


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Partage de données entre plusieurs serveurs via AWS S3
À propos de l'auteur
Leonardo Losoviz est le créateur de PoP un framework pour la construction de sites Web modulaires basés sur PHP et les guidons, et optimisé par WordPress. Il habite à Kuala…
Plus à propos de Leonardo
Lors de la création d'un formulaire en plusieurs étapes dans lequel un fichier est chargé et manipulé, si l'application s'exécute sur plusieurs serveurs derrière un équilibreur de charge, nous devons nous assurer que le fichier est disponible tout au long de l'exécution du processus, quel que soit le serveur qui gère le processus à chaque étape. Dans cet article, nous allons résoudre ce problème en créant un référentiel accessible à tous les serveurs sur lesquels télécharger les fichiers, basé sur AWS S3.
Lorsqu'il fournit certaines fonctionnalités pour le traitement d'un fichier téléchargé par l'utilisateur, celui-ci doit être disponible pour le processus tout au long de l'exécution. Une simple opération de téléchargement et d’enregistrement ne présente aucun problème. Cependant, si en outre, le fichier doit être manipulé avant d'être enregistré et que l'application s'exécute sur plusieurs serveurs derrière un équilibreur de charge, nous devons nous assurer que le fichier est disponible pour le serveur sur lequel le processus est exécuté à chaque fois. [19659005] Par exemple, une fonctionnalité «Téléchargez votre avatar d'utilisateur en plusieurs étapes» peut demander à l'utilisateur de télécharger un avatar à l'étape 1, de le rogner à l'étape 2 et enfin de l'enregistrer à l'étape 3. Une fois le fichier chargé sur un serveur à l'étape 1, le fichier doit être disponible pour le serveur qui gère la demande des étapes 2 et 3, qui peut être identique ou non pour l'étape 1.
Une approche naïve consisterait à copier le fichier téléchargé à l'étape 1. sur tous les autres serveurs, le fichier sera donc disponible sur tous les serveurs. Cependant, cette approche est non seulement extrêmement complexe, mais également irréalisable: par exemple, si le site fonctionne sur des centaines de serveurs, provenant de plusieurs régions, il est impossible de le réaliser.
Une solution possible consiste à activer les “sessions bloquées” sur le serveur. l’équilibreur de charge, qui affectera toujours le même serveur pour une session donnée. Ensuite, les étapes 1, 2 et 3 seront gérées par le même serveur et le fichier téléchargé sur ce serveur à l'étape 1 sera toujours présent pour les étapes 2 et 3. Toutefois, les sessions collantes ne sont pas totalement fiables: Si entre les étapes 1 et 3 et 2 le serveur est tombé en panne, l'équilibreur de charge devra alors affecter un serveur différent, perturbant ainsi la fonctionnalité et l'expérience utilisateur. De même, l'affectation du même serveur pour une même session peut, dans des circonstances particulières, ralentir les temps de réponse d'un serveur surchargé.
Une solution plus appropriée consiste à conserver une copie du fichier dans un référentiel accessible à tous les serveurs. Ensuite, après le téléchargement du fichier sur le serveur à l'étape 1, ce serveur le téléchargera dans le référentiel (ou le fichier pourra également être téléchargé dans le référentiel directement à partir du client, en contournant le serveur); l’étape 2 de gestion du serveur télécharge le fichier à partir du référentiel, le manipule et le télécharge à nouveau; Enfin, le serveur gérant l’étape 3 le téléchargera à partir du référentiel et le sauvegardera.
Dans cet article, je vais décrire cette dernière solution, basée sur une application WordPress stockant des fichiers sur Amazon Web Services (AWS) Simple Storage Service ( S3) (solution de stockage d'objets en nuage pour stocker et récupérer des données), exécutée via le kit SDK AWS.
Note 1: Pour une fonctionnalité simple telle que le recadrage d'avatars, une autre solution serait: Contourner complètement le serveur et le mettre en œuvre directement dans le nuage via les fonctions Lambda . Mais comme cet article traite de la connexion d'une application s'exécutant sur le serveur avec AWS S3, nous ne considérons pas cette solution.
Note 2: Pour utiliser AWS S3 (ou tout autre élément AWS). services), nous aurons besoin d’un compte utilisateur. Amazon propose un niveau gratuit ici pendant 1 an, ce qui est suffisant pour expérimenter leurs services.
Note 3: Il existe des plugins tiers permettant de télécharger des fichiers de WordPress à S3. . Un de ces plugins est WP Media Offload (la version allégée est disponible ici ), qui offre une fonctionnalité intéressante: il transfère de manière transparente les fichiers chargés dans la médiathèque vers un compartiment S3, qui permet pour découpler le contenu du site (tel que tout ce qui se trouve sous / wp-content / uploads) du code de l'application. En découplant le contenu et le code, nous sommes en mesure de déployer notre application WordPress à l'aide de Git (sinon, nous ne pouvons pas puisque le contenu téléchargé par l'utilisateur n'est pas hébergé sur le référentiel Git), et héberger l'application sur plusieurs serveurs (sinon, chaque serveur devrait conserver une copie de tout le contenu téléchargé par l'utilisateur.)
Création du seau
Lors de la création du seau, nous devons prendre en compte le nom du seau: chaque nom de seau doit être globalement unique sur le réseau AWS, de sorte que même voudrait appeler notre seau quelque chose de simple comme "avatars", ce nom peut déjà être pris, alors nous pouvons choisir quelque chose de plus distinctif comme "avatars-nom-de-ma-société".
Nous devrons également sélectionner le région dans laquelle le compartiment est basé (la région est l'emplacement physique où se trouve le centre de données, avec des emplacements dans le monde entier.)
La région doit être identique à celle où notre application est déployée, afin de pouvoir accéder à S3 pendant l'exécution du processus est rapide. Sinon, l'utilisateur devra peut-être attendre des secondes supplémentaires avant de télécharger une image vers / depuis un emplacement distant.
Remarque: Il est logique d'utiliser S3 comme solution de stockage d'objets en nuage uniquement si nous utilisez le service d'Amazon pour les serveurs virtuels sur le cloud, EC2 pour exécuter l'application. Si au lieu de cela, nous nous appuyons sur une autre société pour héberger l'application, telle que Microsoft Azure ou DigitalOcean nous devrions également utiliser leurs services de stockage d'objets en nuage. Sinon, notre site souffrira de la surcharge des données transitant sur les réseaux de différentes sociétés.
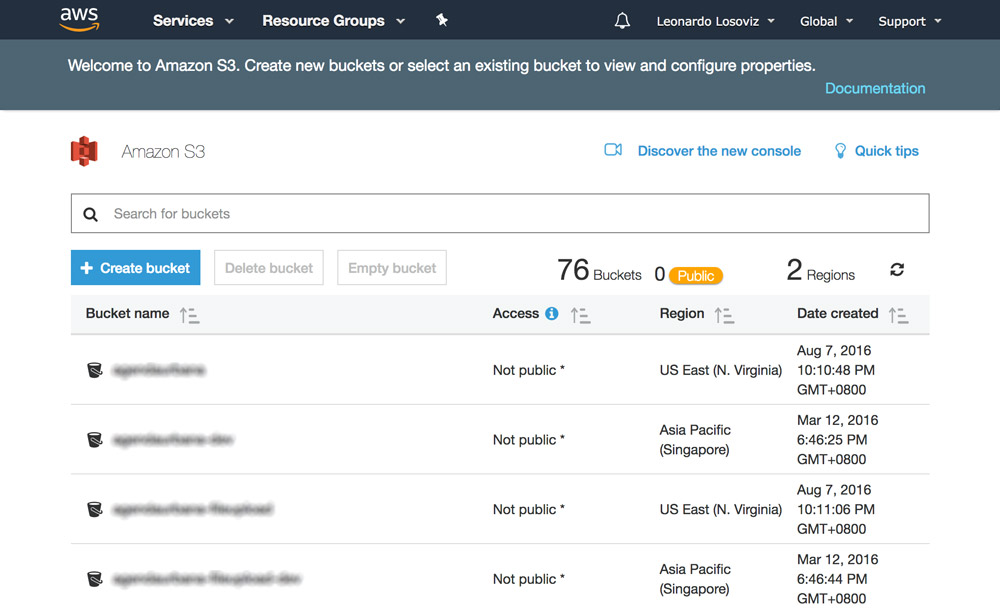
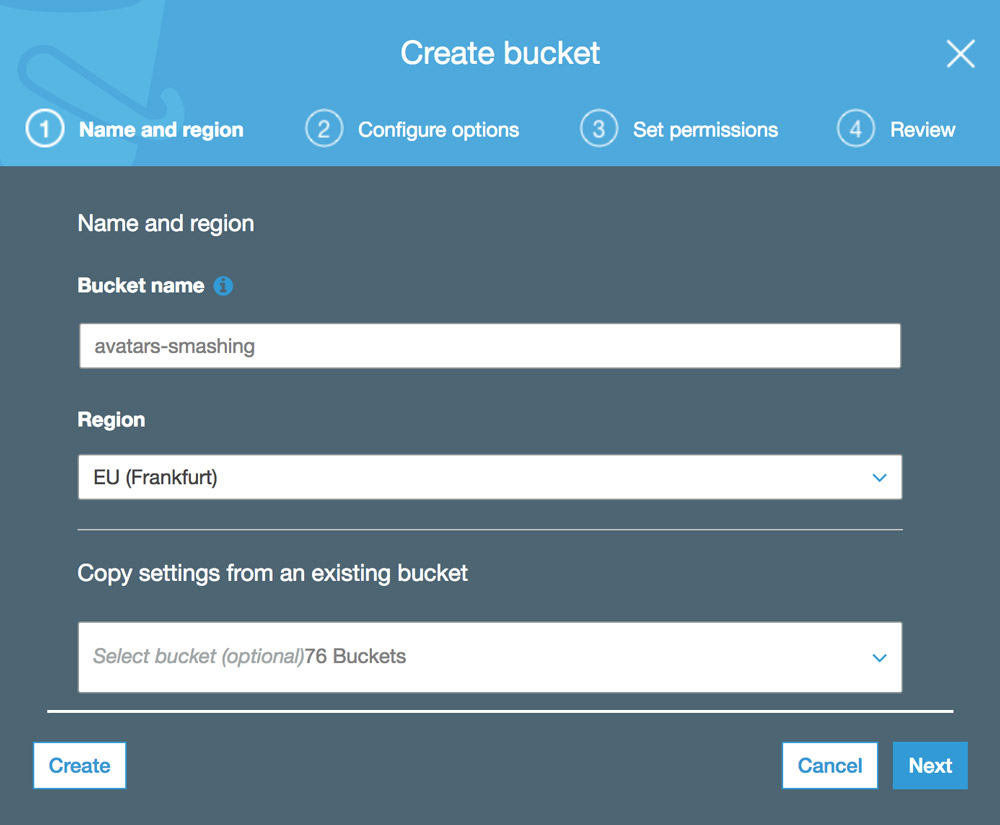
Dans les captures d'écran ci-dessous, nous verrons comment créer le compartiment dans lequel télécharger les avatars des utilisateurs pour le recadrage. Nous allons d’abord au tableau de bord S3 et cliquez sur «Créer un compartiment»:

Ensuite, nous tapons le nom du compartiment (dans ce cas, “avatars-smashing”) et choisissons la région (“UE (Francfort)”):

Seuls le nom du compartiment et la région sont obligatoires. Pour les étapes suivantes, nous pouvons conserver les options par défaut. Nous cliquons donc sur «Suivant» jusqu'à ce que nous cliquions sur «Créer un compartiment», ce qui créera le compartiment.
Configuration des autorisations utilisateur
Quand Pour nous connecter à AWS via le SDK, nous devrons entrer nos informations d'identification d'utilisateur (une paire d'identifiant de clé d'accès et de clé d'accès secrète) afin de valider l'accès aux services et aux objets demandés. Les autorisations des utilisateurs peuvent être très générales (un rôle «admin» peut tout faire) ou très granulaires, accordant simplement l'autorisation aux opérations spécifiques requises et rien d'autre.
En règle générale, plus les autorisations que nous avons accordées sont spécifiques, mieux cela vaut pour éviter les problèmes de sécurité . Lors de la création du nouvel utilisateur, nous devrons créer une stratégie, qui est un simple document JSON répertoriant les autorisations à accorder à l'utilisateur. Dans notre cas, nos autorisations d’utilisateur donneront accès à S3, pour le compartiment «avatars-smashing», pour les opérations «Put» (téléchargement d’un objet), «Get» (téléchargement d’un objet) et «Liste» ( pour répertorier tous les objets dans le compartiment), entraînant la règle suivante:
{
"Version": "2012-10-17",
"Déclaration": [
{
"Effect": "Allow",
"Action": [
"s3:Put*",
"s3:Get*",
"s3:List*"
],
"Ressource": [
"arn:aws:s3:::avatars-smashing",
"arn:aws:s3:::avatars-smashing/*"
]
}
]
}
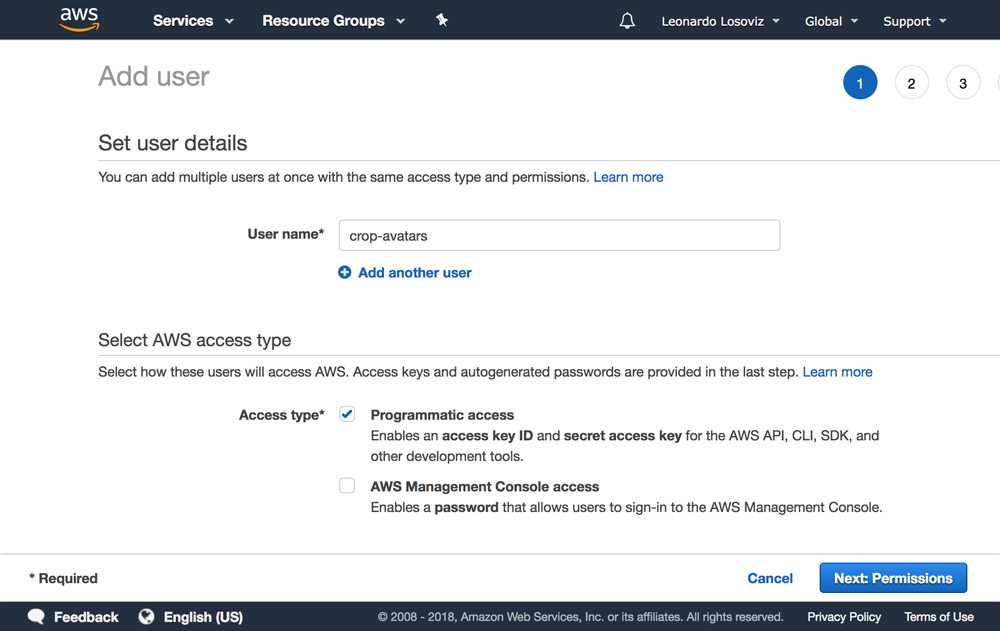
Dans les captures d'écran ci-dessous, nous pouvons voir comment ajouter des autorisations utilisateur. Nous devons nous rendre au tableau de bord Gestion de l'identité et des accès (IAM) :

Dans le tableau de bord, nous cliquons sur «Utilisateurs» et immédiatement après sur «Ajouter un utilisateur». Dans la page Ajouter un utilisateur, nous choisissons un nom d'utilisateur (“crop-avatars”) et cochez la case “Accès programmatique” comme type d'accès. Celui-ci fournira l'ID de la clé d'accès et la clé d'accès secrète pour la connexion via le SDK: [19659036] Ajouter une page utilisateur « />
Cliquez ensuite sur le bouton «Suivant: Autorisations», cliquez sur «Attacher directement les stratégies existantes», puis sur «Créer une stratégie». Cela ouvrira un nouvel onglet dans le navigateur, avec la page Créer une politique. Nous cliquons sur l'onglet JSON et entrons le code JSON de la stratégie définie ci-dessus:

Ensuite, nous cliquons sur Review policy, lui donnons un nom («CropAvatars»), et enfin cliquez sur Create policy. Une fois la stratégie créée, nous revenons à l'onglet précédent, sélectionnons la stratégie CropAvatars (nous aurons peut-être besoin d'actualiser la liste des stratégies pour la voir), cliquez sur Suivant: Consulter et enfin sur Créer un utilisateur. Ceci fait, nous pouvons enfin télécharger l’ID de clé d’accès et la clé d’accès secrète (veuillez noter que ces informations d’identité sont disponibles pour ce moment unique; si nous ne les copions ou ne les téléchargeons pas maintenant, nous devrons créer une nouvelle paire. ):

Connexion à AWS via le SDK
Le SDK est disponible dans une multitude de langues. Pour une application WordPress, nous avons besoin du SDK pour PHP qui peut être téléchargé à partir d’ici et les instructions pour l’installer sont ici .
Une fois le seau créé, Lorsque les informations d'identification de l'utilisateur sont prêtes et que le SDK est installé, nous pouvons commencer à télécharger des fichiers vers S3.
Téléchargement et téléchargement de fichiers
Par souci de commodité, nous définissons les informations d'identification de l'utilisateur et la région comme constantes dans le fichier wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Votre identifiant de clé d'accès
define ('AWS_SECRET_ACCESS_KEY', '...'); // Votre clé d'accès secrète
define ('AWS_REGION', 'eu-central-1'); // Région où se trouve le compartiment. Ceci est l'identifiant de la région pour "EU (Frankfurt)"
Dans notre cas, nous implémentons la fonctionnalité d'avatar de rognage, pour laquelle les avatars seront stockés sur le seau «écrasant les avatars». Cependant, dans notre application, nous pouvons avoir plusieurs autres compartiments pour d'autres fonctionnalités, nécessitant l'exécution des mêmes opérations de téléchargement, de téléchargement et de listage de fichiers. Par conséquent, nous implémentons les méthodes communes sur une classe abstraite AWS_S3 et nous obtenons les entrées, telles que le nom de compartiment défini par la fonction get_bucket dans les classes enfant implémentées.
// charge le SDK et importe les objets AWS
nécessite 'vendor / autoload.php';
utilisez Aws S3 S3Client;
utilisez Aws Exception AwsException;
// Définition d'une classe abstraite
classe abstraite AWS_S3 {
fonction protégée get_bucket () {
// Le nom du compartiment sera implémenté par la classe enfant.
revenir '';
}
}
La classe S3Client expose l'API permettant d'interagir avec S3. Nous l'instancions uniquement lorsque cela est nécessaire (via une initialisation différée) et nous sauvegardons une référence à elle sous $ this-> s3Client afin de continuer à utiliser le même exemple:
la classe abstraite AWS_S3 {
// Suite d'en haut ...
protected $ s3Client;
fonction protégée get_s3_client () {
// Initialisation paresseuse
si (! $ this-> s3Client) {
// Créer un client S3. Fournissez les informations d'identification et la région telles que définies par les constantes dans wp-config.php
$ this-> s3Client = new S3Client ([
'version' => '2006-03-01',
'region' => AWS_REGION,
'credentials' => [
'key' => AWS_ACCESS_KEY_ID,
'secret' => AWS_SECRET_ACCESS_KEY,
],
]);
}
return $ this-> s3Client;
}
}
Lorsque nous traitons de $ file dans notre application, cette variable contient le chemin absolu du fichier sur le disque (par exemple, / var / app / current / wp-content / uploads / users /654/leo.jpg), mais lors du téléchargement du fichier sur S3, nous ne devrions pas stocker l’objet dans le même chemin. En particulier, nous devons supprimer le bit initial concernant les informations système ( / var / app / current ) pour des raisons de sécurité, et éventuellement nous pouvons supprimer le bit / wp-content (depuis tous les fichiers sont stockés dans ce dossier, il s'agit d'informations redondantes), en conservant uniquement le chemin relatif du fichier ( /uploads/users/654/leo.jpg ). Cela peut être réalisé de manière pratique en supprimant tout le chemin après WP_CONTENT_DIR du chemin absolu. Les fonctions get_file et get_file_relative_path ci-dessous permettent de basculer entre les chemins d'accès absolus et relatifs:
la classe abstraite AWS_S3 {
// Suite d'en haut ...
fonction get_file_relative_path ($ file) {
return substr ($ file, strlen (WP_CONTENT_DIR));
}
function get_file ($ file_relative_path) {
return WP_CONTENT_DIR. $ file_relative_path;
}
}
Lors du téléchargement d'un objet vers S3, nous pouvons déterminer qui est autorisé à accéder à l'objet et au type d'accès, via les autorisations de la liste de contrôle d'accès (ACL). Les options les plus courantes sont de garder le fichier privé (ACL => “privé”) et de le rendre accessible à la lecture sur Internet (ACL => “public-read”). Comme nous aurons besoin de demander le fichier directement à S3 pour le montrer à l'utilisateur, nous avons besoin de ACL => “public-read”:
classe abstraite AWS_S3 {
// Suite d'en haut ...
fonction protégée get_acl () {
retourner 'public-read';
}
}
Enfin, nous implémentons les méthodes permettant de télécharger un objet dans le compartiment S3 et de télécharger un objet à partir de celui-ci:
classe abstraite AWS_S3 {
// Suite d'en haut ...
fonction upload ($ fichier) {
$ s3Client = $ this-> get_s3_client ();
// Télécharger un objet fichier sur S3
$ s3Client-> putObject ([
'ACL' => $this->get_acl(),
'Bucket' => $this->get_bucket(),
'Key' => $this->get_file_relative_path($file),
'SourceFile' => $file,
]);
}
téléchargement de fonction (fichier $) {
$ s3Client = $ this-> get_s3_client ();
// Télécharger un objet fichier depuis S3
$ s3Client-> getObject ([
'Bucket' => $this->get_bucket(),
'Key' => $this->get_file_relative_path($file),
'SaveAs' => $file,
]);
}
}
Ensuite, dans la classe enfant d'implémentation, nous définissons le nom du compartiment:
classe AvatarCropper_AWS_S3 étend AWS_S3 {
fonction protégée get_bucket () {
retourner 'avatars-fracassant';
}
}
Enfin, nous demandons simplement à la classe de télécharger les avatars ou de télécharger à partir de S3. De plus, lors du passage des étapes 1 à 2 et 2 à 3, nous devons communiquer la valeur de $ file . Nous pouvons faire cela en soumettant un champ "file_relative_path" avec la valeur du chemin relatif de $ file via une opération POST (nous ne transmettons pas le chemin absolu pour des raisons de sécurité: inutile d'inclure le " / var / www / current ”pour que les étrangers puissent voir):
// Étape 1: après le téléchargement du fichier sur le serveur, chargez-le sur S3. Ici, le fichier $ est connu
$ avatarcropper = new AvatarCropper_AWS_S3 ();
$ avatarcropper-> upload ($ fichier);
// Récupère le chemin du fichier et l'envoie à l'étape suivante du POST
$ file_relative_path = $ avatarcropper-> get_file_relative_path ($ file);
// ...
// ---------------------------------------------------- -
// Étape 2: récupérez le fichier $ à partir de la requête et téléchargez-le, manipulez-le et transférez-le à nouveau
$ avatarcropper = new AvatarCropper_AWS_S3 ();
$ file_relative_path = $ _POST ['file_relative_path'];
$ file = $ avatarcropper-> get_file ($ file_relative_path);
$ avatarcropper-> download ($ fichier);
// manipule le fichier
// ...
// Transférer le fichier à nouveau sur S3
$ avatarcropper-> upload ($ fichier);
// ---------------------------------------------------- -
// Étape 3: récupérez le fichier $ à partir de la requête et téléchargez-le puis enregistrez-le
$ avatarcropper = new AvatarCropper_AWS_S3 ();
$ file_relative_path = $ _REQUEST ['file_relative_path'];
$ file = $ avatarcropper-> get_file ($ file_relative_path);
$ avatarcropper-> download ($ fichier);
// Enregistrez-le, peu importe ce que cela signifie
// ...
Affichage direct du fichier à partir de S3
Si nous voulons afficher l'état intermédiaire du fichier après manipulation à l'étape 2 (par exemple, l'avatar de l'utilisateur après le recadrage), nous devons référencer le fichier directement à partir de S3; l'URL ne pouvait pas pointer vers le fichier sur le serveur car, encore une fois, nous ne savons pas quel serveur traitera cette requête.
Ci-dessous, nous ajoutons la fonction get_file_url ($ file) qui obtient l'URL de ce fichier dans S3. Si vous utilisez cette fonction, assurez-vous que la liste de contrôle d'accès des fichiers téléchargés est «en lecture publique», sinon elle ne sera pas accessible à l'utilisateur.
Classe abstraite AWS_S3 {
// Continue d'en haut ...
fonction protégée get_bucket_url () {
$ region = $ this-> get_region ();
// La région de Virginie du Nord est simplement "s3", les autres exigent explicitement que la région
$ préfixe = $ région == 'us-east-1'? 's3': 's3 -'. $ région;
// Utilise le même schéma que la requête en cours
$ scheme = is_ssl ()? 'https': 'http';
// Utilisation du nom de compartiment dans le schéma de chemin
return $ scheme. ': //'.$prefix.'.amazonaws.com/'..thiethis-> get_bucket ();
}
fonction get_file_url ($ fichier) {
return $ this-> get_bucket_url (). $ this-> get_file_relative_path ($ file);
}
}
Ensuite, nous pouvons simplement obtenir l'URL du fichier sur S3 et imprimer l'image:
printf (
" ",
$ avatarcropper-> get_file_url ($ fichier)
)
",
$ avatarcropper-> get_file_url ($ fichier)
)
Listing Files
Si dans notre application, nous souhaitons autoriser l'utilisateur à afficher tous les avatars précédemment téléchargés, nous pouvons le faire. Pour cela, nous introduisons la fonction get_file_urls qui répertorie l’URL de tous les fichiers stockés sous un certain chemin (en termes S3, il s’agit d’un préfixe):
la classe abstraite AWS_S3 {
// Continue d'en haut ...
fonction get_file_urls (préfixe $) {
$ s3Client = $ this-> get_s3_client ();
$ result = $ s3Client-> listObjects (array (
'Bucket' => $ this-> get_bucket (),
'Préfixe' => $ préfixe
));
$ file_urls = array ();
if (isset ($ result ['Contents']) && count ($ result ['Contents'])> 0) {
foreach ($ résultat ['Contents'] en tant que $ obj) {
// Vérifier que Key est un chemin de fichier complet et pas seulement un "répertoire"
if ($ obj ['Key']! = $ prefix) {
$ file_urls [] = $ this-> get_bucket_url (). $ obj ['Key'];
}
}
}
return $ file_urls;
}
}
Ensuite, si nous stockons chaque avatar sous le chemin "/ users / $ {user_id} /", en passant ce préfixe, nous obtiendrons la liste de tous les fichiers:
$ user_id = get_current_user_id ();
$ prefix = "/ users / $ {user_id} /";
foreach ($ avatarcropper-> get_file_urls ($ prefix) as $ file_url) {
printf (
"",
$ file_url
)
}
Conclusion
Dans cet article, nous avons expliqué comment utiliser une solution de stockage d'objets cloud pour servir de référentiel commun afin de stocker les fichiers d'une application déployée sur plusieurs serveurs. Pour la solution, nous nous sommes concentrés sur AWS S3 et avons ensuite présenté les étapes à intégrer à l'application: création du compartiment, configuration des autorisations utilisateur, téléchargement et installation du SDK. Enfin, nous avons expliqué comment éviter les pièges de sécurité dans l’application. Nous avons également vu des exemples de code illustrant les opérations les plus élémentaires sur S3: le téléchargement, le téléchargement et la liste des fichiers, qui ne nécessitaient que quelques lignes de code chacune. La simplicité de la solution montre que l'intégration de services de cloud dans l'application n'est pas difficile et que des développeurs peu expérimentés dans le cloud peuvent le faire.
 (rb, ra, yk, il )
(rb, ra, yk, il ) Source link