


{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Le guide ultime pour la construction de grattoirs Web évolutifs avec Scrapy
La récupération Web est un moyen de récupérer des données sur des sites Web sans avoir besoin d’accéder aux API ou à la base de données du site. Vous devez uniquement accéder aux données du site – tant que votre navigateur peut accéder aux données, vous serez en mesure de les effacer.
De manière réaliste, la plupart du temps, il vous suffit de consulter un site Web et de récupérer les données "par manuellement avec copier-coller, mais dans de nombreux cas, cela vous prendrait de nombreuses heures de travail manuel, ce qui pourrait vous coûter beaucoup plus que la valeur des données, surtout si vous avez embauché quelqu'un pour faire la tâche vous. Pourquoi embaucher quelqu'un pour travailler 1 à 2 minutes par requête quand un programme effectue automatiquement une requête toutes les quelques secondes?
Par exemple, supposons que vous souhaitiez compiler une liste des gagnants des Oscars pour obtenir la meilleure image possible. avec leur réalisateur, les acteurs principaux, la date de sortie et la durée. En utilisant Google, vous pouvez voir que plusieurs sites répertorient ces films par nom et peut-être quelques informations supplémentaires, mais vous devrez généralement suivre avec des liens pour capturer toutes les informations souhaitées.
pas pratique et fastidieux de parcourir tous les liens de 1927 à nos jours et d’essayer manuellement de trouver les informations sur chaque page. Avec le Web scraping, nous devons simplement trouver un site Web avec des pages contenant toutes ces informations, puis orienter notre programme dans la bonne direction avec les instructions appropriées.
Dans ce didacticiel, nous utiliserons Wikipedia comme site Web car il contient. toutes les informations dont nous avons besoin et utilisons ensuite Scrapy sur Python comme outil pour collecter nos informations.
Quelques mises en garde avant de commencer:
Le regroupement des données implique une augmentation de la charge du serveur pour le site que vous collectez, ce qui signifie un coût plus élevé pour les entreprises hébergeant le site et une expérience de moindre qualité pour les autres utilisateurs de ce site. La qualité du serveur qui exécute le site Web, la quantité de données que vous essayez d’obtenir et la vitesse à laquelle vous envoyez des demandes au serveur vont atténuer l’effet que vous avez sur le serveur. Gardant cela à l'esprit, nous devons nous conformer à quelques règles.
La plupart des sites ont également un fichier appelé robots.txt dans leur répertoire principal. Ce fichier établit des règles pour les répertoires auxquels les sites ne veulent pas que les scrapeurs aient accès. La page Conditions générales d’un site Web vous indique généralement quelle est sa politique en matière de récupération de données. Par exemple, la page Conditions d’IMDB contient la clause suivante:
Robots et nettoyage d’écrans: vous ne pouvez pas utiliser d’exploration de données, de robots, d’écrans d’écran ni d’outils similaires de collecte et d’extraction de données sur ce site, sauf autorisation expresse écrite de notre part.
Avant d'essayer d'obtenir les données d'un site Web, nous devrions toujours consulter les conditions du site Web et robots.txt pour nous assurer d'obtenir les données juridiques. Lors de la construction de nos grattoirs, nous devons également veiller à ne pas submerger un serveur de requêtes qu’il ne peut pas traiter.
Heureusement, de nombreux sites Web reconnaissent le besoin pour les utilisateurs d’obtenir des données et les rendent disponibles via Apis. Si ceux-ci sont disponibles, il est généralement beaucoup plus facile d'obtenir des données via l'API que via le grattage.
Wikipedia permet le grattage des données, tant que les robots ne vont pas «trop vite», comme spécifié dans leur . ] robots.txt . Ils fournissent également des ensembles de données téléchargeables afin que les utilisateurs puissent traiter les données sur leurs propres ordinateurs. Si nous allons trop vite, les serveurs bloquent automatiquement notre IP, nous allons donc mettre en place des minuteries afin de respecter leurs règles.
Pour commencer, Installation des bibliothèques pertinentes à l'aide de Pip
Tout d'abord, pour commencer, installons Scrapy.
Windows
Installez la dernière version de Python à partir de https://www.python.org/downloads/windows/
Note: Windows. Les utilisateurs auront également besoin de Microsoft Visual C ++ 14.0, que vous pouvez obtenir à partir de «Outils de compilation Microsoft Visual C ++» sur ici .
. Vous devez également vous assurer de disposer de la dernière version de pip.
Dans cmd.exe tapez:
python -m pip install --upgrade pip
pip installer pypiwin32
pip installer scrapy
Ceci installera automatiquement Scrapy et toutes les dépendances.
Linux
D'abord, vous voudrez installer toutes les dépendances:
Dans Terminal, entrez:
sudo apt-get install python3 python3- dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
Une fois que tout est installé, il suffit de taper:
pip install --upgrade pip
Pour vous assurer que pip est mis à jour, puis:
pip install scrapy
Et tout est terminé.
Mac
Vous devez d’abord vous assurer que vous avez un compilateur C sur votre système. Dans Terminal, entrez:
xcode-select --install
Ensuite, installez homebrew à partir de https://brew.sh/ .
Mettez à jour votre variable PATH afin que les packages homebrew soient utilisés avant les packages système:
echo "export PATH = / usr / local / bin: / usr / local / sbin: $ PATH ">> ~ / .bashrc
source ~ / .bashrc
Installez Python:
Préparez-vous à installer Python
Ensuite, assurez-vous que tout est mis à jour:
brasser mise à jour; brassage de python
Ensuite, installez Scrapy à l’aide de pip:
pip install Scrapy
>
Vue d'ensemble de Scrapy, comment les morceaux s'emboîtent, analyseurs syntaxiques, araignées, etc.
Vous allez écrire un script appelé "Araignée" pour que Scrapy s'exécute, mais ne vous inquiétez pas, Scrapy araignées aren pas effrayant du tout malgré leur nom. La seule similitude entre les araignées et les araignées réelles est qu'ils aiment ramper sur le Web.
À l'intérieur de l'araignée se trouve une classe que vous définissez et qui indique à Scrapy quoi faire. Par exemple, où commencer l’exploration, les types de demandes qu’il fait, comment suivre les liens sur les pages et comment il analyse les données. Vous pouvez même ajouter des fonctions personnalisées pour traiter également les données, avant de les restituer dans un fichier.
Écrire votre première araignée, écrire une simple araignée pour permettre un apprentissage pratique
Pour démarrer notre première araignée, nous devons commencez par créer un projet Scrapy. Pour ce faire, entrez ceci dans votre ligne de commande:
scrapy startproject oscars
Ceci créera un dossier avec votre projet.
Nous commencerons par une araignée de base. Le code suivant doit être entré dans un script python. Ouvrez un nouveau script python dans / oscars / spiders et nommez-le oscars_spider.py
Nous importons Scrapy.
import scrapy
Nous commençons ensuite à définir notre classe Spider. Tout d'abord, nous définissons le nom, puis les domaines que l'araignée est autorisée à gratter. Enfin, nous indiquons à l’araignée par où commencer le grattage.
class OscarsSpider (scrapy.Spider):
nom = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']
Ensuite, nous avons besoin d'une fonction qui capturera les informations souhaitées. Pour le moment, nous allons simplement récupérer le titre de la page. Nous utilisons CSS pour trouver la balise qui porte le texte du titre, puis nous l’extrayons. Enfin, nous renvoyons les informations à Scrapy pour qu'elles soient consignées ou écrites dans un fichier.
def parse (self, response):
data = {}
data ['title'] = response.css ('title :: text'). extract ()
données de rendement
Enregistrez maintenant le code dans /oscars/spiders/oscars_spider.py
Pour exécuter cette araignée, accédez simplement à votre ligne de commande et tapez:
scrapy crawl oscars
Vous devriez voir une sortie comme celle-ci:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 commencé (bot: oscars)
...
2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: aucun)
2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: aucun)
2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: gratté de
{'titre': ['Academy Award for Best Picture - Wikipedia']}
2019-05-02 14:39:34 [scrapy.core.engine] INFO: Araignée en train de se fermer (fini)
2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader / request_bytes': 589,
'downloader / request_count': 2,
'downloader / request_method_count / GET': 2,
'downloader / response_bytes': 74517,
'downloader / response_count': 2,
'downloader / response_status_count / 200': 2,
'finish_reason': 'terminé',
'finish_time': datetime.datetime (2019, 5, 2, 7, 39, 34, 264319),
'item_scraped_count': 1,
'log_count / DEBUG': 3,
'log_count / INFO': 9,
'response_received_count': 2,
'robotstxt / request_count': 1,
'robotstxt / response_count': 1,
'robotstxt / response_status_count / 200': 1,
'ordonnanceur / mis en attente': 1,
'ordonnanceur / mis en file d'attente / mémoire': 1,
'ordonnanceur / mis en file d'attente': 1,
'ordonnanceur / mis en file d'attente / mémoire': 1,
'heure_début': datetime.datetime (2019, 5, 2, 7, 39, 31, 431535)}
2019-05-02 14:39:34 [scrapy.core.engine] INFORMATION: Araignée fermée (finie)
Félicitations, vous avez construit votre premier grattoir Scrapy de base!
Code complet:
import scrapy
classe OscarsSpider (scrapy.Spider):
nom = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
def parse (auto, réponse):
data = {}
data ['title'] = response.css ('title :: text'). extract ()
données de rendement
Nous voulons évidemment qu’il en fasse un peu plus, alors voyons comment utiliser Scrapy pour analyser les données.
Commençons par nous familiariser avec le shell Scrapy. Le shell Scrapy peut vous aider à tester votre code pour vous assurer que Scrapy récupère les données souhaitées.
Pour accéder au shell, entrez-le dans votre ligne de commande:
scrapy shell “https: //en.wikipedia. org / wiki / Academy_Award_for_Best_Picture ”
Ceci ouvrira la page vers laquelle vous l’avez dirigé et vous permettra d’exécuter des lignes de code simples. Par exemple, vous pouvez afficher le code HTML brut de la page en tapant:
print (response.text)
Ou ouvrez la page dans votre navigateur par défaut en tapant:
vue (réponse)
Notre objectif ici est de trouver le code contenant les informations souhaitées. Pour l’instant, essayons de ne saisir que les noms de titre de film.
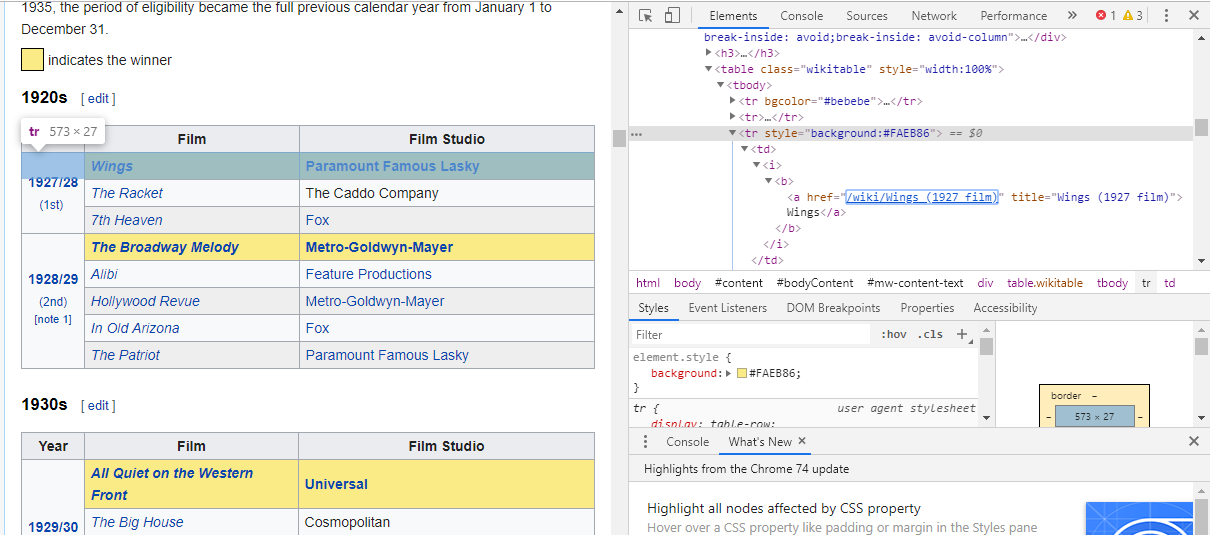
Le moyen le plus simple de trouver le code dont nous avons besoin est d’ouvrir la page dans notre navigateur et de le contrôler. Dans cet exemple, j'utilise Chrome DevTools. Il vous suffit de cliquer avec le bouton droit de la souris sur un titre de film et de sélectionner "inspecter":

Comme vous pouvez le constater, les lauréats des Oscars ont un fond jaune tandis que les nominés ont un fond uni. Il existe également un lien vers l’article sur le titre du film et les liens pour les films se terminent par film) . Maintenant que nous savons cela, nous pouvons utiliser un sélecteur CSS pour récupérer les données. Dans le shell Scrapy, tapez:
response.css (r "tr [style='background:#FAEB86'] a [href*='film)']"). Extract ()
Comme vous pouvez le constater, vous avez maintenant la liste de tous les lauréats des Oscars du meilleur film!
> response.css (r "tr [style='background:#FAEB86'] a [href*='film']"). Extract ()
[' Wings ',
...
' Livre Vert ', ' Jim Burke ']
Pour en revenir à notre objectif principal, nous voulons une liste des gagnants des Oscars du meilleur film, avec leur réalisateur, leurs acteurs principaux, leur date de sortie et leur durée. Pour ce faire, nous avons besoin de Scrapy pour récupérer les données de chacune de ces pages de film.
Nous devrons réécrire quelques éléments et ajouter une nouvelle fonction, mais ne vous inquiétez pas, c'est assez simple.
Nous ' Commencez par lancer le grattoir de la même manière que précédemment.
import scrapy, time
classe OscarsSpider (scrapy.Spider):
nom = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
Mais cette fois, deux choses vont changer. Tout d’abord, nous allons importer le temps avec scrapy car nous souhaitons créer une minuterie pour limiter la vitesse de raclage du bot. En outre, lorsque nous analysons les pages pour la première fois, nous souhaitons uniquement obtenir une liste des liens vers chaque titre, afin de pouvoir récupérer des informations sur ces pages.
def parse (self, response):
pour href dans response.css (r "tr [style='background:#FAEB86'] a [href*='film)'] :: attr (href)"). extract ():
url = response.urljoin (href)
print (url)
req = scrapy.Request (url, callback = self.parse_titles)
temps.sommeil (5)
rendement req
Nous faisons ici une boucle pour rechercher tous les liens de la page qui se terminent par film avec le fond jaune, puis nous joignons ces liens dans une liste d'URL que nous vous ferons parvenir. à la fonction parse_titles pour passer plus loin. Nous glissons également dans une minuterie pour qu'il ne demande que des pages toutes les 5 secondes. N'oubliez pas que nous pouvons utiliser le shell Scrapy pour tester nos champs response.css afin de nous assurer que nous obtenons les données correctes!
def parse_titles (self, response):
pour sel dans response.css ('html'). extract ():
data = {}
data ['title'] = response.css (r "h1 [id='firstHeading'] i :: text"). extract ()
data ['director'] = response.css (r "tr: contient ('Dirigé par') a [href*='/wiki/'] :: text"). extract ()
data ['starring'] = response.css (r "tr: contient ('en vedette') un [href*='/wiki/'] :: text"). extract ()
data ['releasedate'] = response.css (r "tr: contient ('Date de publication') li :: text"). extract ()
data ['runtime'] = response.css (r "tr: contient ('Temps d'exécution') td :: text"). extract ()
données de rendement
Le véritable travail est effectué dans notre fonction parse_data dans laquelle nous créons un dictionnaire appelé data puis remplissons chaque clé avec les informations souhaitées. Encore une fois, tous ces sélecteurs ont été trouvés avec Chrome DevTools, comme indiqué précédemment, puis testés avec le shell Scrapy.
La dernière ligne renvoie le dictionnaire de données à Scrapy pour y être stocké.
Code complet:
import scrapy, time
classe OscarsSpider (scrapy.Spider):
nom = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
def parse (auto, réponse):
pour href dans response.css (r "tr [style='background:#FAEB86'] a [href*='film)'] :: attr (href)"). extract ():
url = response.urljoin (href)
print (url)
req = scrapy.Request (url, callback = self.parse_titles)
temps.sommeil (5)
rendement req
def parse_titles (auto, réponse):
pour sel dans response.css ('html'). extract ():
data = {}
data ['title'] = response.css (r "h1 [id='firstHeading'] i :: text"). extract ()
data ['director'] = response.css (r "tr: contient ('Dirigé par') a [href*='/wiki/'] :: text"). extract ()
data ['starring'] = response.css (r "tr: contient ('en vedette') un [href*='/wiki/'] :: text"). extract ()
data ['releasedate'] = response.css (r "tr: contient ('Date de publication') li :: text"). extract ()
data ['runtime'] = response.css (r "tr: contient ('Temps d'exécution') td :: text"). extract ()
données de rendement
Parfois, nous voudrons utiliser des proxies car les sites Web tenteront de bloquer nos tentatives de grattage.
Pour ce faire, il suffit de changer quelques petites choses. En utilisant notre exemple, dans notre def parse () nous devons le changer comme suit:
def parse (self, response):
pour href dans (r "tr [style='background:#FAEB86'] a [href*='film)'] :: attr (href)"). extract ()
:
url = response.urljoin (href)
print (url)
req = scrapy.Request (url, callback = self.parse_titles)
req.meta ['proxy'] = "http://yourproxy.com:80"
rendement req
Les demandes seront acheminées via votre serveur proxy.
Déploiement et journalisation: indiquez comment gérer réellement une araignée en production
Il est maintenant temps de lancer notre araignée. Pour que Scrapy commence à gratter puis à la sortie dans un fichier CSV, entrez ce qui suit dans votre invite de commande:
scrapy crawl oscars -o oscars.csv
Vous verrez une sortie volumineuse et, au bout de quelques minutes, elle sera terminée et vous aurez un fichier CSV dans votre dossier de projet.
Lorsque vous ouvrez le fichier CSV, vous verrez toutes les informations souhaitées (triées par colonnes avec en-têtes). C’est vraiment aussi simple que cela.

Grâce au raclage des données, nous pouvons obtenir presque tous les ensembles de données personnalisés de notre choix, à condition que les informations soient accessibles au public. Ce que vous voulez faire avec ces données dépend de vous. Cette compétence est extrêmement utile pour effectuer des études de marché, mettre à jour les informations sur un site Web et bien d’autres choses.
Il est assez facile de configurer votre propre scraper Web pour obtenir vous-même des jeux de données personnalisés. Cependant, n'oubliez pas qu'il peut être d'autres moyens d'obtenir les données dont vous avez besoin. Les entreprises investissent énormément dans la fourniture des données souhaitées, il est donc juste que nous respections leurs conditions générales.
Ressources supplémentaires pour apprendre davantage sur le scrapbooking et le Web Scraping en général
 (dm, yk, il)
(dm, yk, il) Source link