Liste de contrôle de la performance frontend 2019 [PDF, Apple Pages, MS Word]
À propos de l'auteur
Vitaly Friedman aime les beaux contenus et n'aime pas céder facilement. Quand il n’écrit pas ou ne parle pas lors d’une conférence, il court probablement… Plus à propos de Vitaly
Faisons en 2019… vite! Une liste de contrôle annuelle des performances front-end (PDF / Apple Pages / MS Word), avec tout ce que vous devez savoir pour créer des expériences rapides aujourd'hui. Mis à jour depuis 2016.
Les performances Web sont une bête délicate, n’est-ce pas? Comment savons-nous réellement où nous en sommes en termes de performances et quels sont nos goulots d'étranglement en termes de performances exactement ? Est-ce un JavaScript coûteux, une livraison lente des polices sur le Web, des images lourdes ou un rendu lent? Cela vaut-il la peine d’explorer l’agrégation d’arbres, le levage de portées, le fractionnement de codes et tous les modèles de chargement fantaisistes avec Observateur d’intersection, serveur push, conseils aux clients, HTTP / 2, travailleurs de service et – oh mon – avantage? Et, plus important encore, où commençons-nous même à améliorer les performances et comment établissons-nous une culture de la performance à long terme?
À l'époque, la performance était souvent un après-coup . Souvent différé jusqu’à la fin du projet, cela se résumait à une minification, une concaténation, une optimisation des actifs et éventuellement à quelques ajustements précis dans le fichier de configuration du serveur. Rétrospectivement, les choses semblent avoir considérablement changé.
La performance n’est pas simplement un problème technique: elle compte et, lorsqu’elle est intégrée au flux de travail, les décisions de conception doivent être informées de leurs implications en termes de performances. Les performances doivent être mesurées, surveillées et améliorées en permanence et la complexité croissante du Web pose de nouveaux défis qui rendent difficile le suivi des métriques, car les métriques varient considérablement en fonction du périphérique, du navigateur, du protocole , type de réseau et latence (les CDN, les fournisseurs de services Internet, les caches, les proxies, les pare-feu, les équilibreurs de charge et les serveurs jouent tous un rôle dans les performances.)
Si vous créez une vue d'ensemble de tous les éléments à prendre en compte lors de l'amélioration performances - du tout début du processus jusqu'à la publication finale du site Web - à quoi ressemblerait cette liste? Vous trouverez ci-dessous une liste de contrôle de performance initiale pour 2019 (espérons-le objective et objective) - un aperçu actualisé des problèmes à prendre en compte pour garantir des temps de réponse rapides, une interaction fluide entre l'utilisateur et vos sites ne drainent pas la bande passante de l'utilisateur.
Préparatifs: planification et métriques [19659012] Les micro-optimisations sont excellentes pour maintenir les performances sur la bonne voie, mais il est essentiel de garder à l'esprit des objectifs clairement définis - objectifs mesurables susceptibles d'influer sur les décisions prises tout au long du processus. Il existe deux modèles différents, et ceux discutés ci-dessous ont une opinion bien arrêtée - assurez-vous simplement de définir vos propres priorités dès le début.
Établissez une culture de la performance Dans de nombreuses organisations, les développeurs front-end savent exactement quoi Les problèmes sous-jacents courants sont les modèles de chargement à utiliser pour les résoudre. Cependant, tant qu’il n’y aura pas d’approbation formelle de la culture de la performance, chaque décision deviendra un champ de bataille de ministères, divisant l’organisation en silos. Vous avez besoin d'un engagement des parties prenantes de l'entreprise et pour l'obtenir, vous devez établir une étude de cas sur la mesure dans laquelle les indicateurs de performance et les indicateurs clés de performance ( KPIs ) sont importants pour eux.
Sans un fort alignement entre les équipes de développement / conception et les équipes commerciales / marketing, la performance ne sera pas durable. Étudiez les réclamations courantes qui entrent en contact avec le service clientèle et voyez comment l'amélioration des performances peut aider à résoudre certains de ces problèmes courants.
Exécutez des expériences de performance et mesurez les résultats, sur votre mobile comme sur votre ordinateur de bureau. Cela vous aidera à construire une étude de cas personnalisée avec des données réelles. En outre, l'utilisation de données provenant d'études de cas et d'expériences publiées dans WPO Stats contribuera à sensibiliser davantage les entreprises aux raisons pour lesquelles les performances sont importantes et à l'impact qu'elles ont sur l'expérience utilisateur et les statistiques de l'entreprise. Dire que les performances importent à elles seules ne suffit pas cependant, vous devez également établir des objectifs mesurables et pouvant être suivis et les respecter.
Comment s'y rendre? Dans son exposé sur La performance du bâtiment à long terme Allison McKnight présente une étude de cas détaillée sur la manière dont elle a contribué à l'établissement d'une culture de la performance à Etsy ( slide ).
Objectif: être au moins 20% plus rapide que votre concurrent le plus rapide. Selon recherches psychologiques si vous voulez que les utilisateurs sentent que votre site Web est plus rapide que celui de votre concurrent, vous devez être au moins 20% plus rapide. Étudiez vos principaux concurrents, collectez des statistiques sur leurs performances sur les mobiles et les ordinateurs de bureau et définissez des seuils qui vous aideraient à les dépasser. Pour obtenir des résultats et des objectifs précis, commencez par étudier vos analyses afin de déterminer en quoi consistent vos utilisateurs. Vous pouvez ensuite imiter l’expérience du 90e centile pour les tests.
Note : Si vous utilisez Page Speed Insights (non, il n'est pas obsolète), vous pouvez obtenir les données de performances CrUX pour des pages spécifiques au lieu des seuls agrégats. Ces données peuvent être beaucoup plus utiles pour définir des objectifs de performance pour des actifs tels que «page de destination» ou «liste de produits». Et si vous utilisez CI pour tester les budgets, vous devez vous assurer que votre environnement testé correspond à CrUX si vous utilisez CrUX pour définir la cible (merci Patrick Meenan! ).
Collectez des données, configurez-les une feuille de calcul économisez 20% et fixez vos objectifs ( budgets de performance ) de cette façon. Vous avez maintenant quelque chose de mesurable à tester. Si vous gardez le budget à l'esprit et essayez d'exporter le script minimal pour obtenir un délai rapide d'interactivité, vous êtes sur une trajectoire raisonnable.
Vous avez besoin de ressources pour commencer?
Once vous avez un budget en place, intégrez-les dans votre processus de création avec Webpack Performance Hints and Bundlesize CI Lightouse PWMetrics ou Sitespeed CI pour appliquer les budgets sur les demandes de tirage et fournir un historique des scores dans les commentaires des relations publiques. Si vous avez besoin de quelque chose de personnalisé, vous pouvez utiliser webpagetest-charts-api une API de points de terminaison permettant de créer des graphiques à partir des résultats WebPagetest.
Par exemple, tout comme Pinterest vous pourriez créez une règle personnalisée eslint qui interdit l'importation à partir de fichiers et de répertoires connus pour être très dépendants et qui alourdiraient le paquet. Configurez une liste de paquets «sûrs» pouvant être partagés par toute l’équipe.
Au-delà des budgets de performance, pensez aux tâches client critiques les plus bénéfiques pour votre entreprise. Fixez et discutez des seuils de temps acceptables pour les actions critiques et établissez des marques de chronométrage pour l'utilisateur "UX ready" sur lesquelles l'ensemble de l'organisation a convenu. Dans de nombreux cas, les parcours des utilisateurs vont toucher le travail de nombreux départements différents. Par conséquent, un alignement sur les délais acceptables aidera à soutenir ou à empêcher les discussions sur les performances à venir. Assurez-vous que les coûts supplémentaires liés aux ressources et aux fonctionnalités ajoutées sont visibles et bien compris.
En outre, comme l’a suggéré Patrick Meenan, il est utile de de planifier une séquence de chargement et des compromis au cours du processus de conception. Si vous définissez en priorité les parties les plus critiques et définissez leur ordre d'apparition, vous saurez également ce qui peut être retardé. Idéalement, cette commande reflètera également la séquence de vos importations CSS et JavaScript, ce qui facilitera leur traitement pendant le processus de construction. En outre, considérez ce que l'expérience visuelle devrait être dans les états "entre-deux", pendant le chargement de la page (par exemple, lorsque les polices Web ne sont pas encore chargées).
Planification, planification, planification. Il serait peut-être tentant de se lancer rapidement dans des optimisations «faciles à mettre en œuvre» - et cela pourrait éventuellement être une bonne stratégie pour des victoires rapides - mais il sera très difficile de maintenir la priorité des performances sans planifier et définir de manière réaliste les performances.
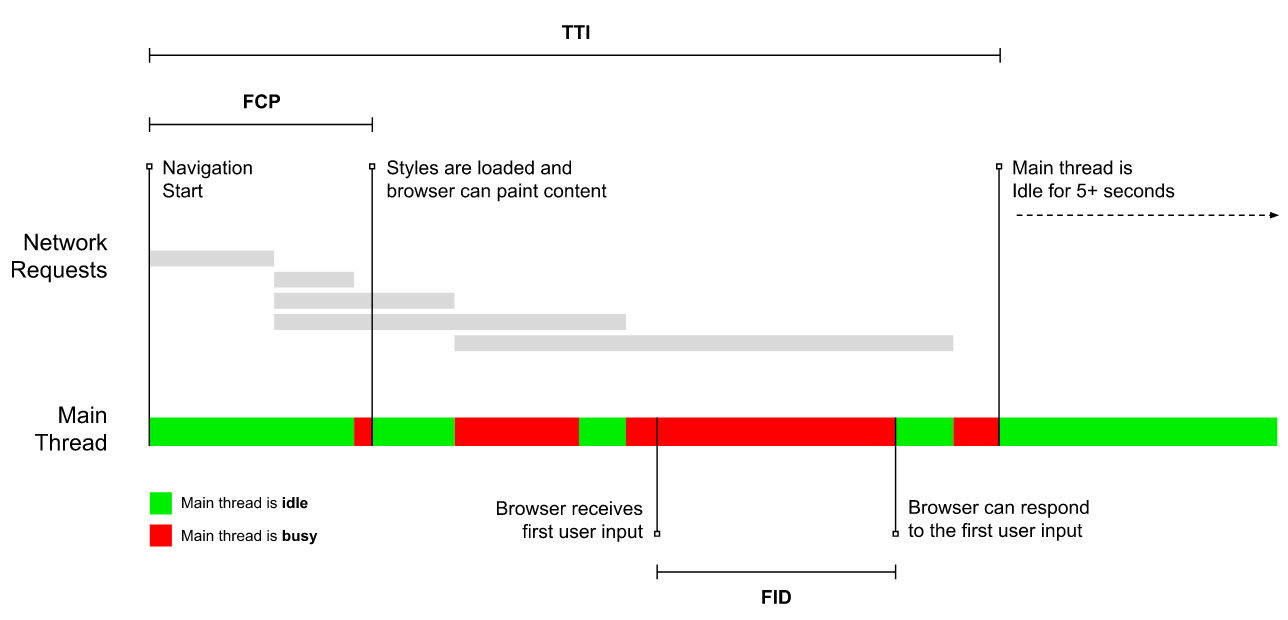
La différence entre la première peinture, la première peinture contenant le contenu, la première peinture significative, le visuel complet et le temps de l’interactivité. Vue agrandie . Crédit: @ denar90
Choisissez les bonnes métriques Toutes les métriques ne sont pas d'égale importance . Étudiez les métriques qui importent le plus pour votre application: elles sont généralement liées à la vitesse à laquelle vous pouvez commencer à restituer les pixels les plus importants de votre produit et à la rapidité avec laquelle vous pouvez fournir une réactivité d'entrée pour ces pixels restitués. Cette connaissance vous donnera la meilleure cible d'optimisation pour les efforts en cours.
D'une manière ou d'une autre, plutôt que de vous concentrer sur le temps de chargement complet de la page (via onLoad et DOMContentLoaded par exemple), donnez la priorité au chargement de page tel qu'il est perçu par vos clients. Cela signifie que vous devez vous concentrer sur un ensemble de métriques légèrement différent. En fait, choisir la bonne métrique est un processus sans vainqueurs évidents.
Selon les recherches de Tim Kadlec et les notes de Marcos Iglesias dans son exposé les métriques traditionnelles pourraient être regroupées en quelques ensembles. Habituellement, nous avons besoin de tous ces éléments pour obtenir un tableau complet des performances, et dans votre cas particulier, certains d’entre eux pourraient être plus importants que d’autres.
Les métriques basées sur les quantités mesurent le nombre de demandes, leur poids et leur valeur. un score de performance. Bon pour déclencher des alarmes et surveiller les changements au fil du temps, pas très bon pour comprendre l'expérience utilisateur.
Les métriques jalons utilisent des états dans la durée du processus de chargement, par ex. Heure du premier octet et Heure de l'interactivité . Bon pour décrire l'expérience utilisateur et la surveillance, pas très bon pour savoir ce qui se passe entre les jalons.
Les métriques de rendu fournissent une estimation de la rapidité de rendu du contenu (par exemple, Start Render . ] Indice de vitesse ). Bon pour mesurer et modifier les performances de rendu, mais pas pour mesurer quand un contenu important apparaît et qu'il peut être interagi avec ce dernier.
Les mesures personnalisées mesurent un événement personnalisé particulier pour l'utilisateur, par exemple. Twitter Time To First Tweet et Pinterest PinnerWaitTime . Bon pour décrire précisément l’utilisateur, mal pour mettre à l’échelle les métriques et comparer avec les concurrents.
Pour compléter le tableau, nous recherchions généralement des métriques utiles parmi tous ces groupes. Les plus spécifiques et les plus pertinents sont généralement les suivants:
Première peinture significative (FMP) Indique le moment où le contenu principal apparaît sur la page, donnant un aperçu de la rapidité avec laquelle le serveur génère tout données. Long FMP indique généralement que JavaScript bloque le thread principal, mais peut également être lié à des problèmes d'arrière-plan / serveur.
Time to Interactive (TTI) Le point auquel la présentation s'est stabilisée est défini par les principaux contrôles Web. visible, et le fil principal est suffisamment disponible pour gérer les entrées de l'utilisateur - essentiellement le repère temporel lorsqu'un utilisateur peut interagir avec l'interface utilisateur. Mesures essentielles pour comprendre combien attendent un utilisateur doit expérimenter pour utiliser le site sans retard
Index de vitesse Mesure la rapidité avec laquelle le contenu de la page est visuellement peuplé. plus le score est bas, mieux c'est. Le score de l’indice de vitesse est calculé en fonction de la vitesse du progrès visuel, mais il s’agit simplement d’une valeur calculée. Il est également sensible à la taille de la fenêtre d'affichage. Vous devez donc définir une gamme de configurations de test correspondant à votre public cible ( merci, Boris ! ).
Temps passé sur la CPU . ] Une métrique qui indique à quel point le thread principal est occupé par le traitement de la charge utile. Il montre combien de fois et combien de temps le thread principal est bloqué, travaillant sur la peinture, le rendu, les scripts et le chargement. Un temps de calcul élevé est un indicateur clair d’une expérience janky c’est-à-dire lorsque l’utilisateur subit un décalage notable entre son action et une réponse. Avec WebPageTest, vous pouvez sélectionner "Capturer la chronologie des outils de développement" sur l'onglet "Chrome" pour afficher le détail du thread principal lorsqu'il s'exécute sur tout périphérique utilisant WebPageTest.
Impact sur le poids de l'annonce Si votre site dépend des revenus générés par la publicité, il est utile de suivre le poids du code lié aux annonces. Le script de Paddy Ganti construit deux URL (une normale et une bloquant les publicités), invite à générer une comparaison vidéo via WebPageTest et signale un delta.
Métriques de déviation Comme noté par Ingénieurs Wikipedia les données sur les écarts dans vos résultats pourraient vous indiquer la fiabilité de vos instruments et le degré d’attention que vous devez porter aux déviations et aux dépassements. Une variance importante est un indicateur des ajustements nécessaires dans la configuration. Il est également utile de comprendre si certaines pages sont plus difficiles à mesurer de manière fiable, par exemple. en raison de scripts tiers provoquant une variation significative. Il peut également être judicieux de suivre la version du navigateur pour comprendre les baisses de performances lors du déploiement d'une nouvelle version du navigateur.
Métriques personnalisées Les métriques personnalisées sont définies par vos besoins métier et votre expérience client. Vous devez identifier les pixels importants les scripts critiques les éléments nécessaires CSS et les éléments pertinents et mesurer la rapidité avec laquelle ils sont remis à l'utilisateur. . Pour cela, vous pouvez surveiller Hero Rendering Times ou utiliser Performance API marquant des timestaps particuliers pour les événements importants pour votre entreprise. En outre, vous pouvez collecter des métriques personnalisées avec WebPagetest en exécutant du JavaScript arbitraire à la fin d'un test.
Steve Souders a une explication détaillée de chaque métrique . Il est important de noter que si le temps interactif est mesuré par l'exécution d'audits automatisés dans l'environnement de laboratoire le premier délai d'entrée représente l'expérience utilisateur de avec . utilisateurs réels connaissant un décalage notable. En général, il est probablement judicieux de toujours mesurer et suivre les deux.
Note : FID et TTI ne tiennent pas compte du comportement de défilement. le défilement peut se faire indépendamment puisqu'il est hors du fil principal, aussi, pour de nombreux sites de consommation de contenu, ces métriques sont peut-être beaucoup moins importantes ( merci, Patrick! ).
Les métriques de performance centrées sur l'utilisateur fournissent un meilleur aperçu. dans l'expérience utilisateur réelle. Le premier délai d'entrée (FID) est une nouvelle mesure qui tente précisément d'atteindre cet objectif. ( Grand aperçu )
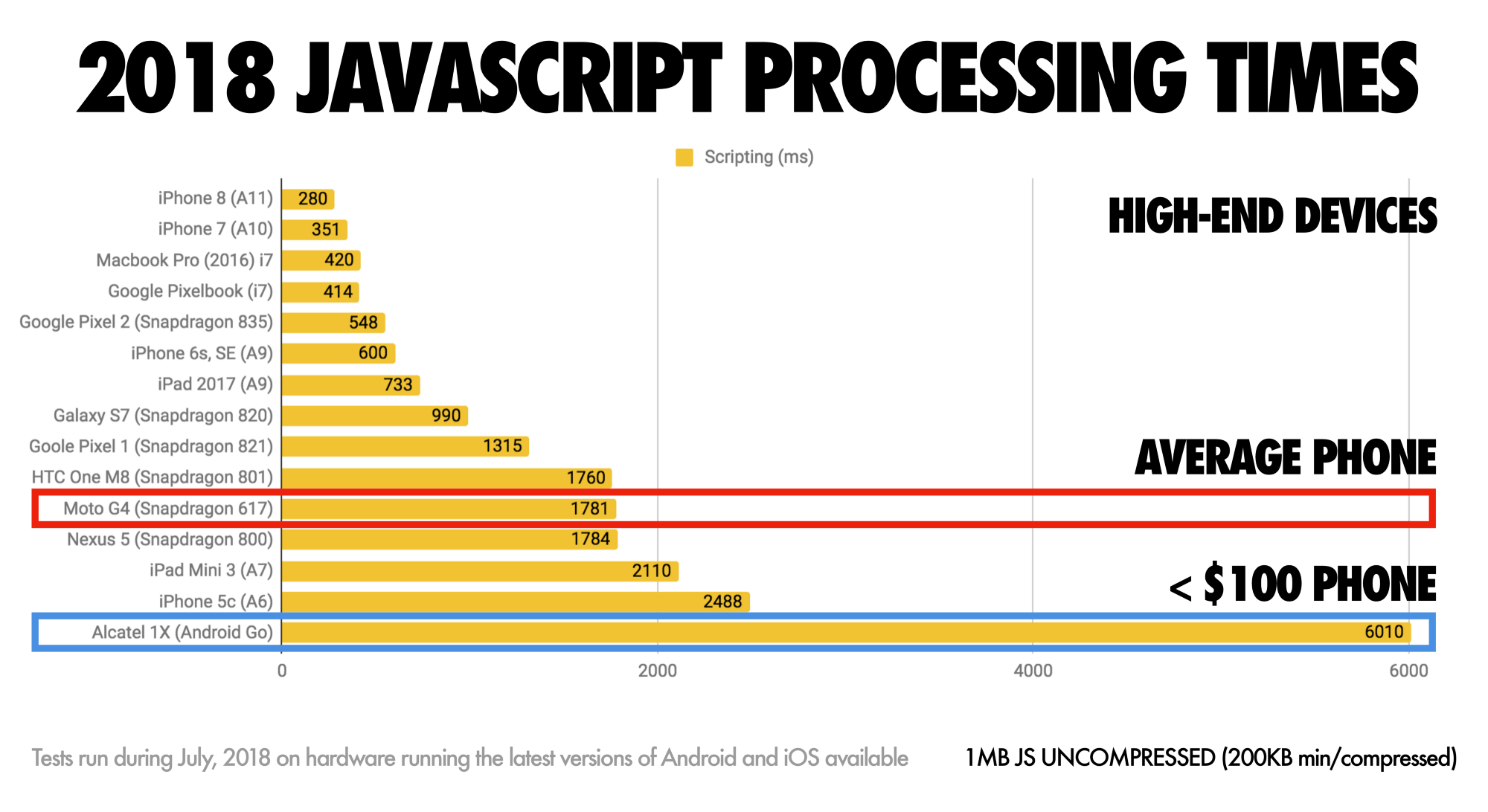
Collectez des données sur un périphérique représentant votre public Pour collecter des données précises, nous devons choisir soigneusement les périphériques sur lesquels effectuer les tests. C'est une bonne option pour de choisir un Moto G4 un périphérique Samsung de milieu de gamme, un bon périphérique milieu de route comme le Nexus 5X et un périphérique lent comme l'Alcatel 1X, peut-être dans un laboratoire ouvert pour appareils . Pour tester des appareils à régulation thermique plus lente, vous pouvez également vous procurer un Nexus 2, qui coûte environ 100 USD.
Si vous n’avez pas un appareil à portée de main, émulez l’expérience mobile sur le bureau en testant sur un réseau étranglé (par exemple, 150 ms RTT, 1,5 Mbps en baisse, 0,7 Mbps en hausse) avec un processeur étranglé (ralentissement 5 ×). Passez éventuellement aux réseaux 3G, 4G et Wi-Fi classiques. Pour que l'impact sur les performances soit plus visible, vous pouvez même introduire les mardis 2G ou configurer un réseau 3G étranglé dans votre bureau pour un test plus rapide.
N'oubliez pas que sur un téléphone portable appareil, vous devriez vous attendre à un ralentissement de 4 × –5 × par rapport aux ordinateurs de bureau. Les appareils mobiles ont des GPU, des processeurs, des mémoires et des caractéristiques de batterie différentes. Bien que les temps de téléchargement soient critiques pour les réseaux bas de gamme, les temps d'analyse sont critiques pour les téléphones dotés de processeurs lents. En fait, les temps d'analyse sur le mobile sont 36% plus élevés que sur le bureau . Donc toujours test sur un appareil moyen - un appareil très représentatif de votre public
Présentation du jour le plus lent de la semaine. Facebook a introduit les 2G mardi pour augmenter la visibilité et la sensibilité des connexions lentes. ( Source de l'image )
Heureusement, il existe de nombreuses options qui vous aident à automatiser la collecte de données et à mesurer les performances de votre site Web dans le temps, en fonction de ces métriques. N'oubliez pas qu'une bonne image de performances couvre un ensemble d'indicateurs de performance, données de laboratoire et données de terrain :
Les outils de test synthétique collectent les données de laboratoire dans un environnement reproductible avec appareil et paramètres réseau prédéfinis (par exemple, Lighthouse WebPageTest ) et
La surveillance des utilisateurs réels ( RUM ) permet d'évaluer les interactions de l'utilisateur en continu et collecter les données de terrain (par exemple SpeedCurve New Relic - les deux outils fournissent également des tests de synthèse)
Le premier est particulièrement utile pendant développement car il vous aidera à identifier, isoler et résoudre les problèmes de performances lorsque vous travaillez sur le produit. Ce dernier est utile pour la maintenance à long terme car il vous aidera à comprendre les goulots d'étranglement de vos performances lorsqu'ils se produisent en direct - lorsque les utilisateurs accèdent au site.
Configuration des profils "propres" et "clients" pour les tests. Lors de l'exécution de tests dans des outils de surveillance passive, il s'agit d'une stratégie courante pour désactiver les tâches antivirus et de processeur en arrière-plan, supprimer les transferts de bande passante en arrière-plan et effectuer des tests avec Nettoyez le profil de l'utilisateur sans les extensions du navigateur pour éviter des résultats biaisés ( Firefox Chrome ).
Cependant, il est également judicieux d’étudier les extensions fréquemment utilisées par vos clients et de les tester également avec un profil "client" dédié . En fait, certaines extensions peuvent avoir des conséquences importantes sur les performances de votre application, et si vos utilisateurs les utilisent beaucoup, vous voudrez peut-être en rendre compte dès le départ. Les résultats de profil "propres" sont à eux seuls trop optimistes et peuvent être écrasés dans des scénarios réels.
Partagez la liste de contrôle avec vos collègues. Assurez-vous que la liste de contrôle est familière à tous les membres de votre équipe pour éviter les malentendus. ligne. Chaque décision a des implications en termes de performances, et le projet bénéficierait énormément de la communication correcte par les développeurs front-end des valeurs de performances à l'ensemble de l'équipe, de sorte que tout le monde se sente responsable, pas seulement les développeurs front-end. Décisions de la conception de la carte par rapport au budget d'exécution et aux priorités définies dans la liste de contrôle.
Fixer des objectifs réalistes
Temps de réponse de 100 millisecondes, 60 ips. Pour qu'une interaction soit fluide, l'interface dispose de 100 ms pour répondre aux besoins de l'utilisateur. contribution. Plus longtemps que cela, et l'utilisateur perçoit l'application comme lente. RAIL, un modèle de performance centré sur l'utilisateur vous propose des objectifs sains: Pour permettre une réponse inférieure à 100 millisecondes, la page doit permettre au contrôle de revenir au thread principal au plus tard toutes les 50 millisecondes. La latence d'entrée estimée nous indique si nous atteignons ce seuil et, idéalement, il devrait être inférieur à 50 ms. Pour les points à haute pression tels que l’animation, il est préférable de ne rien faire d’autre que possible et le minimum absolu nécessaire. RAIL un modèle de performance centré sur l'utilisateur.
De plus, chaque image d'animation doit être terminée en moins de 16 millisecondes, ce qui permet d'atteindre 60 images par seconde (1 seconde ÷ 60 = 16,6 millisecondes), de préférence en moins de 10 millisecondes. Étant donné que le navigateur a besoin de temps pour peindre le nouveau cadre à l'écran, l'exécution de votre code doit être terminée avant d'atteindre la marque des 16,6 millisecondes. Nous commençons à avoir des conversations à propos de 120 images par seconde (par exemple, les nouveaux écrans d'iPad fonctionnent à 120 Hz) et Surma a couvert certaines solutions de performance de rendu pour 120 images par seconde mais ce n'est probablement pas une cible que nous examinons pour l'instant. .
Indice de vitesse <1250, TTI <5 sur 3G, budget de taille de fichier critique Bien qu'il puisse être très difficile à atteindre, un bon objectif ultime serait Première peinture significative inférieure à 1 seconde et valeur d'index de vitesse inférieure à 1250. Considérant que la référence est un téléphone Android à 200 USD (par exemple, Moto G4) sur un réseau 3G lent, émulé à une vitesse de transfert de 400 ms RTT et 400 kbps, visez Temps d'interactivité pour les moins de 5 ans et pour les visites répétées, visez moins de 2 ans (réalisable uniquement avec un travailleur de service),
Notez que lorsque vous parlez de métriques d’interactivité, c’est une bonne idée de de faire la distinction entre Premier processeur inactif et Time To Interactive afin d’éviter les malentendus sur la ligne. Le premier est le premier moment après le rendu du contenu principal (où il y a au moins une fenêtre de 5 secondes où la page est réactive). Ce dernier point est le point où on s'attend à ce que la page soit toujours sensible aux entrées ( merci, Philip Walton! ).
Nous avons deux contraintes majeures qui façonnent efficacement un raisonnable cible pour la livraison rapide du contenu sur le Web. D'une part, nous avons des contraintes de livraison du réseau en raison de TCP Slow Start . Les 14 premiers kilo-octets du code HTML sont> la partie la plus critique de la charge utile - et la seule partie du budget pouvant être fournie lors du premier aller-retour (tout ce que vous obtenez en 1 seconde à 400 ms RTT en raison du temps de réveil de votre mobile).
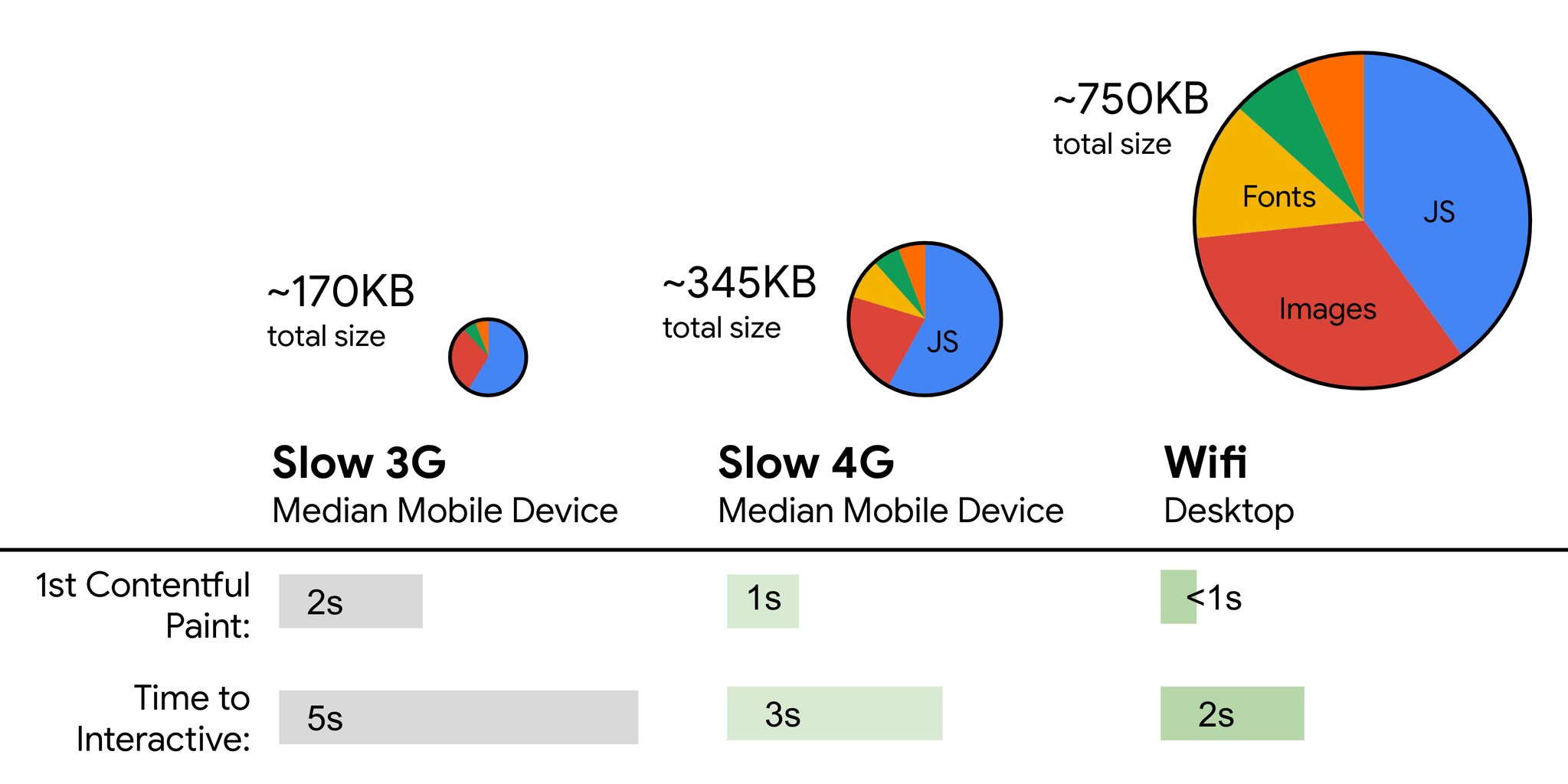
D'autre part, nous avons des contraintes matérielles sur la mémoire et le processeur en raison des temps d'analyse de JavaScript (nous en parlerons plus en détail ultérieurement). Pour atteindre les objectifs énoncés dans le premier paragraphe, nous devons examiner le budget critique de la taille de fichier pour JavaScript. Les avis varient sur ce que ce budget devrait être (et cela dépend fortement de la nature de votre projet), mais un budget de 170 Ko JavaScript déjà compressé prendrait jusqu'à 1 s pour être analysé et compilé sur un téléphone moyen. En supposant que 170 Ko s’étende à 3 × cette taille une fois décompressé (0,7 Mo), cela pourrait déjà sonner le glas d’une expérience utilisateur "décente" sur un Moto G4 ou un Nexus 2.
Bien sûr, vos données pourraient montrer que les clients ne sont pas sur ces appareils, mais peut-être ne font-ils tout simplement pas partie de vos analyses, car votre service leur est inaccessible en raison de performances médiocres. En fait, Alex Russels, de Google, recommande de viser 130-170KB compressés comme limite supérieure raisonnable et dépasser ce budget devrait être une décision éclairée et délibérée. Dans la réalité, la plupart des produits ne sont même pas proches: la taille moyenne d'un paquet est aujourd'hui d'environ 400 Ko ce qui représente une hausse de 35% par rapport à fin 2015. Sur un appareil mobile de la classe moyenne, cela représente 30-35 secondes pour Time-To-Interactive .
Nous pourrions aussi aller au-delà du budget par paquet. Par exemple, nous pourrions définir des budgets de performance basés sur les activités du fil principal du navigateur, c’est-à-dire le temps de peinture avant le début du rendu, ou pour suivre la trace des processeurs frontaux . Des outils tels que Calibre SpeedCurve et Bundlesize peuvent vous aider à contrôler vos budgets et peuvent être intégrés à votre processus de construction.
budget de performance ne devrait probablement pas être une valeur fixe. Selon la connexion réseau, les budgets de performances doivent être adaptés à mais la charge utile d'une connexion plus lente est beaucoup plus "coûteuse", quelle que soit la façon dont ils sont utilisés.
Choisissez et configurez vos outils de construction. Ne faites pas trop attention à ce qui est soi-disant cool de nos jours . Tenez-vous en à votre environnement pour construire, que ce soit Grunt, Gulp, Webpack, Parcel ou une combinaison d'outils. Tant que vous obtenez les résultats dont vous avez besoin et que vous n’avez aucun problème à maintenir votre processus de génération, vous vous en sortez parfaitement.
Parmi les outils de compilation, Webpack semble être l'outil le plus établi, avec littéralement des centaines de plug-ins disponibles pour optimiser la taille de vos générations. Bien démarrer avec Webpack peut être difficile. Donc, si vous voulez commencer, il existe d'excellentes ressources:
Exemples de Webpack en a des centaines de configurations Webpack prêtes à l'emploi, classées par sujet et par objectif. Bonus: il existe également un configurateur de configuration Webpack qui génère un fichier de configuration de base
awesome-webpack est une liste organisée de ressources, bibliothèques et outils Webpack utiles, notamment des articles, vidéos, cours, livres et exemples de projets angulaires, React et agnostiques dans un cadre.
Utilisez l’amélioration progressive comme valeur par défaut. Conservez l’optimisation progressive comme principe directeur de votre architecture frontale et le déploiement est une valeur sûre. Commencez par concevoir et développer l'expérience de base, puis enrichissez l'expérience avec des fonctionnalités avancées pour les navigateurs performants, en créant des expériences résilientes . If your website runs fast on a slow machine with a poor screen in a poor browser on a sub-optimal network, then it will only run faster on a fast machine with a good browser on a decent network.
Choose a strong performance baseline. With so many unknowns impacting loading — the network, thermal throttling, cache eviction, third-party scripts, parser blocking patterns, disk I/O, IPC latency, installed extensions, antivirus software and firewalls, background CPU tasks, hardware and memory constraints, differences in L2/L3 caching, RTTS — JavaScript has the heaviest cost of the experiencenext to web fonts blocking rendering by default and images often consuming too much memory. With the performance bottlenecks moving away from the server to the clientas developers, we have to consider all of these unknowns in much more detail.
As noted by Seb Markbåge, a good way to measure start-up costs for frameworks is to first render a view, then delete it and then render again as it can tell you how the framework scales. The first render tends to warm up a bunch of lazily compiled code, which a larger tree can benefit from when it scales. The second render is basically an emulation of how code reuse on a page affects the performance characteristics as the page grows in complexity.
It might sound obvious but worth stating: some projects can also benefit benefit from removing an existing framework altogether. Once a framework is chosen, you’ll be staying with it for at least a few years, so if you need to use one, make sure your choice is informed and well considered.
Inian Parameshwaran has measured performance footprint of top 50 frameworks (against First Contentful Paint — the time from navigation to the time when the browser renders the first bit of content from the DOM). Inian discovered that, out there in the wild, Vue and Preact are the fastest across the board — both on desktop and mobile, followed by React (slides). You could examine your framework candidates and the proposed architecture, and study how most solutions out there perform, e.g. with server-side rendering or client-side rendering, on average.
Baseline performance cost matters. According to a study by Ankur Sethi"your React application will never load faster than about 1.1 seconds on an average phone in India, no matter how much you optimize it. Your Angular app will always take at least 2.7 seconds to boot up. The users of your Vue app will need to wait at least 1 second before they can start using it." You might not be targeting India as your primary market anyway, but users accessing your site with suboptimal network conditions will have a comparable experience. In exchange, your team gains maintainability and developer efficiency, of course. But this consideration needs to be deliberate.
You could go as far as evaluating a framework (or any JavaScript library) on Sacha Greif’s 12-point scale scoring system by exploring features, accessibility, stability, performance, package ecosystem, community, learning curve, documentation, tooling, track record, team, compatibility, security for example. But on a tough schedule, it’s a good idea to consider at least the total cost on size + initial parse times before choosing an option; lightweight options such as PreactInfernoVueSvelte or Polymer can get the job done just fine. The size of your baseline will define the constraints for your application’s code.
A good starting point is to choose a good default stack for your application. Gatsby.js (React), Preact CLIand PWA Starter Kit provide reasonable defaults for fast loading out of the box on average mobile hardware.
Consider using PRPL pattern and app shell architecture. Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you’ll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand. An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
Have you optimized the performance of your APIs? APIs are communication channels for an application to expose data to internal and third-party applications via so-called endpoints. When designing and building an APIwe need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer (REST) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services.
As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering. When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
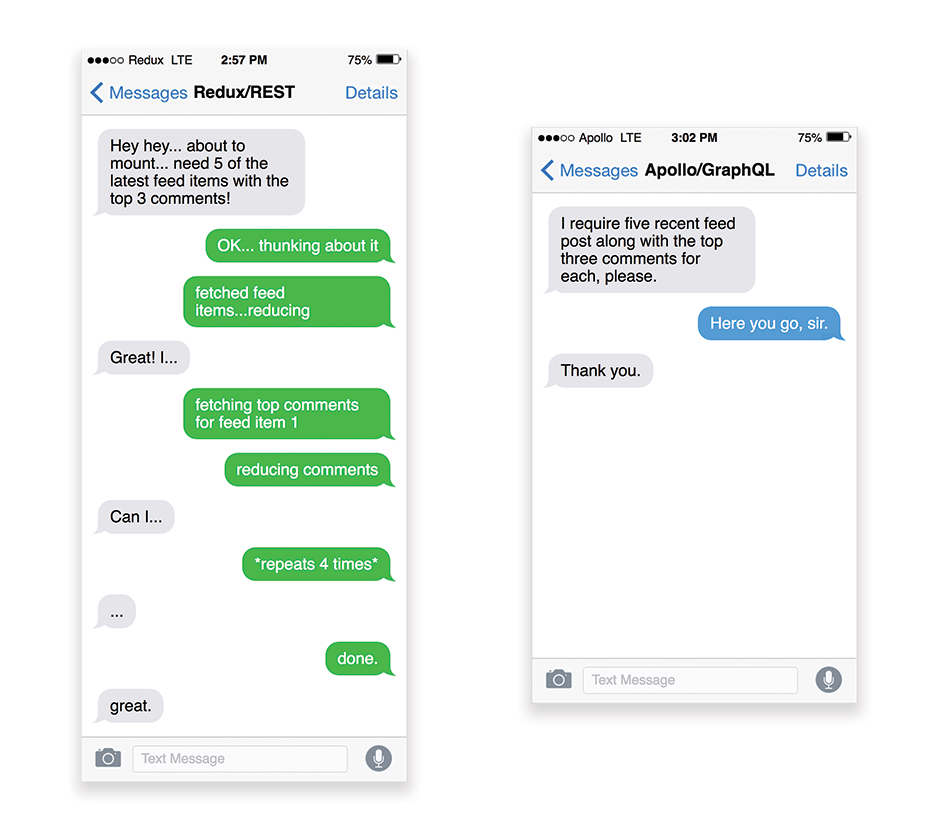
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request, and the response will be exactly what is required, without over or under-fetching data as it typically happens with REST.
A difference between REST and GraphQL, illustrated via a conversation between Redux + REST on the left, an Apollo + GraphQL on the right. (Image source: Hacker Noon) (Large preview)
Will you be using AMP or Instant Articles? Depending on the priorities and strategy of your organization, you might want to consider using Google’s AMP or Facebook’s Instant Articles or Apple’s Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.
The seemingly obvious benefit of these technologies for users is guaranteed performanceso at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don’t necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines. You could build progressive web AMPstoo, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs(thanks Addy, Jeremy!).
Choose your CDN wisely. Depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generatorpushing it to a CDN and serving a static version from it, thus avoiding database requests. You could even choose a static-hosting platform based on a CDN, enriching your pages with interactive components as enhancements (JAMStack). In fact, some of those generators (like Gatsby on top of React) are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.
Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (e.g. image optimization in terms of formats, compression and resizing at the edge), support for servers workersedge-side includes, which assemble static and dynamic parts of pages at the CDN’s edge (i.e. the server closest to the user), and other tasks.
Note: based on research by Patrick Meenan and Andy Davies, HTTP/2 is effectively broken on many CDNsso we shouldn’t be too optimistic about the performance boost there.
Assets Optimizations
Use Brotli or Zopfli for plain text compression. In 2015, Google introducedBrotlia new open-source lossless data format, which is now supported in all modern browsers. In practice, Brotli appears to be muchmore effective than Gzip and Deflate. It might be (very) slow to compress, depending on the settings, but slower compression will ultimately lead to higher compression rates. Still, it decompresses fast. You can also estimate Brotli compression savings for your site.
Browsers will accept it only if the user is visiting a website over HTTPS though. What’s the catch? Brotli still doesn’t come preinstalled on some servers today, and it’s not straightforward to set up without self-compiling Nginx. Still, it’s not that difficultand its support is coming, e.g. it’s available since Apache 2.4.26. Brotli is widely supported, and many CDNs support it (AkamaiAWSKeyCDNFastlyCloudlareCDN77) and you can enable Brotli even on CDNs that don’t support it yet (with a service worker).
At the highest level of compression, Brotli is so slow that any potential gains in file size could be nullified by the amount of time it takes for the server to begin sending the response as it waits to dynamically compress the asset. With static compression, however, higher compression settings are preferred.
Alternatively, you could look into using Zopfli’s compression algorithmwhich encodes data to Deflate, Gzip and Zlib formats. Any regular Gzip-compressed resource would benefit from Zopfli’s improved Deflate encoding because the files will be 3 to 8% smaller than Zlib’s maximum compression. The catch is that files will take around 80 times longer to compress. That’s why it’s a good idea to use Zopfli on resources that don’t change much, files that are designed to be compressed once and downloaded many times.
If you can bypass the cost of dynamically compressing static assets, it’s worth the effort. Both Brotli and Zopfli can be used for any plaintext payload — HTML, CSS, SVG, JavaScript, and so on.
The strategy? Pre-compress static assets with Brotli+Gzip at the highest level and compress (dynamic) HTML on the fly with Brotli at level 1–4. Make sure that the server handles content negotiation for Brotli or gzip properly. If you can’t install/maintain Brotli on the server, use Zopfli.
Use responsive images and WebP. As far as possible, use responsive images with srcsetsizes and the element. While you’re at it, you could also make use of the WebP format (supported in Chrome, Opera, Firefox 65, Edge 18) by serving WebP images with the element and a JPEG fallback (see Andreas Bovens' code snippet) or by using content negotiation (using Accept headers). Ire Aderinokun has a very detailed tutorial on converting images to WebPtoo.
It’s important to note that while WebP image file sizes compared to equivalent Guetzli and Zopflithe format doesn’t support progressive rendering like JPEGwhich is why users might see an actual image faster with a good ol' JPEG although WebP images might get faster through the network. With JPEG, we can serve a "decent" user experience with the half or even quarter of the data and load the rest later, rather than have a half-empty image as it is in the case of WebP. Your decision will depend on what you are after: with WebP, you’ll reduce the payload, and with JPEG you’ll improve perceived performance.
On Smashing Magazine, we use the postfix -opt for image names — for example, brotli-compression-opt.png; whenever an image contains that postfix, everybody on the team knows that the image has already been optimized. And — shameless plug! — Jeremy Wagner even published a Smashing book on WebP.
Are images properly optimized? When you’re working on a landing page on which it’s critical that a particular image loads blazingly fast, make sure that JPEGs are progressive and compressed with mozJPEG (which improves the start rendering time by manipulating scan levels) or GuetzliGoogle’s new open-source encoder focusing on perceptual performance, and utilizing learnings from Zopfli and WebP. The only downside: slow processing times (a minute of CPU per megapixel). For PNG, we can use Pingoand for SVG, we can use SVGO or SVGOMG. And if you need to quickly preview and copy or download all the SVG assets from a website, svg-grabber can do that for you, too.
Every single image optimization article would state it, but keeping vector assets clean and tight is always worth reminding. Make sure to clean up unused assets, remove unnecessary metadata and reduces the amount of path points in artwork (and thus SVG code). (Thanks, Jeremy!)
There are more advanced options though. You could:
Use Squoosh to compress, resize and manipulate images at the optimal compression levels (lossy or lossless),
To check the efficiency of your responsive markup, you can use imaging-heapa command line tool that measure the efficiency across viewport sizes and device pixel ratios.
Lazy load images and iframes with lazysizesa library that detects any visibility changes triggered through user interaction (or IntersectionObserver which we’ll explore later).
Watch out for images that are loaded by default, but might never be displayed — e.g. in carousels, accordions and image galleries.
Consider Swapping Images with the Sizes Attribute by specifying different image display dimensions depending on media queries, e.g. to manipulate sizes to swap sources in a magnifier component.
If you feel adventurous, you could chop and rearrange HTTP/2 streams using Edge workersbasically a real-time filter living on the CDN, to send images faster through the network. Edge workers use JavaScript streams that use chunks which you can control (basically they are JavaScript that runs on the CDN edge that can modify the streaming responses), so you can control the delivery of images. With service worker it’s too late as you can’t control what’s on the wire, but it does work with Edge workers. So you can use them on top of static JPEGs saved progressively for a particular landing page.
A sample output by imaging-heapa command line tool that measure the efficiency across viewport sizes and device pixel ratios. (Image source) (Large preview)
The future of responsive images might change dramatically with the adoption of client hints. Client hints are HTTP request header fields, e.g. DPRViewport-WidthWidthSave-DataAccept (to specify image format preferences) and others. They are supposed to inform the server about the specifics of user’s browser, screen, connection etc. As a result, the server can decide how to fill in the layout with appropriately sized images, and serve only these images in desired formats. With client hints, we move the resource selection from HTML markup and into the request-response negotiation between the client and server.
As Ilya Grigorik notedclient hints complete the picture — they aren’t an alternative to responsive images. "The element provides the necessary art-direction control in the HTML markup. Client hints provide annotations on resulting image requests that enable resource selection automation. Service Worker provides full request and response management capabilities on the client." A service worker could, for example, append new client hints headers values to the request, rewrite the URL and point the image request to a CDN, adapt response based on connectivity and user preferences, etc. It holds true not only for image assets but for pretty much all other requests as well.
For clients that support client hints, one could measure 42% byte savings on images and 1MB+ fewer bytes for 70th+ percentile. On Smashing Magazine, we could measure 19-32% improvementtoo. Unfortunately, client hints still have to gain some browser support. Under consideration in Firefox and Edge. However, if you supply both the normal responsive images markup and the tag for Client Hints, then the browser will evaluate the responsive images markup and request the appropriate image source using the Client Hints HTTP headers.
Not good enough? Well, you can also improve perceived performance for images with the multiplebackgroundimagestechnique. Keep in mind that playing with contrast and blurring out unnecessary details (or removing colors) can reduce file size as well. Ah, you need to enlarge a small photo without losing quality? Consider using Letsenhance.io.
These optimizations so far cover just the basics. Addy Osmani has published a very detailed guide on Essential Image Optimization that goes very deep into details of image compression and color management. For example, you could blur out unnecessary parts of the image (by applying a Gaussian blur filter to them) to reduce the file size, and eventually you might even start removing colors or turn the picture into black and white to reduce the size even further. For background images, exporting photos from Photoshop with 0 to 10% quality can be absolutely acceptable as well. Ah, and don’t use JPEG-XR on the web — "the processing of decoding JPEG-XRs software-side on the CPU nullifies and even outweighs the potentially positive impact of byte size savings, especially in the context of SPAs".
Are videos properly optimized? We covered images so far, but we’ve avoided a conversation about good ol' GIFs. Frankly, instead of loading heavy animated GIFs which impact both rendering performance and bandwidth, it’s a good idea to switch either to animated WebP (with GIF being a fallback) or replace them with looping HTML5 videos altogether. Yes, the browser performance is slow with and, unlike with images, browsers do not preload content, but they tend to be lighter and smaller than GIFs. Not an option? Well, at least we can add lossy compression to GIFs with Lossy GIFgifsicle or giflossy.
Addy Osmani recommends to replace animated GIFs with looping inline videos. The file size difference is noticeable (80% savings). (Large preview)
In the land of good news though, video formats have been advancing massively over the years. For a long time, we had hoped that WebM would become the format to rule them all, and WebP (which is basically one still image inside of the WebM video container) will become a replacement for dated image formats. But despite WebP and WebM gainingsupport these days, the breakthrough didn’t happen.
In 2018, the Alliance of Open Media has released a new promising video format called AV1. AV1 has compression similar to H.265 codec (the evolution of H.264) but unlike the latter, AV1 is free. The H.265 license pricing pushed browser vendors to adopting a comparably performant AV1 instead: AV1 (just like H.265) compress twice as good as WebP.
AV1 has good chances of becoming the ultimate standard for video on the web. (Image credit: Wikimedia.org) (Large preview)
In fact, Apple currently uses HEIF format and HEVC (H.265), and all the photos and videos on the latest iOS are saved in these formats, not JPEG. While HEIF and HEVC (H.265) aren’t properly exposed to the web (yet?), AV1 is — and it’s gaining browser support. So adding the AV1 source in your tag is reasonable, as all browser vendors seem to be on board.
For now, the most widely used and supported encoding is H.264, served by MP4 files, so before serving the file, make sure that your MP4s are processed with a multipass-encodingblurred with the frei0r iirblur effect (if applicable) and moov atom metadata is moved to the head of the file, while your server accepts byte serving. Boris Schapira provides exact instructions for FFmpeg to optimize videos to the maximum. Of course, providing WebM format as an alternative would help, too.
Video playback performance is a story on its own, and if you’d like to dive into it in details, take a look at Doug Sillar’s series on The Current State of Video and Video Delivery Best Practices that include details on video delivery metrics, video preloading, compression and streaming.
Are web fonts optimized? The first question that’s worth asking if you can get away with using UI system fonts in the first place. If it’s not the case, chances are high that the web fonts you are serving include glyphs and extra features and weights that aren’t being used. You can ask your type foundry to subset web fonts or if you are using open-source fonts, subset them on your own with Glyphhanger or Fontsquirrel. You can even automate your entire workflow with Peter Müller’s subfonta command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into your page.
WOFF2 support is great, and you can use WOFF as fallback for browsers that don’t support it — after all, legacy browsers would probably be served well enough with system fonts. There are many, many, many options for web font loading, and you can choose one of the strategies from Zach Leatherman’s "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with preload and "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don’t need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.
In general, it’s a good idea to use the preload resource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Otherwise, font loading will cost you in the first render time. Still, it might be a good idea to be selective and choose files that matter most, e.g. the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less-critical.
Nobody likes waiting for the content to be displayed. With the font-display CSS descriptorwe can control the font loading behavior and enable content to be readable immediately (font-display: optional) or almost immediately (font-display: swap). However, if you want to avoid text reflowswe still need to use the Font Loading API, specifically to group repaintsor when you are using third party hosts. Unless you can use Google Fonts with Cloudflare Workersof course. Talking about Google Fonts: consider using google-webfonts-helpera hassle-free way to self-host Google Fonts. Always self-host your fonts for maximum control if you can.
In general, if you use font-display: optionalit might not be a good idea to also use preload as it it’ll trigger that web font request early (causing network congestion if you have other critical path resources that need to be fetched). Use preconnect for faster cross-origin font requests, but be cautious with preload as preloading fonts from a different origin wlll incur network contention. All of these techniques are covered in Zach’s Web font loading recipes.
Also, it might be a good idea to opt out of web fonts (or at least second stage render) if the user has enabled Reduce Motion in accessibility preferences or has opted in for Data Saver Mode (see Save-Data header). Or when the user happens to have slow connectivity (via Network Information API).
To measure the web font loading performance, consider the All Text Visible metric (the moment when all fonts have loaded and all content is displayed in web fonts), as well as Web Font Reflow Count after first render. Obviously, the lower both metrics are, the better the performance is. It’s important to notice that variablefonts might require a significant performance consideration. They give designers a much broader design space for typographic choices, but it comes at the cost of a single serial request opposed to a number of individual file requests. That single request might be slow blocking the entire typographic appearance on the page. On the good side though, with a variable font in place, we’ll get exactly one reflow by default, so no JavaScript will be required to group repaints.
Now, what would make a bulletproof web font loading strategy? Subset fonts and prepare them for the 2-stage-render, declare them with a font-display descriptor, use Font Loading API to group repaints and store fonts in a persistent service worker’s cache. You could fall back to Bram Stein’s Font Face Observer if necessary. And if you’re interested in measuring the performance of font loading, Andreas Marschke explores performance tracking with Font API and UserTiming API.
Finally, don’t forget to include unicode-range to break down a large font into smaller language-specific fonts, and use Monica Dinculescu’s font-style-matcher to minimize a jarring shift in layout, due to sizing discrepancies between the fallback and the web fonts.
Build Optimizations
Set your priorities straight. It’s a good idea to know what you are dealing with first. Run an inventory of all of your assets (JavaScript, images, fonts, third-party scripts and "expensive" modules on the page, such as carousels, complex infographics and multimedia content), and break them down in groups.
Set up a spreadsheet. Define the basic core experience for legacy browsers (i.e. fully accessible core content), the enhanced experience for capable browsers (i.e. the enriched, full experience) and the extras (assets that aren’t absolutely required and can be lazy-loaded, such as web fonts, unnecessary styles, carousel scripts, video players, social media buttons, large images). A while back, we published an article on "Improving Smashing Magazine’s Performance," which describes this approach in detail.
When optimizing for performance we need to reflect our priorities. Load the core experience immediately, then enhancementsand then the extras.
Revisit the good ol' "cutting-the-mustard" technique. These days we can still use the cutting-the-mustard technique to send the core experience to legacy browsers and an enhanced experience to modern browsers. An updated variant of the technique would use ES2015+




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















