Stratégies pour des projets sans tête avec des systèmes de gestion de contenu structurés
À propos de l'auteur
Knut Melvær est un technologue en sciences humaines qui travaille actuellement en tant que promoteur auprès de de Sanity.io . Il a déjà été consultant en technologie et développeur chez… Pour en savoir plus sur Knut
L'utilisation d'un système de gestion de contenu structuré (SCMS) peut être un excellent moyen de libérer votre contenu d'un paradigme qui commence à sentir son âge. Dans cet article, Knut Melvær propose des stratégies globales, avec des exemples concrets concrets sur la manière de réfléchir à l'utilisation de contenu structuré.
C’est le guide que j’aurais aimé avoir ces deux dernières années lors de l’exécution de projets avec des systèmes de gestion de contenu (SGC) sans tête. J'ai été développeur, consultant en expérience utilisateur et en technologie, chef de projet, architecte de l'information et auteur. Les différents chapeaux m'ont fait comprendre que même si nous avions depuis quelque temps déjà des systèmes de gestion de contenu sans tête, il y a encore du chemin à faire pour réfléchir à la meilleure façon de les utiliser.
Nous sommes maintenant à un endroit où nous sommes nombreux à nous appuyer sur des frameworks JavaScript pour les travaux frontaux, utilisant des systèmes de conception composés de composants et de compositions, plutôt que de simplement mettre en œuvre des dispositions de page plates. Les applications JAMstacks et les applications isomorphes / universelles fonctionnant à la fois sur le serveur et sur le client sont très populaires. La dernière pièce du puzzle est donc la manière dont nous gérons tout le contenu.
Les CMS traditionnels ajoutent des API pour servir le contenu via des requêtes réseau et le format JSON. En outre, des systèmes de gestion de contenu «sans tête» ont été créés pour servir exclusivement le contenu via des API. Mon argument dans cet article, cependant, est que nous devrions passer moins de temps à parler de "sans tête" et davantage à "de contenu structuré" . Parce que c'est la qualité essentielle de ces systèmes. Ces systèmes impliquent de nombreuses implications pour notre métier, et nous avons encore du chemin à faire pour déterminer les bons schémas de gestion de ces technologies.
Venir à la consultation en technologie après avoir acquis une formation en sciences humaines. , J'ai beaucoup appris sur la façon d'organiser et de travailler avec des projets Web qui adoptent une approche centrée sur le contenu – à la fois avec les nouveaux systèmes de gestion basés sur API et les systèmes de gestion de contenu traditionnels. Je suis venu pour comprendre comment commencer tôt avec le contenu réel en direct d'un CMS; cela dans un contexte interdisciplinaire a non seulement permis de cerner plus tôt les complexités, mais également de donner du pouvoir à toutes les personnes concernées et de donner une occasion de réfléchir aux défis et aux possibilités de la technologie et de la conception au sens le plus large. [19659008] WordPress sans tête
Tout le monde sait que si un site Web est lent, les utilisateurs l'abandonnent. Examinons de plus près les bases de la création d’un WordPress découplé. Lire l'article →
Dans cet article, je vais suggérer des stratégies globales, avec des exemples concrets et concrets sur la manière de réfléchir à l'utilisation d'un contenu structuré. Au moment de la rédaction de ce document, je viens de commencer à travailler pour une société de logiciels-services offrant un tel service de gestion de contenu, pour l'hébergement de contenu transmis via des API. J'y ferai référence, à la fois en raison de mon expérience passée dans des projets auxquels j'ai participé en tant que consultant, mais aussi parce que je pense que cela illustre bien ce que je veux dire. Donc, considérez ceci comme une clause de non-responsabilité.
Cela étant dit, je réfléchis à la rédaction de cet article depuis quelques années et je me suis efforcé de le rendre applicable à la plate-forme de votre choix. Donc, sans plus tarder, remontons vingt ans en arrière pour mieux comprendre où nous en sommes aujourd’hui.
First Moves With Web Standards
In Au début des années 2000, le mouvement des standards Web a incité un domaine à changer leurs méthodes de travail. Depuis l’approche «mise en page d’abord», ils ont dirigé notre attention sur la manière dont le contenu d’une page devrait être balisé de manière sémantique avec HTML: le menu d’un site Web n’est pas un
c’est un ; Une position n’est pas un c’est un . Il s'agissait d'une étape importante dans la réflexion sur les différents rôles que le contenu Web joue pour aider les utilisateurs à le trouver, à l'identifier et à le prendre en charge.
Le mouvement des normes Web a présenté l'argument selon lequel le balisage sémantique améliore l'accessibilité, ainsi que son classement dans les Résultats de recherche Google. Cela a également marqué un changement de perception du contenu Web . Votre site Web n’est plus l’endroit uniquement pour lequel votre contenu est représenté. Vous deviez également réfléchir à la manière dont vos pages Web étaient présentées dans d'autres contextes visuels, tels que les résultats de recherche ou les lecteurs d'écran. Cela a ensuite été alimenté par les médias sociaux et les aperçus intégrés de liens partagés. La mentalité est passée de la façon dont le contenu devrait ressembler à à la signification de . Cela s'avère également être la clé pour travailler avec un contenu structuré.
Avec l'adoption d'appareils de poche connectés à Internet, le Web a soudainement pris un sérieux concurrent dans les applications. La compétition, cependant, était principalement pour les yeux de l'utilisateur final. De nombreuses entreprises devaient encore diffuser des informations sur leurs produits et services à la fois dans leurs applications et sur leurs différentes présences Web. Parallèlement, le Web a mûri et JavaScript et AJAX ont facilité la connexion de différentes sources de contenu via des API. Aujourd'hui, nous avons GraphQL et des outils qui simplifient l'extraction du contenu et la gestion des états. Ainsi, les éléments du puzzle technologique commencent à se mettre en place.
«Créer une fois, publier partout»
Bien qu'il soit généralement décrit comme un «changement technologique», l'intégration de contenu dans des charges utiles JSON (voyageant dans des tubes HTTP ) a un impact démesuré sur la manière dont nous pensons au contenu numérique et aux flux de travail environnants. À certains égards, il l'a déjà fait. Il y a près de dix ans, l’invité Daniel Jacobson de la National Public Radio (NPR) a blogué sur programmableweb.com sur leur approche, résumée dans l’acronyme COPE, qui signifie «Créer une fois, publier partout». Dans cet article, il présente un système de gestion de contenu fournissant du contenu à plusieurs interfaces numériques via une API – et non via une machine de rendu HTML – comme le faisaient la plupart des CMS à l'époque (et sans doute maintenant).
Illustration du système COPE de NPR. Publié à l'origine sur programmableweb.com (13 oct 2009) ( Grand aperçu )
La "couche de gestion des données" COPE de NPR est ce qui deviendrait la notion de "CMS sans tête". Aux débuts de COPE, cela avait été réalisé en structurant le contenu en XML. Aujourd'hui, JSON est devenu le format de données dominant pour le transfert de données via des API, y compris des dispositifs pour l'Internet des objets et d'autres systèmes en dehors du Web. Si vous souhaitez échanger du contenu avec des chatbots, des interfaces vocales et même des logiciels de prototypage visuel, vous parlez souvent de HTTP avec un accent JSON.
«Uncoining» Le terme «CMS sans tête»
D'après Google Trends la recherche d'un «CMS sans tête» a gagné en popularité jusqu'en 2015, soit six ans après l'article de NPR dans COPE. Le terme «sans tête» (du moins en ce qui concerne la technologie numérique et non l'aristocratie française de la fin du XVIIIe siècle) a été utilisé pendant un bon bout de temps pour parler de systèmes fonctionnant sans interface utilisateur graphique.
Remarque : On pourrait soutenir qu'une interface de ligne de commande est en effet "graphique", telle qu'un logiciel sur des serveurs ou des environnements de test (mais gardons cela pour un autre article).
Deux esprits m'appellent ces nouveaux CMS "sans tête". Nous pourrions aussi bien les appeler « polycephalic » – celui qui a plusieurs têtes. Ce sont les Hydras et Cerbeuses des CMS. "Headless" définit également ces systèmes par la capacité qui leur fait défaut (par exemple, un moteur de template pour le rendu des pages Web), au lieu de les définir par leur véritable force: rendre possible la structuration du contenu sans les contraintes du Web. Cela dit, à compter d’aujourd’hui, bon nombre des solutions de cette catégorie pourraient également être appelées « Nick sans tête ». Parce que l'interface d'édition est toujours étroitement liée au système. Leur "décapitation" provient de l'absence de moteur de gabarit, c'est-à-dire des machines produisant des balises à partir du contenu.
Note : J'utiliserais presque certainement un CMS appelé "Mimsy-Porpington". (connu de l'univers Harry Potter) cependant.
Au lieu de cela, ils rendent le contenu disponible via une API, vous donnant ainsi plus de flexibilité pour savoir comment, quoi et où vous voulez afficher et utiliser ce contenu. Cela en fait des compagnons parfaits des frameworks frontend JavaScript populaires tels que React, Angular et Vue. Et malgré la prétention de pouvoir fournir du contenu à «des sites Web, des applications et des appareils», la plupart d’entre eux sont toujours limités par le fonctionnement du contenu Web. Cela se remarque surtout dans la manière dont la plupart des textes enrichis sont gérés – stockés au format HTML ou Markdown.
Les CMS traditionnels ont également commencé à ajouter des API génériques en plus de leurs systèmes de rendu de gabarit et appellent cela «découplé» afin de distinguer eux-mêmes de leurs nouveaux concurrents. «Tout cela, et les API aussi!» * Est l’affirmation. Certains de ces CMS sont également assez agnostiques en ce qui concerne la modélisation du contenu. Par exemple, Craft CMS, ne fait pratiquement aucune hypothèse concernant votre modèle de contenu lors de sa première installation. WordPress s'oriente également vers l'utilisation d'API pour la diffusion de contenu. Je pense que l'écart entre les anciens acteurs du système de gestion de contenu et le nouveau va se réduire à mesure que nous progressons.
Néanmoins, placer la gestion du contenu derrière des API (au lieu d'un moteur de rendu HTML) est une étape importante vers des méthodes de travail plus sophistiquées. à une époque où le texte, les images, les vidéos et les médias d'une entreprise sont numérisés et exposés aux utilisateurs et aux clients internes et externes. Cependant, il est temps de ne plus définir leurs capacités de rendu frontales manquantes, mais plutôt ce qu’ils peuvent réellement faire pour nous: nous donner le moyen de travailler avec du contenu structuré . Alors, devrions-nous les appeler «systèmes de gestion de contenu structuré»? Comme dans «No Bob, ce n’est pas votre CMS habituel. C'est un SCMS, croyez-moi, ce sera une chose. ”
Il ne s'agit pas de têtes, mais de contenu structuré
Le changement le plus radical que le système de gestion de contenu structuré (SCMS) impose s'éloigne de l'organisation du contenu en fonction d'une hiérarchie de pages à l'endroit où vous êtes libre de structurer le contenu à votre guise. Éviter le contenu en double est un avantage évident, car il augmente la fiabilité et réduit le fardeau administratif (vous n’avez pas à gérer le contenu dupliqué sur plusieurs canaux). En d'autres termes: Créer une fois, publier partout . Si vous devez simplement mettre à jour votre description de produit une fois, dans un système, à chaque fois que votre produit est exposé à l'utilisateur, c'est clairement un avantage.
Les fournisseurs de SCMS utilisent fréquemment «votre site Web et une application» pour justifier leur réflexion. différemment sur la structure de la page, il n’est pas nécessaire de traverser la rivière pour tirer parti d’une structure de contenu structurée. Avec la popularité des frameworks JavaScript, il est de plus en plus courant de créer des sites Web sous forme de composition de composants individuels pouvant être «remplis» avec un contenu différent en fonction de l'état et du contexte. Vous pouvez avoir une carte produit qui apparaît dans de nombreux contextes différents au sein de votre application Web. Nous constatons que le développement Web moderne s'éloigne de la création de documents et de pages pour composer des composants en combinant saisie utilisateur, algorithmes et personnalisation.
Ces tendances relatives à la manière dont les systèmes de conception sont conçus et encouragés à travailler sont encouragées. En équipes, au travers de processus de test, d'apprentissage et d'itération, le domaine de la gestion de contenu est mûr pour de nouvelles façons de penser. Certains schémas sont apparus, mais nous avons encore beaucoup de chemin à parcourir. Par conséquent, sur la base de mon expérience de travail dans des équipes et des projets qui ont mis le contenu à l'avant-plan, et en tant que membre d'une équipe qui crée un service pour cela (et je vous prie instamment de prendre conscience de tout parti pris ici), je souhaite Je propose des stratégies qui, à mon avis, peuvent être utiles et créent des points de discussion supplémentaires.
1. Approche du contenu dans des équipes multidisciplinaires
Je pense qu'il est du passé qu'un graphiste puisse remettre des pages obsolètes et parfaitement parfaites à un développeur front-end chargé de «mettre en œuvre» le design. Nous fabriquons maintenant des systèmes de conception constitués de composants plus petits, répartis dans des compositions livrables avec de multiples états possibles. Le plus souvent, ces composants doivent être résilients aux données générées par l'utilisateur. Autrement dit, plus tôt vous introduirez du contenu en direct dans le processus, mieux ce sera. La responsabilité du développeur frontal n’est pas de reproduire la vision du designer graphique ; il s'agit de manœuvrer un champ complexe de la façon dont les navigateurs affichent le HTML, le CSS et le JavaScript, en s'assurant que les interfaces utilisateur sont réactives, accessibles et performantes.
Lorsque vous travaillez en tant que consultant en technologie chez Netlife (un cabinet de conseil spécialisée dans l’expérience utilisateur), j’ai vu de grands progrès dans la collaboration entre développeurs, concepteurs et chercheurs utilisateurs. Même si nos éditeurs de contenu ont toujours été associés au projet dès le départ, leurs contributions ne sont pas entrées dans le processus de conception principalement en raison de frictions techniques.
Le goulot d'étranglement était souvent un héritage du CMS que nous ne pouvions pas toucher, ou qu'il Il a fallu du temps pour construire la structure de contenu car elle dépendait de la présentation. Cela doublait souvent le travail. Nous avons créé un prototype HTML, souvent basé sur du contenu analysé à partir de fichiers Markdown, qui a dû être ré-implémenté dans la pile du CMS lors du test utilisateur, et tout le monde était heureux au pixel près. . Ce processus était souvent coûteux car des limitations dans le système de gestion de contenu ont été découvertes tardivement. Cela crée également une pression sur toutes les parties pour «réussir du premier coup» et laisse moins d'espace pour le type d'expérimentation souhaité dans un projet de conception.
Le travail multidisciplinaire nécessite des systèmes agiles
Passage vers un SCMS. dans lequel il fallait quelques minutes pour coder un modèle de contenu (où les champs et les API étaient prêts instantanément) bouleversait notre processus – et pour le mieux. Je me souviens d’être assis avec l’éditeur de contenu du nouveau u4.no dans les premiers jours du projet. Parler de la façon dont ils ont travaillé et aimeraient travailler avec leur contenu. Assez rapidement, nous avons traduit nos conclusions en objets JavaScript simples, qui ont été instantanément transformés en un environnement d’édition dans le navigateur. Trouver des titres utiles et des descriptions pour les titres. Nous avons expliqué comment ils souhaitaient que les extraits de texte puissent être réutilisés dans différentes pages et différents contextes, qu'ils appelaient en interne des «pépites», que nous avons ensuite créées à ce moment-là.
Permettant ce type d'exploration au tout début du développement du projet. – Un éditeur de contenu et un développeur discutant lors de la création de l'interface devant nous – se sentaient puissants. Sachant que nous pourrions continuer à concevoir l'interface dans React pendant que ses collègues et elle ont commencé à travailler avec le contenu. Et ne vous inquiétez pas de vous mettre dans un coin, comme nous le faisions souvent avec les CMS dans lesquels la structure était étroitement liée à la façon dont vous deviez coder la partie frontale de celle-ci.
Un système de contenu doit permettre l'expérimentation et l'itération
Mis à part les projets de refonte des créations, un système pour le contenu structuré doit également vous permettre de continuer à améliorer, tester et itérer votre contenu dans l'ensemble de votre système de conception. Les concepteurs UX devraient être capables de prototyper rapidement avec du contenu réel à l'aide d'outils tels que Sketch ou Framer X. Vous devriez pouvoir augmenter la gestion de contenu avec des mesures quantitatives, qu'il s'agisse d'échelles de lisibilité ou de la performance du contenu à l'endroit de son utilisation.
Note : J'ai utilisé le terme «concepteurs UX» ci-dessus en dépit de l'opinion selon laquelle nous devrions tous, d'une certaine manière, être associés au processus permettant de créer de bonnes expériences utilisateur. Nous sommes tous des concepteurs UX dans nos différents domaines de conception.
Exemple d’analyse de lisibilité quantitative dans un éditeur de texte enrichi. ( Grand aperçu )
Travailler avec du contenu structuré demande un peu d’habitude, même si vous êtes habitué à utiliser du contenu WYSIWYG directement sur votre mise en page Web. Pourtant, cela se prête à une conversation plus en phase avec l'évolution du domaine de la conception numérique. Le contenu structuré permet à une équipe de concepteurs, de développeurs, d’éditeurs de contenu, de chercheurs utilisateurs et de chefs de projet de réfléchir collectivement à la manière dont un système doit fonctionner pour répondre aux besoins et aux objectifs stratégiques des utilisateurs. Cela nécessite également que vous réfléchissiez différemment à la structure du contenu, ce qui nous amène à la stratégie suivante.
2. Vous n'avez peut-être pas besoin d'un ordre hiérarchique
L'un des changements les plus remarquables pour beaucoup est que les systèmes de contenu structuré sont axés sur les collections et les listes de documents et non sur des hiérarchies de type dossier qui reflètent les structures de navigation des sites Web. Ces structures cessent d'avoir du sens dès lors qu'une partie du contenu doit être utilisée dans d'autres contextes – qu'il s'agisse de chatbots, de médias imprimés ou d'autres sites Web. Les CMS traditionnels ont tenté de limiter ce problème en autorisant les blocs de contenu réutilisables, mais ils doivent tout de même être placés dans les présentations de page et être difficiles à gérer avec des API.
Contenu basé sur des dossiers gestion dans Episerver. Cette capture n’est pas ancienne au fait. Publié sur episerver.com. ( Grand aperçu )
Chaque page est distincte
Comme indiqué dans Le modèle de base lorsqu'un de vos référents principaux est Google ou partagé sur des réseaux sociaux, vous devez considérer chaque page comme une page de renvoi. Et si vous regardez la répartition des pages vues, vous remarquerez que certaines de vos pages sont beaucoup plus populaires que d’autres. À moins que vous ne soyez un site Web d'actualités, il ne s'agit généralement pas d'actualités, mais de celles qui permettent à l'utilisateur de réaliser tout ce qu'il espérait réaliser sur votre site Web. C'est là que les affaires se déroulent réellement.
Votre contenu numérique doit être au service de l'intersection de vos propres objectifs stratégiques et de ceux de vos utilisateurs. Lorsque l'agence numérique Bengler (prédécesseur de sanity.io ) a créé le nouveau site Web de oma.eu elle n'a pas structuré le contenu après un exposé détaillé. hiérarchie des pages. Ils ont créé des types de contenu reflétant la réalité quotidienne de l’organisation, c’est-à-dire après les projets personnes et les publications . En fait, la hiérarchie du contenu du site Web de l'OMA est presque uniforme, et la page de couverture est générée à partir d'un ensemble de règles algorithmiques et éditoriales.
Comment sanity.io structure leur contenu ( Grand aperçu )
Alors, comment s'y prendre? Je pense que votre conception de votre contenu doit refléter à la fois le modèle mental de votre organisation et ce qui doit être pour être utile aux besoins de vos utilisateurs.
Voici un exemple élémentaire: lors de la création d'une page d'employés, vous devriez probablement commencer avec un type de contenu appelé personne . Une personne de peut avoir un nom, des coordonnées, une image, différents rôles organisationnels et une courte biographie. Un document personnel peut être réutilisé dans des listes de contacts, des signatures d'auteur, des interfaces de support de chat et la création de badges d'accès. Peut-être avez-vous déjà un système interne qui sait qui sont ces personnes et qui est fourni avec une API? Parfait, alors synchronisez-vous avec cela.
Ne vous perdez pas dans un trou de lapin ontologique
Il est utile de revenir à la manière dont Google indexe les pages Web et essaie d’indexer l’information du monde. C’est pourquoi ils consacrent du temps et des efforts aux données liées (RDFa, microformat, JSON-LD ). Si vous annotez vos pages Web avec des éléments JSON-LD, vos résultats de recherche apparaîtront mieux. Il est également pertinent que vos informations soient prononcées par des assistants vocaux et affichées dans une interface utilisateur auxiliaire. Si votre contenu est déjà structuré et facilement disponible dans une API, il vous sera relativement facile de l'implémenter dans ces microformats.
Je ne suis pas sûr que je recommanderais d'aller de bout en bout sur les ontologies du schéma . org et diverses ressources de données liées cependant, du moins pas à des fins d'édition. Vous pouvez rapidement vous perdre dans un trou de lapin en essayant de créer des structures platoniques parfaites.
Newsflash : Cela ne se fera jamais, parce que le monde est désordonné et que les gens Pensez différemment.
Il est plus important de structurer votre contenu dans un système intuitif qui se prête à une adaptation en fonction de l'évolution des besoins. C'est pourquoi il est important de commencer avec la modélisation du contenu dès le début du processus de conception et de développement – vous devez en apprendre plus sur son utilisation.
Résumé D'après la réalité, pas d'après les conventions de la CMS
Il peut être tentant de Suivez simplement les conventions de votre CMS. N'oubliez pas que WordPress vous communiquera des «messages» et des «pages», et que tout doit être inséré dans ces cases. Un champ de texte enrichi WYSIWYG est flexible en ce sens qu’il vous permet d’insérer n'importe quoi, mais le contenu ne sera pas structuré et facilement adaptable – il n’est flexible qu’une seule fois. Mais vous avez besoin d’un endroit pour commencer à mapper un modèle de contenu. Ma suggestion est de commencer par parler aux gens, c'est-à-dire aux auteurs et aux lecteurs.
Comment les gens parlent-ils du contenu en interne? Qu'est-ce que les gens appellent des choses différentes? Vous pouvez organiser un exercice gratuit une méthode utilisée par les ethnographes pour cartographier les taxonomies folkloriques. Par exemple, vous pouvez demander:
«Nommez les différents types de contenu dans notre organisation».
Ou, à un niveau plus spécifique:
«Pouvez-vous nommer les différents types de rapports que nous avons dans cette organisation? ? ”
Le but de cette enquête est de démêler les taxonomies intériorisées des gens, et non leurs opinions ou sentiments au sujet de choses (quelque chose qui tend souvent à faire dérailler les processus de conception). Il n’est pas nécessaire d’en demander beaucoup avant d’avoir une liste assez exhaustive sur laquelle vous pouvez travailler. Vous constaterez probablement que certaines parties de votre liste proviennent des conventions de votre système de gestion de contenu actuel (il est bon de savoir si vous devez effectuer des rénovations). Maintenant, vous devriez parler avec votre éditeur et essayer de définir ce qu’il a besoin du contenu .
Voici quelques questions que vous pouvez poser:
Devez-vous utiliser ce contenu dans plus d'un endroit? Où?
Quelles sont les relations différentes entre les types de contenu?
Où devons-nous afficher le contenu aujourd'hui et demain?
De quelle manière avons-nous besoin que le contenu soit trié? La commande peut-elle être effectuée de manière algorithmique, par l'utilisateur, ou doit-elle être manuelle?
Existe-t-il des systèmes ou des bases de données dans lesquels nous pouvons nous synchroniser pour éviter les doubles emplois?
Où voulons-nous le contenu canonique? content de vivre? Le SCMS doit-il en être la source ou simplement augmenter le contenu existant, par ex. Une copie marketing pour des produits installés dans un système de gestion de produits?
Cela ne veut pas dire que vous devez rejeter l’architecture d’information traditionnelle avec l’eau de bain maintenant tiède. Il est toujours logique d’utiliser les articles comme type de contenu, si ceux-ci font partie de la réalité du contenu de votre organisation. Mais vous n’avez peut-être pas vraiment besoin de la convention abstraite des catégories car ces articles font référence au type de produits ou qui y figurent. Et cette relation permet d'interroger ces articles dans des circonstances où cela a du sens, sans exiger de quelqu'un qu'il ait une «gestion de catégorie d'article» dans sa description de travail.
L'article de est également ce qui rend difficile la dissocier complètement le contenu de la couche de présentation. Nous sommes tellement habitués à penser à la mise en page et au style de l'article, mais à une époque où vous êtes censé héberger votre propre contenu sur votre propre domaine, puis le syndiquer sur des plates-formes telles que medium.com, vous avez déjà abandonné contrôle de la présentation visuelle. Cela nous amène à la stratégie suivante.
3. Les contextes de présentation sont également des types de contenu
Soyez prêt à la refonte
Vous souhaitez également pouvoir adapter et modifier rapidement la structure de navigation de votre site Web, sans avoir à reconstruire la totalité de votre architecture de contenu ni à lutter contre un dossier rigoureux. comme interface. Vous souhaitez également pouvoir définir une hiérarchie de contenu, car cela a parfois du sens et dépasse parfois deux niveaux, où la plupart des interfaces du service des premiers CMSs avec API ne parviennent pas à fournir beaucoup d'aide.
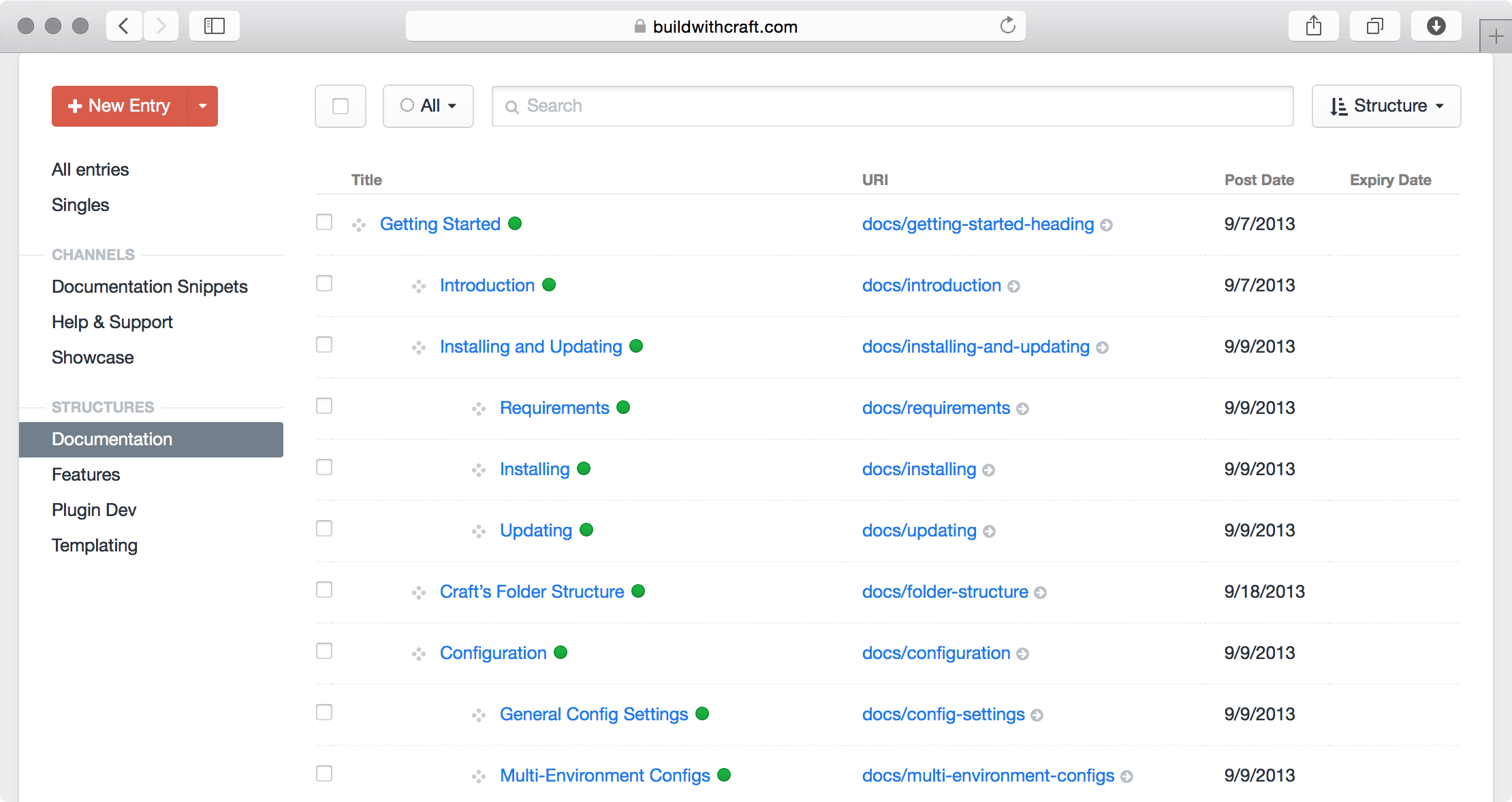
Interface permettant de classer le contenu dans une hiérarchie (appelée «structure») dans Craft CMS. Le contenu défini par leur place dans une hiérarchie peut avoir un sens dans certains cas, mais c’est un héritage de la navigation dans les menus qui n’a plus de sens lorsque le contenu est réutilisé sur des canaux ou placé par un logiciel tel que des algorithmes de ciblage. Publié sur craftcms.com ( Grand aperçu )
Il est intéressant de noter que les systèmes de gestion de contenu pour chatbots ont tendance à utiliser des structures hiérarchiques similaires pour organiser les arbres d'intention et les flux de dialogue. Cela signifie que les hiérarchies de contenu jouent différents rôles dans différents canaux, mais offrent souvent des moyens de naviguer dans le contenu. Une façon de procéder consiste à créer des types pour la navigation, dans lesquels vous pouvez organiser le contenu par références et créer des itinéraires pour les pages Web, les menus ou les chemins pour les interfaces de conversation.
Relationship Advice
References (ou relations ) est ce qui rend un système pour le contenu structuré possible, et c’est vraiment le cœur de tout ce que nous traitons en matière de contenu sur le Web (c’est la raison pour laquelle il est appelé métaphoriquement le web en premier lieu). Pouvoir faire des références entre des bits de contenu est une chose très puissante, mais cela peut aussi être coûteux en termes de capacité de l’arrière-plan à écrire et à récupérer de telles données. Par conséquent, vous devrez peut-être penser différemment si vous avez une multitude de documents car l’échelle est rarement gratuite.
Il est également utile de noter que vous n’avez pas toujours besoin d’une référence explicite pour joindre des données; le plus souvent, cela peut être fait en fonction de critères liés au contenu, par exemple: «Donnez-moi toutes les personnes et tous les bâtiments dans cette géolocalisation». Il n'est pas nécessaire que le bâtiment et les personnes aient une référence explicite, dans la mesure où cela est impliqué dans un champ d'emplacement sur les deux types de contenu.
Exemple d'un type de routage simple pour sanity.io. Notez que nous avons aussi un type “page”. ( Grand aperçu ) Le type de page est simplement une série de compositions spécifiques à une page Web où il est possible de réutiliser d’autres types de contenu. ( Grand aperçu )
Les références entre types de présentation et autres types de contenu sont utiles lorsque vous ne pouvez pas laisser un algorithme de la couche de présentation pour joindre des données. Il peut sembler un peu fastidieux de dessiner explicitement ces types de présentation et de créer des compositions de contenu référé, mais il s’agit d’une solution à un problème que vous rencontrerez souvent avec les systèmes de gestion de la chaîne de stockage: il est difficile de savoir où le contenu est utilisé. En incluant les types de navigation, vous associez explicitement le contenu à la présentation, mais pas à un seul. Cela permet de raisonner avec des structures de navigation indépendamment du contenu qu'elles entraînent.
Par exemple, dans les captures d'écran, nous avons lié l'attribut Google Experiments au type ce qui permet d'ajouter plusieurs . ] pages composées de références à du contenu, ce qui signifie que nous pouvons exécuter des tests A / B avec pratiquement aucune duplication du contenu. Comme nous recevons également un avertissement si nous essayons de supprimer le contenu référencé par d’autres documents, cette manière de structurer nous empêchera de supprimer quelque chose que nous ne devrions pas.
Les relations entre les types de contenu sont une arme à double tranchant. Cela augmente la durabilité et est essentiel pour éviter les doubles emplois. D'autre part, vous pouvez facilement vous couper vous-même, car vous créez des dépendances entre les contenus qui, s'ils ne sont pas transparents, peuvent entraîner des modifications inattendues sur les canaux où vos données sont affichées. Il serait mauvais, par exemple, de supprimer sans avertissement une «page» utilisée par une «route».
Ceci nous amène à la stratégie suivante, qui (d'accord!) Dépasse en partie le pouvoir de l'utilisateur normal. à compter d’aujourd’hui car il s’agit de l’architecture des différents systèmes. Cela vaut néanmoins la peine d’y réfléchir.
4. Ne mettez pas le texte enrichi dans un coin
Le texte enrichi, c’est plus que HTML
Je peux comprendre pourquoi on attribue une telle importance au contenu numérique dans HTML, mais je sais qu’il provient aussi de quelque chose; il s’agit d’un sous-ensemble de SGML, une méthode généralisée de structuration de documents lisibles par machine. As Claire L. Evans points out in the wonderful book “Broad Band: The Untold Story of the Women who made the Internet” (2018), there was already a vibrant community of people thinking about linked documents when HTML was introduced. Tim Berners-Lee’s proposal was a lot simpler than many of the other systems at the time, but that’s probably why it caught on and made the — as of now — open, free web possible.
Almost everyone does it though, even the new kids on the block: I went through all the vendors on headlesscms.org and browsed through the documentation, and also signed up for those who didn’t mention it. With two exceptions, they all stored rich text either as HTML or Markdown. That’s fine if all you do is use Jekyll to render a website, or if you enjoy using dangerouslySetInnerHTML in React. But what if you want to reuse your content in interfaces that aren’t on the web? Or if you want more control and functionality in your rich text editor? Or just want it to be easier to render your rich text in one of the popular frontend frameworks, and have your components take care of different parts of your rich text content? Well, you’ll either have to find a smart way to parse that markdown or HTML into what you need, or, more conveniently, just have it stored more sensically in the first place.
For example, what if you want to output your rich text to a voice interface? We know that voice assistants are increasing in popularity. The most popular platforms for these assistants have the capabilities to get the text for spoken content through APIs. Then you want to take advantage of something like Speech Synthesis Markup Language. A system for portable text takes a more agnostic approach to rich text, which lets you adapt the same content for different kinds of interfaces.
Example of a rich text editor with speech synthesis capabilities. Compatible with, but not restricted to SSML).
Portable text is also useful when you’re primarily doing content for the web. What if you want to have the possibility to nest and augment your text with data structures, such as a rich text footnote, or an inline editorial comment? Or an alternative phrase or wording for A/B-testing cases? Markdown and HTML quickly fall short, and you’ll have to rely on adding something like special shortcode tags, just like WordPress has solved it. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you’ll also be able to take advantage of microservices and bots, such as spaCyin order to annotate and augment your content without locking the document.
As for now, portable text isn’t widely adopted, but we’re seeing movements towards it. The specification isn’t very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn’t just used for your organization’s online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it’s about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can’t know prior to solving the problem whether the user tasks are best solved by making carousels (newsflash: most probably not), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
Is it possible, and how exactly will multi-disciplinary teams work with this system?
How easy is it to change and migrate the content model?
How does it deal with file and image assets?
Has the editorial interface been user tested?
To what extent can the system be configured and customized to special workflows and needs of the editorial team?
How easy is it to export the content in a moveable format?
How does the system accommodate for collaboration?
Can content models be version controlled?
How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile (there’s my coin for the swear jar) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn’t a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we’ve taken for granted for many years, but that’s probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.




![L'éditeur de contenu de U4.no avec un document de publication ouvert [19659024] Un exemple tiré de l'environnement de l'éditeur personnalisé de u4.no dans Sanity, avec son guide de style, est intégré aux champs avec soin et de manière contextuelle. (<a href=](https://i0.wp.com/cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/f933f265-7768-43cc-bf58-087b8b13ec2c/structured-content-done-right-2-u4-content-editor.png?ssl=1) Grand aperçu
Grand aperçu 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}