur un bouton !
Cinq ans plus tard, nous savons que le push serveur ne fonctionne pas vraiment en pratique, les flux et la priorisation sont souvent mal implémentés et, par conséquent, resource bundling et even sharding toujours de bonnes pratiques dans certaines situations.
De même, d'autres mécanismes qui modifient le comportement du protocole, tels que les indices de préchargementcontiennent souvent des cachés profondeurs et des bugsce qui les rend difficiles à utiliser correctement.
En tant que tel, je pense qu'il est important d'empêcher ce type de désinformation et ces attentes irréalistes de se propager également pour HTTP/3.
Dans cette série d'articles, je discuterai du nouveau protocole, en particulier de son caractéristiques de performanceavec plus de nuances. Je montrerai que, bien que HTTP/3 ait effectivement de nouveaux concepts prometteurs, malheureusement, leur impact sera probablement relativement limité pour la plupart des pages Web et des utilisateurs (mais potentiellement crucial pour un petit sous-ensemble). HTTP/3 est également assez difficile à configurer et à utiliser (correctement), alors faites attention lors de la configuration du nouveau protocole.
Cette série est divisée en trois parties :
- Historique et concepts de base de HTTP/3
Ceci s'adresse aux personnes qui découvrent HTTP/3 et les protocoles en général, et traite principalement des bases. - Fonctionnalités de performance HTTP/3 (bientôt disponible !)
C'est plus approfondie et technique. Les personnes connaissant déjà les bases peuvent commencer ici. - Options de déploiement HTTP/3 pratiques (bientôt disponible !)
Cela explique les défis liés au déploiement et au test de HTTP/3 vous-même. . Il détaille également comment et si vous devez modifier vos pages Web et vos ressources.
Cette série s'adresse principalement aux développeurs Web qui n'ont pas nécessairement une connaissance approfondie des protocoles et qui souhaitent en savoir plus. Cependant, il contient suffisamment de détails techniques et de nombreux liens vers des sources externes pour intéresser également les lecteurs plus avancés.
Pourquoi avons-nous besoin de HTTP/3 ?
Une question que j'ai souvent rencontrée est : "Pourquoi avons-nous besoin de HTTP/3 si tôt après HTTP/2, qui n'a été standardisé qu'en 2015 ? » C'est en effet étrange, jusqu'à ce que vous réalisiez que nous n'avions pas vraiment besoin d'une nouvelle version HTTP en premier lieu, mais plutôt d'une mise à niveau du Transmission Control Protocol (TCP) sous-jacent.
TCP est le protocole principal qui fournit des services cruciaux tels que la fiabilité et la livraison dans l'ordre à d'autres protocoles tels que HTTP. C'est également l'une des raisons pour lesquelles nous pouvons continuer à utiliser Internet avec de nombreux utilisateurs simultanés, car cela limite intelligemment l'utilisation de la bande passante de chaque utilisateur à sa juste part.
Le saviez-vous ?
Lorsque vous utilisez HTTP(S), vous êtes utilisant réellement plusieurs protocoles en plus de HTTP en même temps. Chacun des protocoles de cette « pile » a ses propres caractéristiques et responsabilités (voir l'image ci-dessous). Par exemple, alors que HTTP traite les URL et l'interprétation des données, Transport Layer Security (TLS) assure la sécurité par cryptage, TCP permet un transport de données fiable en retransmettant les paquets perdus, et le protocole Internet (IP) achemine les paquets d'un point de terminaison à un autre sur différents appareils dans entre (boîtes intermédiaires).
Cette « superposition » de protocoles les uns au-dessus des autres est effectuée pour permettre une réutilisation facile de leurs fonctionnalités. Les protocoles de couche supérieure (tels que HTTP) n'ont pas à réimplémenter des fonctionnalités complexes (telles que le cryptage) car les protocoles de couche inférieure (tels que TLS) le font déjà pour eux. Autre exemple, la plupart des applications sur Internet utilisent TCP en interne pour s'assurer que toutes leurs données sont transmises dans leur intégralité. Pour cette raison, TCP est l'un des protocoles les plus largement utilisés et déployés sur Internet.

TCP est une pierre angulaire du Web depuis des décennies, mais il a commencé à montrer son âge à la fin des années 2000. Son remplacement prévu, un nouveau protocole de transport nommé QUICdiffère suffisamment de TCP sur plusieurs points clés pour qu'exécuter HTTP/2 directement dessus serait très difficile. En tant que tel, HTTP/3 lui-même est une adaptation relativement petite de HTTP/2 pour le rendre compatible avec le nouveau protocole QUIC, qui inclut la plupart des nouvelles fonctionnalités qui enthousiasment les gens.
QUIC est nécessaire car TCP, qui a été autour depuis les premiers jours d'Internet, n'a pas vraiment été construit avec une efficacité maximale à l'esprit. Par exemple, TCP requiert une « handshake » pour établir une nouvelle connexion. Ceci est fait pour s'assurer que le client et le serveur existent et qu'ils sont disposés et capables d'échanger des données. Cependant, cela prend également un aller-retour complet du réseau avant que quoi que ce soit d'autre puisse être fait sur une connexion. Si le client et le serveur sont géographiquement éloignés, chaque temps d'aller-retour (RTT) peut prendre plus de 100 millisecondes, entraînant des retards notables. file » ou flux d'octets même si nous l'utilisons pour transférer plusieurs fichiers en même temps (par exemple, lors du téléchargement d'une page Web composée de nombreuses ressources). En pratique, cela signifie que si des paquets TCP contenant les données d'un seul fichier sont perdus, tous les autres fichiers seront également retardés jusqu'à ce que ces paquets soient récupérés. . Bien que ces inefficacités soient tout à fait gérables dans la pratique (sinon, nous n'aurions pas utilisé TCP depuis plus de 30 ans), elles affectent de manière notable les protocoles de niveau supérieur tels que HTTP.
Au fil du temps, nous avons essayé faire évoluer et mettre à niveau TCP pour améliorer certains de ces problèmes et même introduire de nouvelles fonctionnalités de performance. Par exemple, TCP Fast Open supprime la surcharge de négociation en permettant aux protocoles de couche supérieure d'envoyer des données dès le début. Un autre effort est appelé MultiPath TCP. Ici, l'idée est que votre téléphone mobile dispose généralement à la fois d'une connexion Wi-Fi et d'une connexion cellulaire (4G), alors pourquoi ne pas les utiliser en même temps pour un débit et une robustesse supplémentaires ?
Il n'est pas très difficile de mettre en œuvre ces TCP. prolongements. Cependant, il est extrêmement difficile de les déployer réellement à l'échelle d'Internet. Parce que TCP est si populaire, presque chaque appareil connecté a sa propre implémentation du protocole à bord. Si ces implémentations sont trop anciennes, manquent de mises à jour ou sont boguées, les extensions ne seront pratiquement pas utilisables. En d'autres termes, toutes les implémentations doivent connaître l'extension pour qu'elle soit utile.
Ce ne serait pas vraiment un problème si nous ne parlions que des périphériques de l'utilisateur final (tels que votre ordinateur ou serveur Web) , car ceux-ci peuvent être relativement facilement mis à jour manuellement. Cependant, de nombreux autres périphériques se trouvent entre le client et le serveur qui ont également leur propre code TCP à bord (par exemple, les pare-feu, les équilibreurs de charge, les routeurs, les serveurs de mise en cache, les proxys, etc.).
Ces boîtes intermédiaires sont souvent plus difficiles à mettre à jour et parfois plus strictes dans ce qu'ils acceptent. Par exemple, si l'appareil est un pare-feu, il peut être configuré pour bloquer tout le trafic contenant des extensions (inconnues). En pratique, il s'avère qu'un nombre énorme de boîtiers de médiation actifs font certaines hypothèses sur TCP qui ne sont plus valables pour les nouvelles extensions. middlebox) Les implémentations TCP sont mises à jour pour utiliser réellement les extensions à grande échelle. On pourrait dire qu'il est devenu pratiquement impossible de faire évoluer TCP.
En conséquence, il était clair que nous aurions besoin d'un protocole de remplacement pour TCP, plutôt que d'une mise à niveau directe, pour résoudre ces problèmes. Cependant, en raison de la complexité des fonctionnalités de TCP et de leurs différentes implémentations, créer quelque chose de nouveau mais de meilleur à partir de zéro serait une entreprise monumentale. En tant que tel, au début des années 2010, il a été décidé de reporter ce travail.
Après tout, il y avait des problèmes non seulement avec TCP, mais aussi avec HTTP/1.1. Nous avons choisi de diviser le travail et d'abord de « réparer » HTTP/1.1, ce qui a conduit à ce qui est maintenant HTTP/2. Lorsque cela a été fait, le travail a pu commencer sur le remplacement de TCP, qui est maintenant QUIC. À l'origine, nous espérions pouvoir exécuter HTTP/2 directement sur QUIC, mais en pratique, cela rendrait les implémentations trop inefficaces (principalement en raison de la duplication des fonctionnalités).
Au lieu de cela, HTTP/2 a été ajusté dans quelques domaines clés pour le rendre compatible avec QUIC. Cette version modifiée a finalement été nommée HTTP/3 (au lieu de HTTP/2-over-QUIC), principalement pour des raisons de marketing et de clarté. En tant que tel, les différences entre HTTP/1.1 et HTTP/2 sont beaucoup plus importantes que celles entre HTTP/2 et HTTP/3.
Takeaway
La clé à retenir ici est que ce dont nous avions besoin n'était pas vraiment HTTP/3 , mais plutôt « TCP/2 »et nous avons obtenu HTTP/3 « gratuitement » dans le processus. Les principales fonctionnalités qui nous enthousiasment pour HTTP/3 (configuration de connexion plus rapide, moins de blocage de HoL, migration de connexion, etc.) proviennent vraiment toutes de QUIC.
Qu'est-ce que QUIC ?
Vous l'êtes peut-être. vous vous demandez pourquoi c'est important ? Qui se soucie de savoir si ces fonctionnalités sont en HTTP/3 ou QUIC ? Je pense que cela est important, car QUIC est un protocole de transport générique qui, tout comme TCP, peut et sera utilisé pour de nombreux cas d'utilisation en plus de HTTP et du chargement de pages Web. Par exemple, DNS, SSH, SMB, RTP, etc. peuvent tous s'exécuter sur QUIC. En tant que tel, examinons QUIC un peu plus en profondeur, car c'est ici que proviennent la plupart des idées fausses sur HTTP/3 que j'ai lues.
Une chose que vous avez peut-être entendue est que QUIC fonctionne encore par dessus un autre protocole, appelé User Datagram Protocol (UDP). C'est vrai, mais pas pour les raisons (de performance) que beaucoup de gens prétendent. Idéalement, QUIC aurait été un nouveau protocole de transport entièrement indépendant, s'exécutant directement sur IP dans la pile de protocoles montrée dans l'image que j'ai partagée ci-dessus.
Cependant, cela aurait conduit au même problème que nous avons rencontré en essayant de évoluer TCP : tous les appareils sur Internet devraient d'abord être mis à jour afin de reconnaître et d'autoriser QUIC. Heureusement, nous pouvons construire QUIC sur un autre protocole de couche de transport largement pris en charge sur Internet : UDP.
Le saviez-vous ?
UDP est le protocole de transport le plus simple possible. Il ne fournit vraiment aucune fonctionnalité, à part les soi-disant numéros de port (par exemple, HTTP utilise le port 80, HTTPS est sur 443 et DNS utilise le port 53). Il n'établit pas de connexion avec prise de contact et n'est pas non plus fiable : si un paquet UDP est perdu, il n'est pas automatiquement retransmis. L'approche « best effort » d'UDP signifie donc qu'elle est à peu près aussi performante que possible :
Il n'y a pas besoin d'attendre la poignée de main et il n'y a pas de blocage HoL. En pratique, UDP est principalement utilisé pour le trafic en direct qui se met à jour à un rythme élevé et souffre donc peu de perte de paquets car les données manquantes sont de toute façon rapidement obsolètes (par exemple, la vidéoconférence en direct et les jeux). Il est également utile pour les cas nécessitant un faible délai initial ; par exemple, les recherches de noms de domaine DNS ne devraient vraiment prendre qu'un seul aller-retour.
De nombreuses sources affirment que HTTP/3 est construit sur UDP en raison des performances. Ils disent que HTTP/3 est plus rapide car, tout comme UDP, il n'établit pas de connexion et n'attend pas les retransmissions de paquets. Ces affirmations sont fausses. Comme nous l'avons dit plus haut, UDP est utilisé par QUIC et donc HTTP/3 principalement parce que l'on espère que cela facilitera leur déploiement, car il est déjà connu et implémenté par (presque) tous les appareils sur Internet .
En plus d'UDP, QUIC réimplémente essentiellement presque toutes les fonctionnalités qui font de TCP un protocole si puissant et populaire (mais un peu plus lent). QUIC est absolument fiable, utilisant les accusés de réception des paquets reçus et les retransmissions pour s'assurer que les paquets perdus arrivent toujours. QUIC établit également toujours une connexion et a une poignée de main très complexe.
Enfin, QUIC utilise également ce qu'on appelle flow-control et congestion-control mécanismes qui empêchent un expéditeur de surcharger le réseau ou le destinataire, mais qui rendent également TCP plus lent que ce que vous pourriez faire avec UDP brut. L'essentiel est que QUIC implémente ces fonctionnalités d'une manière plus intelligente et plus performante que TCP. Il combine des décennies d'expérience de déploiement et les meilleures pratiques de TCP avec quelques nouvelles fonctionnalités de base. Nous discuterons de ces fonctionnalités plus en détail plus loin dans cet article. HTTP/3 n'est pas magiquement plus rapide que HTTP/2 simplement parce que nous avons échangé TCP contre UDP. Au lieu de cela, nous avons repensé et implémenté une version beaucoup plus avancée de TCP et l'avons appelée QUIC. Et parce que nous voulons rendre QUIC plus facile à déployer, nous l'exécutons sur UDP.
Les grands changements
Alors, comment QUIC améliore-t-il exactement TCP ? Qu'est-ce qui est si différent ? Il existe plusieurs nouvelles fonctionnalités et opportunités concrètes dans QUIC (données 0-RTT, migration de connexion, plus de résilience à la perte de paquets et aux réseaux lents) que nous aborderons en détail dans la prochaine partie de la série. Cependant, toutes ces nouveautés se résument essentiellement à quatre changements principaux :
- QUIC s'intègre profondément avec TLS.
- QUIC prend en charge plusieurs flux d'octets indépendants.
- QUIC utilise des identifiants de connexion.
- ]QUIC utilise des trames.
Regardons de plus près chacun de ces points.
Il n'y a pas de QUIC sans TLS
Comme mentionné, TLS (le protocole Transport Layer Security) est en responsable de la sécurisation et du cryptage des données envoyées sur Internet. Lorsque vous utilisez HTTPS, vos données HTTP en texte brut sont d'abord chiffrées par TLS, avant d'être transportées par TCP.
Le saviez-vous ?
Les détails techniques de TLS, heureusement, ne sont pas vraiment nécessaires ici ; vous avez juste besoin de savoir que le cryptage est effectué à l'aide de mathématiques assez avancées et de très grands nombres (premiers). Ces paramètres mathématiques sont négociés entre le client et le serveur lors d'une négociation cryptographique distincte spécifique à TLS. Tout comme la négociation TCP, cette négociation peut prendre un certain temps.
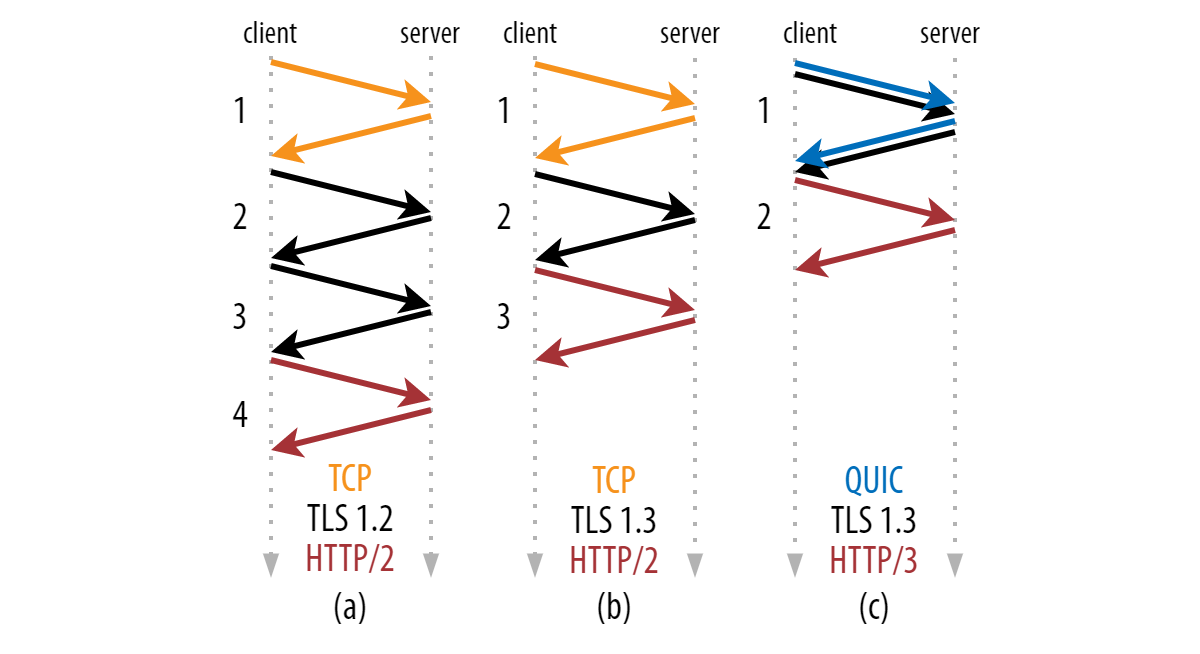
Dans les anciennes versions de TLS (par exemple, la version 1.2 et inférieure), cela prend généralement deux allers-retours réseau. Heureusement, les nouvelles versions de TLS (1.3 est la dernière) réduisent cela à un seul aller-retour. C'est principalement parce que TLS 1.3 limite sévèrement les différents algorithmes mathématiques qui peuvent être négociés à une poignée (les plus sécurisés). Cela signifie que le client peut immédiatement deviner ceux que le serveur prendra en charge, au lieu d'avoir à attendre une liste explicite, en économisant un aller-retour.

Au début d'Internet, le chiffrement du trafic était assez coûteux en termes de traitement. De plus, cela n'a pas non plus été jugé nécessaire pour tous les cas d'utilisation. Historiquement, TLS a donc été un protocole totalement distinct qui peut facultativement être utilisé au-dessus de TCP. C'est pourquoi nous faisons une distinction entre HTTP (sans TLS) et HTTPS (avec TLS).
Au fil du temps, notre attitude envers la sécurité sur Internet a bien sûr changé pour « sécurisé par défaut ”. En tant que tel, alors que HTTP/2 peut, en théorie, s'exécuter directement sur TCP sans TLS (et cela est même défini dans la spécification RFC comme cleartext HTTP/2), aucun navigateur Web (populaire) ne prend en charge cela. mode. D'une certaine manière, les fournisseurs de navigateurs ont fait un compromis conscient pour plus de sécurité au détriment des performances.
Compte tenu de cette évolution claire vers TLS toujours actif (en particulier pour le trafic Web), il n'est pas surprenant que les concepteurs de QUIC décidé de porter cette tendance au niveau supérieur. Au lieu de simplement ne pas définir de mode texte clair pour HTTP/3, ils ont choisi d'ancrer profondément le cryptage dans QUIC lui-même. Alors que les premières versions de QUIC spécifiques à Google utilisaient une configuration personnalisée pour cela, le QUIC standardisé utilise directement le TLS 1.3 existant lui-même.
Pour cela, il brise en quelque sorte la séparation nette typique entre les protocoles du protocole. stackcomme on peut le voir dans l'image précédente. Alors que TLS 1.3 peut toujours s'exécuter indépendamment sur TCP, QUIC encapsule en quelque sorte TLS 1.3. Autrement dit, il n'y a aucun moyen d'utiliser QUIC sans TLS ; QUIC (et, par extension, HTTP/3) est toujours entièrement crypté. De plus, QUIC crypte également presque tous ses champs d'en-tête de paquet ; Les informations de la couche de transport (telles que les numéros de paquet, qui ne sont jamais chiffrés pour TCP) ne sont plus lisibles par les intermédiaires dans QUIC (même certains des drapeaux d'en-tête de paquet sont chiffrés). TLS, QUIC crypte également ses métadonnées de couche de transport dans l'en-tête du paquet et la charge utile. (Remarque : les tailles de champ ne sont pas à l'échelle.) ( Grand aperçu)
Pour tout cela, QUIC utilise d'abord la poignée de main TLS 1.3 plus ou moins comme vous le feriez avec TCP pour établir les paramètres de chiffrement mathématiques. Après cela, cependant, QUIC prend le relais et crypte les paquets lui-même, alors qu'avec TLS-over-TCP, TLS effectue son propre cryptage. Cette différence apparemment minime représente un changement conceptuel fondamental vers un cryptage toujours actif qui est appliqué à des couches de protocole de plus en plus basses.
Cette approche offre à QUIC plusieurs avantages :
- QUIC est plus sécurisé pour ses utilisateurs.
Il existe aucun moyen d'exécuter QUIC en texte clair, il y a donc moins d'options pour les attaquants et les espions à écouter. (Des recherches récentes ont montré à quel point l'option de texte en clair de HTTP/2 peut être dangereuse .) - La configuration de la connexion de QUIC est plus rapide.
Alors que pour TLS-over-TCP, les deux protocoles ont besoin de leur propre poignées de main, QUIC combine à la place le transport et la poignée de main cryptographique en un seul, ce qui permet d'économiser un aller-retour (voir l'image ci-dessus). Nous en discuterons plus en détail dans la partie 2 (à venir bientôt !). - QUIC peut évoluer plus facilement.
Comme il est entièrement crypté, les boîtiers de médiation du réseau ne peuvent plus observer et interpréter son fonctionnement interne comme ils le peuvent avec TCP. Par conséquent, ils ne peuvent plus non plus se briser (accidentellement) dans les nouvelles versions de QUIC parce qu'ils n'ont pas réussi à se mettre à jour. Si nous voulons ajouter de nouvelles fonctionnalités à QUIC à l'avenir, nous devons « seulement » mettre à jour les terminaux, au lieu de tous les boîtiers de médiation.
À côté de ces avantages, cependant, il existe également des inconvénients potentiels à cryptage étendu :
- De nombreux réseaux hésiteront à autoriser QUIC.
Les entreprises peuvent vouloir le bloquer sur leurs pare-feu, car la détection du trafic indésirable devient plus difficile. Les FAI et les réseaux intermédiaires peuvent le bloquer car des métriques telles que les délais moyens et les pourcentages de perte de paquets ne sont plus facilement disponibles, ce qui rend plus difficile la détection et le diagnostic des problèmes. Tout cela signifie que QUIC ne sera probablement jamais disponible universellement, ce dont nous parlerons plus en détail dans la partie 3 (à venir bientôt !). - QUIC a une surcharge de chiffrement plus élevée.
QUIC chiffre chaque individu. paquet avec TLS, alors que TLS-over-TCP peut chiffrer plusieurs paquets en même temps. Cela rend potentiellement QUIC plus lent pour les scénarios à haut débit (comme nous le verrons dans la partie 2 (à venir bientôt !)). - QUIC rend le Web plus centralisé.
Une plainte que j'ai déposée. rencontré souvent est quelque chose comme « QUIC est poussé par Google parce qu'il leur donne un accès complet aux données tout en ne partageant rien avec les autres ». Je suis surtout en désaccord avec cela. Premièrement, QUIC ne cache pas plus (ou moins !) d'informations au niveau de l'utilisateur (par exemple, les URL que vous visitez) aux observateurs extérieurs que TLS-over-TCP (QUIC maintient le statu quo).
Deuxièmement, alors que Google a lancé le projet QUIC, les protocoles finaux dont nous parlons aujourd'hui ont été conçus par une équipe beaucoup plus large de l'Internet Engineering Task Force (IETF). Le QUIC de l'IETF est techniquement très différent du QUIC de Google. Pourtant, il est vrai que les membres de l'IETF proviennent principalement de grandes entreprises comme Google et Facebook et de CDN comme Cloudflare et Fastly. En raison de la complexité de QUIC, ce seront principalement les entreprises qui auront le savoir-faire nécessaire pour déployer correctement et efficacement, par exemple, HTTP/3 dans la pratique. Cela conduira probablement à une plus grande centralisation dans ces entreprises, ce qui est une réelle préoccupation. des entretiens techniques : pour s'assurer que davantage de personnes comprennent les détails du protocole et puissent les utiliser indépendamment de ces grandes entreprises.
À retenir
La clé à retenir ici est que QUIC est profondément crypté par par défaut. Cela améliore non seulement ses caractéristiques de sécurité et de confidentialité, mais contribue également à sa déployabilité et à son évolutivité. Cela rend le protocole un peu plus lourd à exécuter mais, en retour, permet d'autres optimisations, telles qu'un établissement de connexion plus rapide.
QUIC connaît plusieurs flux d'octets
La deuxième grande différence entre TCP et QUIC est un peu plus technique, et nous explorerons ses répercussions plus en détail dans la partie 2 (bientôt !). Pour l'instant, cependant, nous pouvons comprendre les principaux aspects d'une manière de haut niveau.
Le saviez-vous ?
Considérez d'abord que même une simple page Web est composée d'un certain nombre de fichiers et de ressources indépendants. Il y a HTML, CSS, JavaScript, images, etc. Chacun de ces fichiers peut être considéré comme un simple « blob binaire » – une collection de zéros et de uns interprétés d'une certaine manière par le navigateur.
Lors de l'envoi de ces fichiers sur le réseau, nous ne les transférons pas tous en même temps. Au lieu de cela, ils sont subdivisés en morceaux plus petits (généralement d'environ 1400 octets chacun) et envoyés en paquets individuels. En tant que tel, nous pouvons considérer chaque ressource comme étant un « flux d'octets » distinct, car les données sont téléchargées ou « diffusées » au fil du temps.
Pour HTTP/1.1, le processus de chargement des ressources est assez simple, car chaque fichier reçoit sa propre connexion TCP et est téléchargé intégralement. Par exemple, si nous avons les fichiers A, B et C, nous aurions trois connexions TCP. Le premier verrait un flux d'octets AAAA, le deuxième BBBB, le troisième CCCC (chaque répétition de lettre étant un paquet TCP). Cela fonctionne mais est également très inefficace car chaque nouvelle connexion a une certaine surcharge.
En pratique, les navigateurs imposent des limites au nombre de connexions simultanées pouvant être utilisées (et donc au nombre de fichiers pouvant être téléchargés en parallèle). — généralement, entre 6 et 30 par page chargée. Les connexions sont ensuite réutilisées pour télécharger un nouveau fichier une fois le précédent entièrement transféré. Ces limites ont finalement commencé à entraver les performances Web sur les pages modernes, qui chargent souvent plus de 30 ressources.
Améliorer cette situation était l'un des principaux objectifs de HTTP/2. Le protocole le fait en n'ouvrant plus une nouvelle connexion TCP pour chaque fichier, mais en téléchargeant les différentes ressources sur une seule connexion TCP. Ceci est réalisé en « multiplexer » les différents flux d'octets . C'est une façon élégante de dire que nous mélangeons les données des différents fichiers lors de leur transport. Pour nos trois fichiers d'exemple, nous obtiendrions une seule connexion TCP et les données entrantes pourraient ressembler à AABBCCAABBCC (bien que de nombreux autres schémas de commande soient possibles ). Cela semble assez simple et fonctionne en effet assez bien, rendant HTTP/2 généralement aussi rapide ou un peu plus rapide que HTTP/1.1, mais avec beaucoup moins de surcharge.
Regardons de plus près la différence :

Cependant, il y a un problème du côté TCP. Vous voyez, parce que TCP est un protocole beaucoup plus ancien et n'est pas conçu pour charger uniquement des pages Web, il ne connaît pas A, B ou C. En interne, TCP pense qu'il ne transporte qu'un seul fichier X , et il ne se soucie pas que ce qu'il considère comme XXXXXXXXXXXX soit en fait AABBCCAABBBCC au niveau HTTP. Dans la plupart des situations, cela n'a pas d'importance (et cela rend TCP assez flexible !), mais cela change lorsqu'il y a, par exemple, une perte de paquets sur le réseau.
Supposons que le troisième paquet TCP soit perdu (celui qui contient les premières données pour le fichier B), mais toutes les autres données sont livrées. TCP traite cette perte en retransmettant une nouvelle copie des données perdues dans un nouveau paquet. Cette retransmission peut cependant mettre un certain temps à arriver (au moins un RTT). Vous pourriez penser que ce n'est pas un gros problème, car nous voyons qu'il n'y a pas de perte pour les ressources A et C. En tant que tel, nous pouvons commencer à les traiter en attendant les données manquantes pour B, n'est-ce pas ?
Malheureusement, ce n'est pas le cas , car la logique de retransmission se produit au niveau de la couche TCP, et TCP ne connaît pas A, B et C ! TCP pense plutôt qu'une partie du fichier X unique a été perdue, et il estime donc qu'il doit empêcher le traitement du reste des données de X jusqu'à ce que le trou soit rempli. Autrement dit, alors qu'au niveau HTTP/2, nous savons que nous pourrions déjà traiter A et C, TCP ne le sait pas, ce qui rend les choses plus lentes qu'elles ne pourraient l'être . Cette inefficacité est un exemple du problème de « blocage en tête de ligne (HoL) ».
Résoudre le blocage HoL au niveau de la couche de transport était l'un des principaux objectifs de QUIC . Contrairement à TCP, QUIC est intimement conscient du fait qu'il multiplexe plusieurs flux d'octets indépendants. Il, bien sûr, ne sait pas qu'il transporte du CSS, du JavaScript et des images ; il sait juste que les flux sont séparés. En tant que tel, QUIC peut effectuer une détection de perte de paquets et une logique de récupération sur une base par flux.
Dans le scénario ci-dessus, il ne retiendrait que les données pour le flux B, et contrairement à TCP, il fournirait toutes les données pour A et C à la couche HTTP/3 dès que possible. (Ceci est illustré ci-dessous.) En théorie, cela pourrait conduire à des améliorations des performances. En pratique, cependant, l'histoire est beaucoup plus nuancée, comme nous le verrons dans la partie 2 (à venir bientôt !).

Nous pouvons voir que nous avons maintenant une différence fondamentale entre TCP et QUIC. C'est d'ailleurs aussi l'une des principales raisons pour lesquelles nous ne pouvons pas simplement exécuter HTTP/2 tel quel sur QUIC. Comme nous l'avons dit, HTTP/2 inclut également un concept d'exécution de plusieurs flux sur une seule connexion (TCP). En tant que tel, HTTP/2-over-QUIC aurait deux abstractions de flux différentes et concurrentes l'une sur l'autre.
Les faire fonctionner ensemble serait très complexe et sujet aux erreurs ; ainsi, l'une des principales différences entre HTTP/2 et HTTP/3 est que ce dernier supprime la logique de flux HTTP et réutilise les flux QUIC à la place. Comme nous le verrons dans la partie 2 (coming soon !), cependant, cela a d'autres répercussions sur la façon dont les fonctionnalités telles que le push de serveur, la compression d'en-tête et la hiérarchisation sont implémentées.
Takeaway
The Le point clé à retenir ici est que TCP n'a jamais été conçu pour transporter plusieurs fichiers indépendants sur une seule connexion. Parce que c'est exactement ce dont la navigation sur le Web a besoin, cela a conduit à de nombreuses inefficacités au fil des ans. QUIC résout ce problème en faisant de plusieurs flux d'octets un concept central au niveau de la couche de transport et en gérant la perte de paquets par flux.
QUIC prend en charge la migration de connexion
La troisième amélioration majeure de QUIC est le fait que les connexions peuvent rester actives plus longtemps.
Le saviez-vous ?
Nous utilisons souvent le concept de « connexion » lorsque nous parlons de protocoles Web. Cependant, qu'est-ce qu'une connexion exactement ? En règle générale, les gens parlent d'une connexion TCP une fois qu'il y a eu une poignée de main entre deux points de terminaison (par exemple, le navigateur ou le client et le serveur). C'est pourquoi UDP est souvent (un peu à tort) dit « sans connexion », car il ne fait pas une telle poignée de main. However, the handshake is really nothing special: It’s just a few packets with a specific form being sent and received. It has a few goals, main among them being to make sure there is something on the other side and that it’s willing and able to talk to us. It’s worth repeating here that QUIC also performs a handshake, even though it runs over UDP, which by itself doesn’t.
So, the question becomes, how do those packets arrive at the correct destination? On the Internet, IP addresses are used to route packets between two unique machines. However, just having the IPs for your phone and the server isn’t enough, because both want to be able to run multiple networked programs at each end simultaneously.
This is why each individual connection is also assigned a port number on both endpoints to differentiate connections and the applications they belong to. Server applications typically have a fixed port number depending on their function (for example ports 80 and 443 for HTTP(S), and port 53 for DNS), while clients usually choose their port numbers (semi-)randomly for each connection.
As such, to define a unique connection across machines and applications, we need these four things, the so-called 4-tuple: client IP address + client port + server IP address + server port.
In TCP, connections are identified by just the 4-tuple. So, if just one of those four parameters changes, the connection becomes invalid and needs to be re-established (including a new handshake). To understand this, imagine the parking-lot problem: You are currently using your smartphone inside of a building with Wi-Fi. As such, you have an IP address on this Wi-Fi network.
If you now move outside, your phone might switch to the cellular 4G network. Because this is a new network, it will get a completely new IP address, because those are network-specific. Now, the server will see TCP packets coming in from a client IP that it hasn’t seen before (although the two ports and the server IP could, of course, stay the same). This is illustrated below.

But how can the server know that these packets from a new IP belong to the “connection”? How does it know these packets don’t belong to a new connection from another client in the cellular network that chose the same (random) client port (which can easily happen)? Sadly, it cannot know this.
Because TCP was invented before we were even dreaming of cellular networks and smartphones, there is, for example, no mechanism that allows the client to let the server know it has changed IPs. There isn’t even a way to “close” the connection, because a TCP reset or fin command sent to the old 4-tuple wouldn’t even reach the client anymore. As such, in practice, every network change means that existing TCP connections can no longer be used.
A new TCP (and possibly TLS) handshake has to be executed to set up a new connection, and, depending on the application-level protocol, in-process actions would need to be restarted. For example, if you were downloading a large file over HTTP, then that file might have to be re-requested from the start (for example, if the server doesn’t support range requests). Another example is live video conferencing, where you might have a short blackout when switching networks.
Note that there are other reasons why the 4-tuple might change (for example, NAT rebinding), which we’ll discuss more in part 2 (coming soon!).
Restarting the TCP connections can thus have a severe impact (waiting for new handshakes, restarting downloads, re-establishing context). To solve this problem, QUIC introduces a new concept named the connection identifier (CID). Each connection is assigned another number on top of the 4-tuple that uniquely identifies it between two endpoints.
Crucially, because this CID is defined at the transport layer in QUIC itself, it doesn’t change when moving between networks! This is shown in the image below. To make this possible, the CID is included at the front of each and every QUIC packet (much like how the IP addresses and ports are also present in each packet). (It’s actually one of the few things in the QUIC packet header that aren’t encrypted!)

With this set-up, even when one of the things in the 4-tuple changes, the QUIC server and client only need to look at the CID to know that it’s the same old connection, and then they can keep using it. There is no need for a new handshake, and the download state can be kept intact. This feature is typically called connection migration. This is, in theory, better for performance, but, as we will discuss in part 2 (coming soon!), it’s, of course, a nuanced story again.
There are other challenges to overcome with the CID. For example, if we would indeed use just a single CID, it would make it extremely easy for hackers and eavesdroppers to follow a user across networks and, by extension, deduce their (approximate) physical locations. To prevent this privacy nightmare, QUIC changes the CID every time a new network is used.
That might confuse you, though: Didn’t I just say that the CID is supposed to be the same across networks? Well, that was an oversimplification. What really happens internally is that the client and server agree on a common list of (randomly generated) CIDs that all map to the same conceptual “connection”.
For example, they both know that CIDs K, C, and D in reality all map to connection X. As such, while the client might tag packets with K on Wi-Fi, it can switch to using C on 4G. These common lists are negotiated fully encrypted in QUIC, so potential attackers won’t know that K and C are really X, but the client and server would know this, and they can keep the connection alive.

It gets even more complex, because clients and servers will have different lists of CIDs that they choose themselves (much like they have different port numbers). This is mainly to support with routing and load balancing in large-scale server set-ups, as we’ll see in more detail in part 3 (coming soon!).
Takeaway
The key takeaway here is that in TCP, connections are defined by four parameters that can change when endpoints change networks. As such, these connections sometimes need to be restarted, leading to some downtime. QUIC adds another parameter to the mix, called the connection ID. Both the QUIC client and server know which connection IDs map to which connections and are thus more robust against network changes.
QUIC Is Flexible and Evolvable
A final aspect of QUIC is that it’s specifically made to be easy to evolve. This is accomplished in several different ways. First, as discussed, the fact that QUIC is almost fully encrypted means that we only need to update the endpoints (clients and servers), and not all middleboxes, if we want to deploy a newer version of QUIC. That still takes time, but typically in the order of months, not years.
Secondly, unlike TCP, QUIC does not use a single fixed packet header to send all protocol meta data. Instead, QUIC has short packet headers and uses a variety of “frames” (kind of like miniature specialized packets) inside the packet payload to communicate extra information. There is, for example, an ACK frame (for acknowledgements), a NEW_CONNECTION_ID frame (to help set up connection migration), and a STREAM frame (to carry data), as shown in the image below.
This is mainly done as an optimization, because not every packet carries all possible meta data (and so the TCP packet header usually wastes quite some bytes — see also the image above). A very useful side effect of using frames, however, is that defining new frame types as extensions to QUIC will be very easy in the future. A very important one, for example, is the DATAGRAM framewhich allows unreliable data to be sent over an encrypted QUIC connection.

Thirdly, QUIC uses a custom TLS extension to carry what are called transport parameters. These allow the client and server to choose a configuration for a QUIC connection. This means they can negotiate which features are enabled (for example, whether to allow connection migration, which extensions are supported, etc.) and communicate sensible defaults for some mechanisms (for example, maximum supported packet size, flow control limits). While the QUIC standard defines a long list of these, it also allows extensions to define new ones, again making the protocol more flexible.
Lastly, while not a real requirement of QUIC by itself, most implementations are currently done in “user space” (as opposed to TCP, which is usually done in “kernel space”). The details are discussed in part 2 (coming soon!), but this mainly means that it’s much easier to experiment with and deploy QUIC implementation variations and extensions than it is for TCP.
Takeaway
While QUIC has now been standardized, it should really be regarded as QUIC version 1 (which is also clearly stated in the Request For Comments (RFC)), and there is a clear intent to create version 2 and more fairly quickly. On top of that, QUIC allows for the easy definition of extensions, so even more use cases can be implemented.
Conclusion
Let’s summarize what we’ve learned in this part. We have mainly talked about the omnipresent TCP protocol and how it was designed in a time when many of today’s challenges were unknown. As we tried to evolve TCP to keep up, it became clear this would be difficult in practice, because almost every device has its own TCP implementation on board that would need to be updated.
To bypass this issue while still improving TCP, we created the new QUIC protocol (which is really TCP 2.0 under the hood). To make QUIC easier to deploy, it is run on top of the UDP protocol (which most network devices also support), and to make sure it can evolve in the future, it is almost entirely encrypted by default and makes use of a flexible framing mechanism.
Other than this, QUIC mostly mirrors known TCP featuressuch as the handshake, reliability, and congestion control. The two main changes besides encryption and framing are the awareness of multiple byte streams and the introduction of the connection ID. These changes were, however, enough to prevent us from running HTTP/2 on top of QUIC directly, necessitating the creation of HTTP/3 (which is really HTTP/2-over-QUIC under the hood).
QUIC’s new approach gives way to a number of performance improvements, but their potential gains are more nuanced than typically communicated in articles on QUIC and HTTP/3. Now that we know the basics, we can discuss these nuances in more depth in the next part of this series. Stay tuned!
Source link