


{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Réduire la charge utile HTML avec Next.js (étude de cas)

Je sais ce que vous pensez. Voici un autre article sur la réduction des dépendances JavaScript et la taille du bundle envoyé au client. Mais celui-ci est un peu différent, je le promets.
Cet article traite de quelques problèmes auxquels Bookaway a été confronté et nous (en tant qu'entreprise du secteur du voyage) avons réussi à optimiser nos pages, de sorte que le HTML que nous envoyons est plus petit. Un HTML plus petit signifie moins de temps pour Google pour télécharger et traiter ces longues chaînes de texte.
Habituellement, la taille du code HTML n'est pas un gros problème, en particulier pour les petites pages, peu gourmandes en données, ou les pages qui ne sont pas orientées SEO . Cependant, dans nos pages, le cas était différent car notre base de données stocke beaucoup de données et nous devons servir des milliers de pages de destination à grande échelle.
Vous vous demandez peut-être pourquoi nous avons besoin d'une telle échelle. Eh bien, Bookaway travaille avec 1 500 opérateurs et fournit plus de 20 000 services dans 63 pays avec une croissance de 200% d'une année sur l'autre (avant Covid-19). En 2019, nous avons vendu 500000 billets par an, nos opérations sont donc complexes et nous devons le présenter avec nos pages de destination de manière attrayante et rapide. Tant pour les robots Google (SEO) que pour les clients réels.
Dans cet article, je vais vous expliquer:
- comment nous avons trouvé que la taille HTML est trop grande;
- comment elle a été réduite;
- les avantages de ce processus (c'est-à-dire créer une architecture améliorée, améliorer l'organisation de l'ode, fournir un travail simple à Google pour indexer des dizaines de milliers de pages de destination et servir beaucoup moins d'octets au client – particulièrement adapté aux personnes ayant des connexions lentes).
Mais d'abord, parlons de l'importance de l'amélioration de la vitesse.
Pourquoi l'amélioration de la vitesse est-elle nécessaire à nos efforts de référencement?
Rencontrez « Web Vitals », mais en particulier, rencontrez LCP (Largest Contentful Paint):
«Largest Contentful Paint (LCP) est une métrique importante, centrée sur l'utilisateur pour mesurer la vitesse de chargement perçue car elle marque le point dans la chronologie de chargement de la page lorsque la page principale le contenu a probablement été chargé – un LCP rapide permet de rassurer l'utilisateur sur le fait que le page est utile . ”
L'objectif principal est d'avoir un petit LCP possible. Une partie d'avoir un petit LCP est de permettre à l'utilisateur de télécharger le plus petit HTML possible. De cette façon, l'utilisateur peut commencer le processus de peinture de la plus grande peinture de contenu dès que possible.
Bien que LCP soit une métrique centrée sur l'utilisateur, sa réduction devrait être d'une grande utilité pour les robots Google comme le déclare Googe:
«Le Web est un espace presque infini, dépassant la capacité de Google à explorer et à indexer toutes les URL disponibles. Par conséquent, il existe des limites au temps que Googlebot peut consacrer à l'exploration d'un seul site. Le temps et les ressources dont dispose Google pour explorer un site sont communément appelés le budget d'exploration du site. »
-« Advanced SEO »Google Search Central Documentation
Un des meilleurs moyens techniques Pour améliorer le budget d'exploration, il faut aider Google à faire plus en moins de temps :
Q : «La vitesse du site affecte-t-elle mon budget d'exploration? Qu'en est-il des erreurs? »
A :« Rendre un site plus rapide améliore l'expérience des utilisateurs tout en augmentant la vitesse d'exploration. Pour Googlebot, un site rapide est le signe que les serveurs sont sains et qu'il peut obtenir plus de contenu sur le même nombre de connexions. »
Pour résumer, les robots Google et les clients Bookaway ont le même objectif – ils veulent que le contenu soit diffusé rapidement. Étant donné que notre base de données contient une grande quantité de données pour chaque page, nous devons l'agréger efficacement et envoyer quelque chose de petit et léger aux clients.
Les recherches sur les moyens d'améliorer nous ont conduit à découvrir qu'il y avait un gros JSON intégré dans notre HTML, ce qui rend le HTML volumineux. Dans ce cas, nous devrons comprendre React Hydration.
React Hydration: Pourquoi il y a un JSON dans HTML
Cela se produit à cause du fonctionnement du rendu côté serveur dans react et Next.js:
- Quand la demande arrive au serveur – il doit créer un HTML basé sur une collecte de données. Cette collection de données est l'objet renvoyé par
getServerSideProps. - React a obtenu les données. Maintenant, il entre en jeu sur le serveur. Il construit en HTML et l'envoie.
- Lorsque le client reçoit le HTML, il est immédiatement peiné devant lui. En attendant, React javascript est en cours de téléchargement et d'exécution.
- Lorsque l'exécution de javascript est terminée, React se remet en jeu, maintenant sur le client. Il construit à nouveau le HTML et attache des écouteurs d'événements. Cette action s'appelle hydratation .
- Comme React reconstruit le HTML pour le processus d'hydratation, elle nécessite la même collecte de données que celle utilisée sur le serveur (retournez à
1.). - Cette collection de données est rendue disponible en insérant le JSON dans une balise de script avec l'ID
__ NEXT_DATA __.
De quelles pages parlons-nous exactement?
Comme nous devons promouvoir nos offres dans moteurs de recherche, le besoin de pages de destination est apparu. Les gens ne recherchent généralement pas le nom d’une ligne de bus spécifique, mais plutôt «Comment se rendre de Bangkok à Pattaya?» Jusqu'à présent, nous avons créé quatre types de pages de destination qui devraient répondre à ces questions:
- Ville A à Ville B
Toutes les lignes s'étiraient d'une station de la ville A à une station de la ville B. (par exemple Bangkok à Pattaya ) - Ville
Toutes les lignes qui traversent une ville spécifique. (par exemple Cancun ) - Country
Toutes les lignes qui traversent un pays spécifique. (par exemple Italie ) - Station
Toutes les lignes qui passent par une station spécifique. (par exemple, Aéroport de Hanoi )
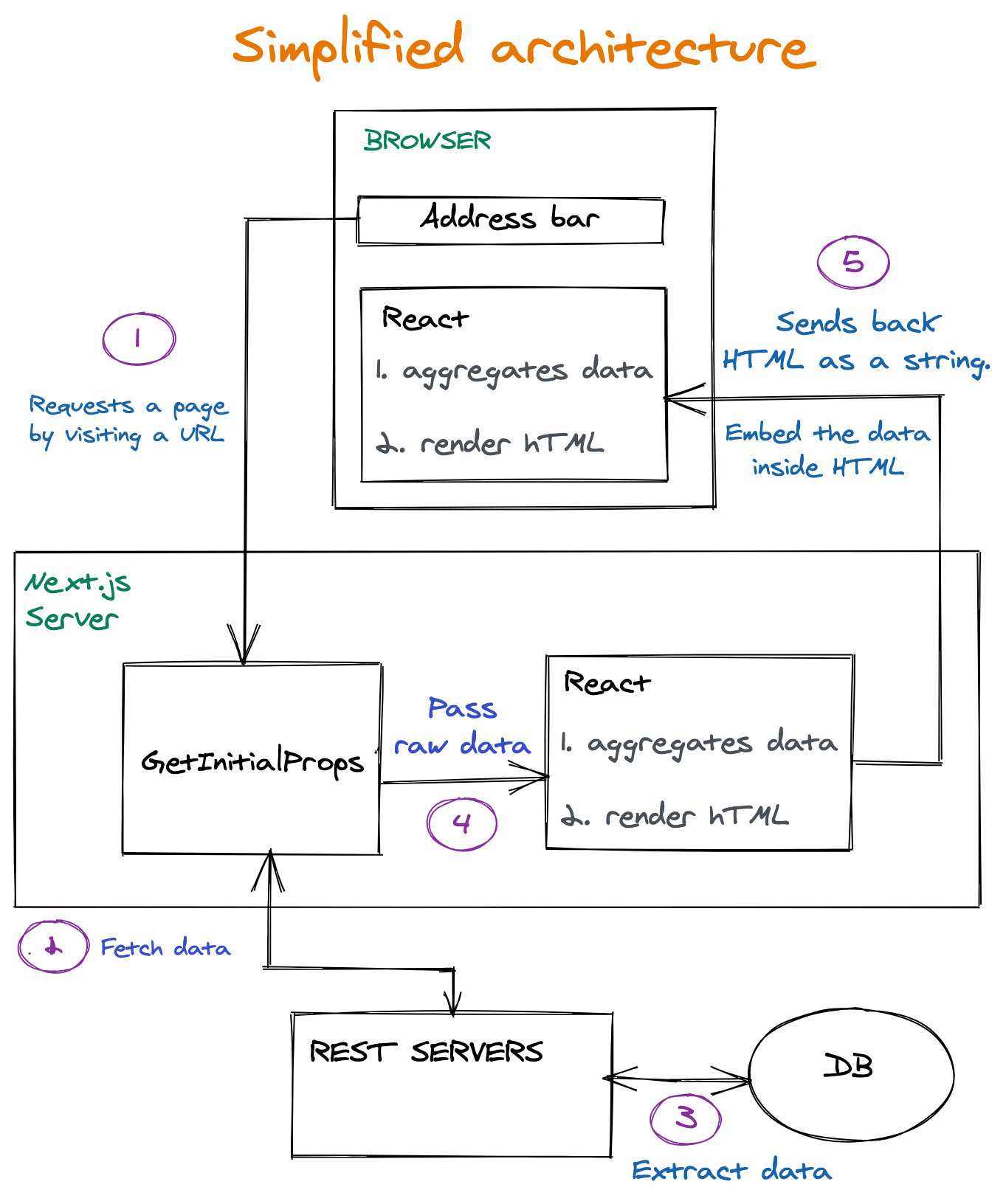
Maintenant, un regard sur l'architecture
Jetons un regard de haut niveau et très simplifié sur l'infrastructure alimentant les pages de destination dont nous parlons. Des parties intéressantes se trouvent sur 4 et 5 . C’est là que les parties gaspillent:

Principaux points à retenir du processus
- La requête atteint la fonction
getInitialProps. Cette fonction s'exécute sur le serveur. La responsabilité de cette fonction est de récupérer les données nécessaires à la construction d’une page. - Les données brutes renvoyées par les serveurs REST sont transmises telles quelles à React.
- Tout d’abord, elle s’exécute sur le serveur. Étant donné que les données non agrégées ont été transférées vers React, React est également responsable de l'agrégation des données en quelque chose qui peut être utilisé par les composants de l'interface utilisateur (plus d'informations à ce sujet dans les sections suivantes)
- Le HTML est envoyé au client, ensemble avec les données brutes. Ensuite, React se remet en jeu également chez le client et fait le même travail. Parce que l'hydratation est nécessaire (plus à ce sujet dans les sections suivantes). React fait donc deux fois le travail d'agrégation de données.
Le problème
L'analyse de notre processus de création de page nous a conduit à la découverte de Big JSON intégré dans le HTML. La taille exacte est difficile à dire. Chaque page est légèrement différente car chaque station ou ville doit agréger un ensemble de données différent. Cependant, il est prudent de dire que la taille JSON peut atteindre 250 Ko sur les pages populaires. Il a ensuite été réduit à des tailles d'environ 5 ko à 15 ko. Réduction considérable. Sur certaines pages, il traînait entre 200 et 300 ko. C'est gros .
Le gros JSON est intégré dans une balise de script avec l'ID de ___ NEXT_DATA ___ :
Si vous souhaitez copier facilement ce JSON dans votre presse-papiers, essayez cet extrait de code dans votre page Next.js:
copy ($ ('#__ NEXT_DATA __'). InnerHTML)
Une question se pose:
Pourquoi est-ce si grand? Qu'y a-t-il là?
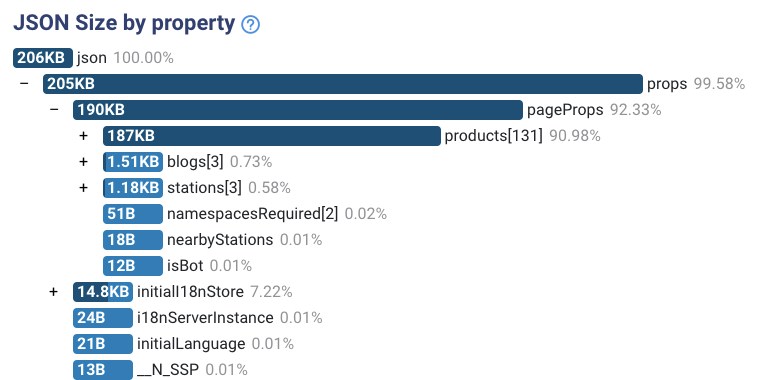
Un excellent outil, JSON Size analyzer sait comment traiter un JSON et montre où se trouve la plus grande partie de la taille.
Tels étaient nos premiers résultats lors de l'examen d'un page de la station :

Il y a deux problèmes avec l'analyse:
- Les données ne sont pas agrégées.
Notre HTML contient la liste complète des produits granulaires. Nous n'en avons pas besoin pour peindre à l'écran. Nous en avons besoin pour les méthodes d'agrégation. Par exemple, nous récupérons une liste de toutes les lignes passant par cette station. Chaque ligne a un fournisseur. Mais nous devons réduire la liste des lignes à un tableau de 2 fournisseurs. C'est ça. Nous verrons un exemple plus tard. - Champs inutiles.
Lors de l'exploration de chaque objet, nous avons vu des champs dont nous n'avons pas du tout besoin. Pas à des fins d'agrégation et pas pour les méthodes de peinture. C'est parce que nous récupérons les données de l'API REST. Nous ne pouvons pas contrôler les données que nous récupérons.
Ces deux problèmes ont montré que les pages doivent changer d'architecture. Mais attendez. Pourquoi avons-nous besoin d'un JSON de données intégré dans notre HTML en premier lieu? 🤔
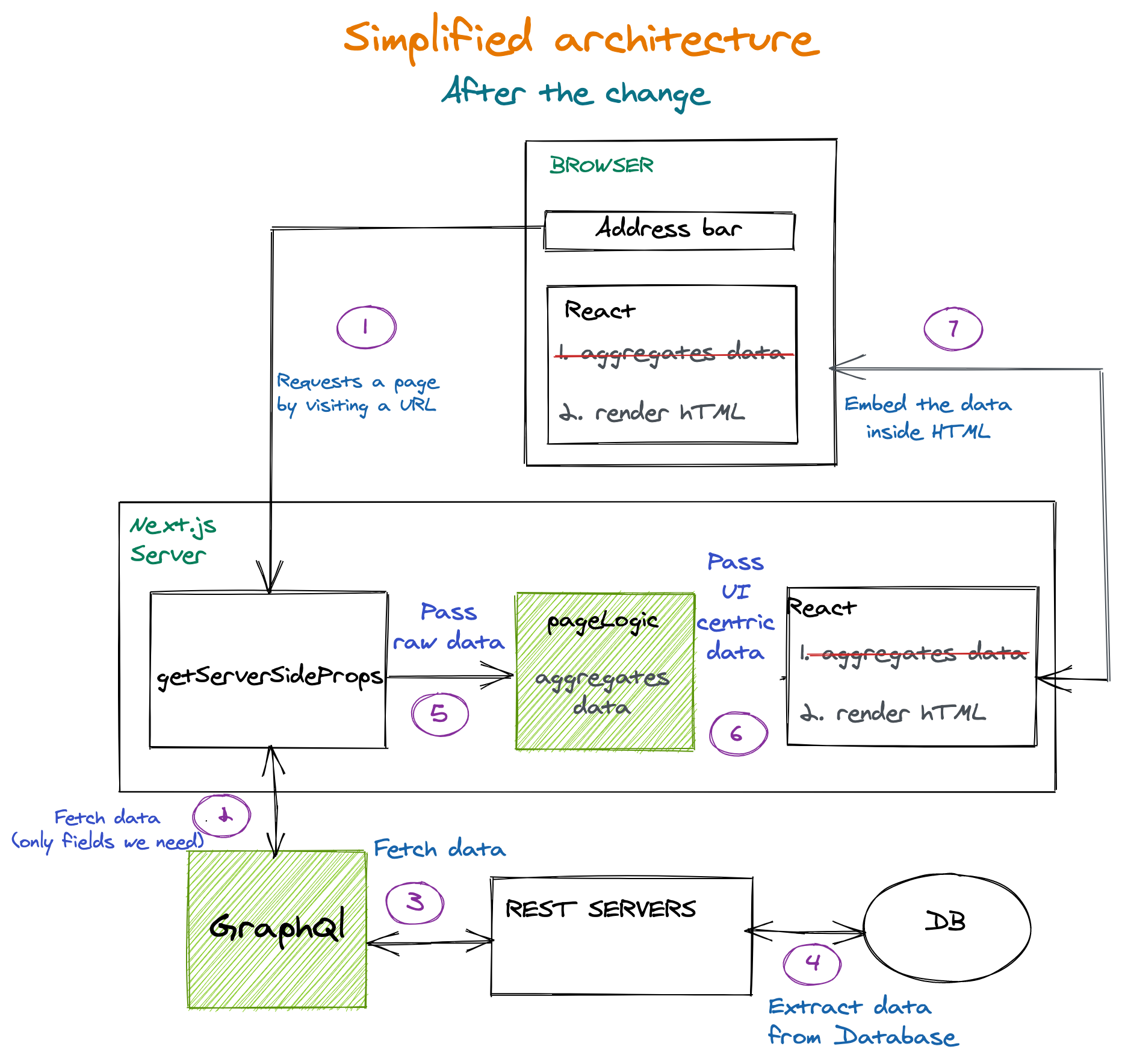
Changement d'architecture
Le problème du très gros JSON devait être résolu dans une solution soignée et en couches. Comment? Eh bien, en ajoutant les couches marquées en vert dans le diagramme suivant:

Quelques points à noter:
- La double agrégation de données a été supprimée et consolidée pour être effectuée une seule fois sur le serveur Next.js uniquement;
- Ajout de la couche Graphql Server . Cela garantit que nous n'obtenons que les champs que nous voulons. La base de données peut augmenter avec beaucoup plus de champs pour chaque entité, mais cela ne nous affectera plus;
-
PageLogicfonction ajoutée dansgetServerSideProps. Cette fonction obtient des données non agrégées à partir des services back-end. Cette fonction agrège et prépare les données pour les composants de l'interface utilisateur. (Il ne fonctionne que sur le serveur.)
Exemple de flux de données
Nous voulons rendre cette section à partir d'une page de station :

Nous avons besoin de savoir qui sont les fournisseurs opérant dans une station donnée. Nous devons récupérer toutes les lignes pour le point de terminaison REST lines . C’est la réponse que nous avons obtenue (exemple de but, en réalité, elle était beaucoup plus large):
[
{
id: "58a8bd82b4869b00063b22d2",
class: "Standard",
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
id: "58f5e40da02e97f000888e07a",
class: "Luxury",
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
id: "58f5e4a0a02e97f000325e3a",
class: 'Luxury',
supplier: "Jones Ltd",
type: "minivan",
},
];
[
{ supplier: "Hyatt-Mosciski", amountOfLines: 2, types: ["bus"]},
{fournisseur: "Jones Ltd", amountOfLines: 1, types: ["minivan"]},
];
Comme vous pouvez le voir, nous avons des champs non pertinents. les images et id ne joueront aucun rôle dans la section. Nous allons donc appeler le serveur Graphql et ne demander que les champs dont nous avons besoin. Alors maintenant, cela ressemble à ceci:
[
{
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
supplier: "Jones Ltd",
type: "minivan",
},
];
C'est maintenant un objet plus facile à utiliser. Il est plus petit, plus facile à déboguer et prend moins de mémoire sur le serveur. Mais, il n'est pas encore agrégé. Ce n’est pas la structure de données requise pour le rendu réel.
Envoyons-le à la fonction PageLogic pour le tester et voir ce que nous obtenons:
[
{ supplier: "Hyatt-Mosciski", amountOfLines: 2, types: ["bus"] },
{fournisseur: "Jones Ltd", amountOfLines: 1, types: ["minivan"]},
];
Cette petite collection de données est envoyée à la page Next.js.
Maintenant, c'est prêt pour le rendu de l'interface utilisateur. Plus besoin de croquer et de préparer. De plus, il est désormais très compact par rapport à la collecte de données initiale que nous avons extraite. C’est important car nous n’envoyons que très peu de données au client de cette façon.
Comment mesurer l’impact du changement
La réduction de la taille du HTML signifie qu’il y a moins de bits à télécharger. Lorsqu'un utilisateur demande une page, il obtient du HTML entièrement formé en moins de temps. Ceci peut être mesuré dans téléchargement de contenu de la ressource HTML dans le panneau de réseau .
Conclusions
Fournir des ressources minces est essentiel, surtout quand il s'agit de HTML. Si le HTML s'avère important, nous n'avons plus de place pour les ressources CSS ou le javascript dans notre budget de performance .
Il est recommandé de supposer que de nombreux utilisateurs réels n'utiliseront pas un iPhone 12 , mais plutôt un appareil de niveau intermédiaire sur un réseau de niveau intermédiaire. Il s'avère que les niveaux de performances sont assez serrés, comme le suggère l'article très apprécié :
«Grâce aux progrès des réseaux et des navigateurs (mais pas des appareils), un plafond budgétaire global plus généreux est apparu pour sites construits de manière «moderne». Nous pouvons maintenant nous permettre ~ 100KiB de HTML / CSS / polices et ~ 300-350KiB de JS (gzippé). Cette limite de règle empirique devrait durer au moins un an ou deux. Comme toujours, le diable est dans les notes de bas de page, mais la ligne du haut est inchangée: lorsque nous construisons le monde numérique aux limites des meilleurs appareils, nous en construisons un moins utilisable pour plus de 80% des utilisateurs du monde. »
Impact sur les performances
Nous mesurons l'impact sur les performances en fonction du temps nécessaire pour télécharger le code HTML en cas de ralentissement 3g. cette métrique est appelée «téléchargement de contenu» dans Chrome Dev Tools .
Voici un exemple de métrique pour une page de station :
| Taille HTML (avant gzip) | HTML Durée de téléchargement (3G lente) | |
|---|---|---|
| Avant | 370kb | 820ms |
| Après | 166 | 540ms |
| Changement total | Baisse de 204kb | Diminution de 34% |
Couché Solution
Les changements d'architecture incluaient des couches supplémentaires:
- Serveur GraphQl : aides pour récupérer exactement ce que nous voulons.
- Fonction dédiée pour l'agrégation : ne fonctionne que sur le serveur .
Ceux qui ont changé, mis à part les améliorations de performances pures, ont également offert une bien meilleure organisation du code et une meilleure expérience de débogage:
- Toute la logique concernant la réduction et l'agrégation des données est désormais centralisée dans une seule fonction;
- Les fonctions de l'interface utilisateur sont désormais beaucoup plus simple. Pas d'agrégation, pas de traitement des données. Ils ne font qu'obtenir des données et les peindre;
- Le débogage du code du serveur est plus agréable puisque nous extrayons uniquement les données dont nous avons besoin – plus de champs inutiles provenant d'un point de terminaison REST.
Source link