
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
La ruée vers la commercialisation de l'IA crée des risques de sécurité majeurs

Lors de la Conférence internationale sur les représentations d'apprentissage (ICLR) de cette année, une équipe de chercheurs de l'Université du Maryland a présenté une technique d'attaque destinée à ralentir les modèles d'apprentissage en profondeur qui ont été optimisés pour des opérations rapides et sensibles. L'attaque, bien nommée DeepSloth, cible les « réseaux de neurones profonds adaptatifs », une gamme d'architectures d'apprentissage en profondeur qui réduisent les calculs pour accélérer le traitement.
Les dernières années ont vu un intérêt croissant pour la sécurité de l'apprentissage automatique et de l'apprentissage profond. learninget il existe de nombreux articles et techniques sur le piratage et la défense des réseaux de neurones. Mais une chose rendait DeepSloth particulièrement intéressant : les chercheurs de l'Université du Maryland présentaient une vulnérabilité dans une technique qu'ils avaient eux-mêmes développée deux ans plus tôt.
À certains égards, l'histoire de DeepSloth illustre les défis auxquels la communauté de l'apprentissage automatique est confrontée. . D'une part, de nombreux chercheurs et développeurs se bousculent pour rendre le deep learning accessible à différentes applications. D'un autre côté, leurs innovations créent de nouveaux défis qui leur sont propres. Et ils doivent rechercher activement et relever ces défis avant qu'ils ne causent des dommages irréparables.
Réseaux profonds peu profonds
L'un des plus grands obstacles à l'apprentissage en profondeur des coûts de calcul de la formation et de l'exploitation des réseaux de neurones profonds. De nombreux modèles d'apprentissage en profondeur nécessitent d'énormes quantités de mémoire et de puissance de traitement, et ne peuvent donc fonctionner que sur des serveurs dotés de ressources abondantes. Cela les rend inutilisables pour les applications qui nécessitent que tous les calculs et données restent sur les appareils périphériques ou nécessitent une inférence en temps réel et ne peuvent pas se permettre le retard causé par l'envoi de leurs données à un serveur cloud.
Au cours des dernières années, la machine les chercheurs en apprentissage ont développé plusieurs techniques pour rendre les réseaux de neurones moins coûteux. Une gamme de techniques d'optimisation appelée « architecture à sorties multiples » arrête les calculs lorsqu'un réseau de neurones atteint une précision acceptable. Les expériences montrent que pour de nombreuses entrées, vous n'avez pas besoin de parcourir toutes les couches du réseau de neurones pour prendre une décision définitive. Les réseaux de neurones à sorties multiples économisent les ressources de calcul et contournent les calculs des couches restantes lorsqu'ils ont confiance en leurs résultats.

En 2019, Yigitan Kaya, titulaire d'un doctorat. étudiant en informatique à l'Université du Maryland, a développé une technique à sorties multiples appelée « réseau peu profond », qui pourrait réduire le coût moyen d'inférence des réseaux de neurones profonds jusqu'à 50 %. Les réseaux peu profonds résolvent le problème de la « réflexion excessive », où les réseaux de neurones profonds commencent à effectuer des calculs inutiles qui entraînent une consommation d'énergie inutile et dégradent les performances du modèle. Le réseau peu profond a été accepté lors de la Conférence internationale sur l'apprentissage automatique (ICML) de 2019
"Les modèles de sortie précoce sont un concept relativement nouveau, mais il y a un intérêt croissant", Tudor Dumitras, conseiller de recherche et professeur agrégé de Kaya. à l'Université du Maryland, a déclaré TechTalks. « C'est parce que les modèles d'apprentissage en profondeur deviennent de plus en plus coûteux en calcul, et les chercheurs cherchent des moyens de les rendre plus efficaces. »
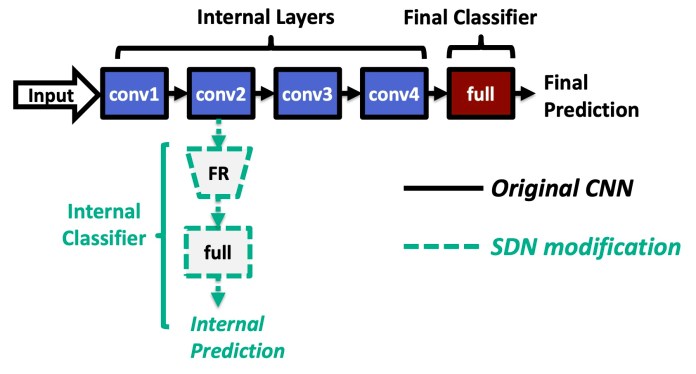
Les réseaux peu profonds contournent les calculs des réseaux neuronaux et sort lorsqu'ils atteignent un seuil d'acceptabilité.

Dumitras a une formation en cybersécurité et est également membre du Maryland Cybersecurity Center. Au cours des dernières années, il a mené des recherches sur les menaces de sécurité pour les systèmes d'apprentissage automatique. Mais alors qu'une grande partie du travail sur le terrain se concentre sur les attaques adverses, Dumitras et ses collègues étaient intéressés à trouver tous les vecteurs d'attaque possibles qu'un adversaire pourrait utiliser contre les systèmes d'apprentissage automatique. Leur travail a couvert divers domaines, y compris les défauts matériels les attaques par canal latéral de cache, les bogues logiciels et d'autres types d'attaques sur les réseaux de neurones.
Tout en travaillant sur le réseau profond et peu profond avec Kaya, Dumitras et ses collègues ont commencé à réfléchir aux manières néfastes dont la technique pourrait être exploitée.
« Nous nous sommes alors demandé si un adversaire pouvait forcer le système à trop réfléchir ; en d'autres termes, nous voulions voir si la latence et les économies d'énergie fournies par les modèles de sortie précoce comme le SDN sont robustes contre les attaques », a-t-il déclaré.
Attaques par ralentissement sur les réseaux de neurones


Dumitras a commencé à explorer les attaques par ralentissement sur les réseaux peu profonds avec Ionut Modoranu, alors stagiaire en recherche en cybersécurité à l'Université de Maryland. Lorsque les travaux initiaux ont montré des résultats prometteurs, Kaya et Sanghyun Hong, un autre Ph.D. étudiant à l'Université du Maryland, s'est joint à l'effort. Leurs recherches ont finalement abouti à l'attaque DeepSloth.
Comme les attaques contradictoires, DeepSloth s'appuie sur des entrées soigneusement conçues qui manipulent le comportement des systèmes d'apprentissage automatique. Cependant, alors que les exemples contradictoires classiques forcent le modèle cible à faire des prédictions erronées, DeepSloth perturbe les calculs. L'attaque DeepSloth ralentit les réseaux peu profonds en les empêchant de faire des sorties précoces et en les forçant à effectuer les calculs complets de toutes les couches.
« Les attaques par ralentissement ont le potentiel d'annuler les avantages des architectures à sorties multiples », Dumitras mentionné. "Ces architectures peuvent réduire de moitié la consommation d'énergie d'un modèle de réseau de neurones profonds au moment de l'inférence, et nous avons montré que pour toute entrée, nous pouvons créer une perturbation qui efface complètement ces économies."
Les résultats des chercheurs montrent que l'attaque DeepSloth peut réduire l'efficacité des réseaux de neurones à sorties multiples de 90 à 100 %. Dans le scénario le plus simple, cela peut entraîner une perte de mémoire et des ressources de calcul d'un système d'apprentissage en profondeur et devenir inefficace pour servir les utilisateurs.
Mais dans certains cas, cela peut causer des dommages plus graves. Par exemple, une utilisation d'architectures à plusieurs sorties consiste à diviser un modèle d'apprentissage en profondeur entre deux points de terminaison. Les premières couches du réseau de neurones peuvent être installées sur un emplacement périphérique, tel qu'un appareil portable ou IoT. Les couches les plus profondes du réseau sont déployées sur un serveur cloud. Le côté périphérique du modèle d'apprentissage en profondeur prend en charge les entrées simples qui peuvent être calculées en toute confiance dans les premières couches. Dans les cas où le côté périphérique du modèle n'atteint pas un résultat concluant, il reporte les calculs supplémentaires vers le cloud.
Dans un tel cadre, l'attaque DeepSloth forcerait le modèle d'apprentissage profond à envoyer toutes les inférences au cloud. Outre l'énergie supplémentaire et les ressources de serveur gaspillées, l'attaque pourrait avoir un impact beaucoup plus destructeur.
« Dans un scénario typique des déploiements IoT, où le modèle est partitionné entre les périphériques de périphérie et le cloud, DeepSloth amplifie la latence de 1,5– 5X, annulant les avantages du partitionnement de modèle », a déclaré Dumitras. "Cela pourrait amener l'appareil de périphérie à manquer des délais critiques, par exemple dans un programme de surveillance des personnes âgées qui utilise l'IA pour détecter rapidement les accidents et appeler à l'aide si nécessaire."
Alors que les chercheurs ont effectué la plupart de leurs tests sur des réseaux profonds et peu profonds. , ils ont découvert plus tard que la même technique serait efficace sur d'autres types de modèles à sortie précoce.
Attaques dans des contextes réels


Comme pour la plupart des travaux sur la sécurité de l'apprentissage automatique, les chercheurs ont d'abord supposé qu'un attaquant connaissait parfaitement le modèle cible et disposait de ressources informatiques illimitées pour créer des attaques DeepSloth. Mais la criticité d'une attaque dépend également de sa capacité à être mise en scène dans des contextes pratiques, où l'adversaire a une connaissance partielle de la cible et des ressources limitées.
« Dans la plupart des attaques accusatoires, l'attaquant doit avoir un accès complet au modèle. lui-même, en gros, ils ont une copie exacte du modèle de victime », a déclaré Kaya à TechTalks. "Ceci, bien sûr, n'est pas pratique dans de nombreux contextes où le modèle de victime est protégé de l'extérieur, par exemple avec une API comme Google Vision AI."
Pour développer une évaluation réaliste de l'attaquant, les chercheurs ont simulé un adversaire qui n'a pas une connaissance complète du modèle d'apprentissage en profondeur cible. Au lieu de cela, l'attaquant dispose d'un modèle de substitution sur lequel il teste et ajuste l'attaque. L'attaquant transfère ensuite l'attaque à la cible réelle. Les chercheurs ont formé des modèles de substitution qui ont différentes architectures de réseau neuronal, différents ensembles d'entraînement et même différents mécanismes de sortie précoce.
« Nous constatons que l'attaquant qui utilise une substitution peut toujours provoquer des ralentissements (entre 20 et 50 %) dans le modèle de victime », a déclaré Kaya.
De telles attaques par transfert sont beaucoup plus réalistes que les attaques en pleine connaissance, a déclaré Kaya. Et tant que l'adversaire dispose d'un modèle de substitution raisonnable, il pourra attaquer un modèle de boîte noire, tel qu'un système d'apprentissage automatique servi via une API Web.
« Attaquer un substitut est efficace car les réseaux de neurones qui fonctionnent des tâches similaires (par exemple, la classification d'objets) ont tendance à apprendre des caractéristiques similaires (par exemple, des formes, des bords, des couleurs) », a déclaré Kaya.
Dumitras dit que DeepSloth n'est que la première attaque qui fonctionne dans ce modèle de menace, et il pense plus dévastateur des attaques de ralentissement seront découvertes. Il a également souligné qu'en dehors des architectures à sorties multiples, d'autres mécanismes d'optimisation de la vitesse sont vulnérables aux attaques de ralentissement. Son équipe de recherche a testé DeepSloth sur SkipNet, une technique d'optimisation spéciale pour les réseaux de neurones convolutifs (CNN). Leurs résultats ont montré que les exemples DeepSloth conçus pour une architecture à sorties multiples provoquaient également des ralentissements dans les modèles SkipNet.
« Cela suggère que les deux mécanismes différents pourraient partager une vulnérabilité plus profonde, qui doit encore être caractérisée de manière rigoureuse », a déclaré Dumitras. « Je pense que les attaques par ralentissement peuvent devenir une menace importante à l'avenir. » les chercheurs pensent également que la sécurité doit être intégrée dans le processus de recherche en apprentissage automatique.
« Je ne pense pas qu'aucun chercheur d'aujourd'hui qui travaille sur l'apprentissage automatique ignore les problèmes de sécurité de base. De nos jours, même les cours d'introduction à l'apprentissage en profondeur incluent des modèles de menace récents tels que des exemples contradictoires », a déclaré Kaya.
Le problème, selon Kaya, est lié à l'ajustement des incitations. "Les progrès sont mesurés sur des références standardisées et quiconque développe une nouvelle technique utilise ces références et métriques standard pour évaluer sa méthode", a-t-il déclaré, ajoutant que les examinateurs qui décident du sort d'un article examinent également si la méthode est évaluée en fonction de leur des revendications sur des points de repère appropriés.
« Bien sûr, lorsqu'une mesure devient un objectif, elle cesse d'être une bonne mesure », a-t-il déclaré.
Kaya pense qu'il devrait y avoir un changement dans les incitations des publications et des universités. « À l'heure actuelle, les universitaires ont le luxe ou le fardeau de faire des déclarations peut-être irréalistes sur la nature de leur travail », dit-il. Si les chercheurs en apprentissage automatique reconnaissent que leur solution ne verra jamais le jour, leur article pourrait être rejeté. Mais leurs recherches pourraient servir à d'autres fins.
Par exemple, la formation contradictoire provoque d'importantes baisses d'utilité, a une faible évolutivité et est difficile à corriger, des limitations qui sont inacceptables pour de nombreuses applications d'apprentissage automatique. Mais Kaya souligne que la formation contradictoire peut avoir des avantages qui ont été négligés, tels que l'orientation des modèles vers devenant plus interprétables.
L'une des implications d'une trop grande concentration sur les références est que la plupart des chercheurs en apprentissage automatique ne N'examinez pas les implications de leur travail lorsqu'il est appliqué à des paramètres du monde réel et à des paramètres réalistes.
« Notre plus gros problème est que nous traitons la sécurité de l'apprentissage automatique comme un problème académique en ce moment. Ainsi, les problèmes que nous étudions et les solutions que nous concevons sont également académiques », explique Kaya. "Nous ne savons pas si un attaquant du monde réel est intéressé à utiliser des exemples contradictoires ou un praticien du monde réel pour se défendre contre eux."
Kaya pense que la communauté de l'apprentissage automatique devrait promouvoir et encourager la recherche pour comprendre les vrais adversaires de systèmes d'apprentissage automatique plutôt que de "rêver nos propres adversaires".
Et enfin, il dit que les auteurs d'articles sur l'apprentissage automatique devraient être encouragés à faire leurs devoirs et à trouver des moyens de briser leurs propres solutions, comme lui et ses collègues l'ont fait avec les réseaux peu profonds. Et les chercheurs doivent être explicites et clairs sur les limites et les menaces potentielles de leurs modèles et techniques d'apprentissage automatique.
« Si nous examinons les articles proposant des architectures à sortie rapide, nous voyons qu'il n'y a aucun effort pour comprendre les risques de sécurité bien qu'ils prétendent que ces solutions ont une valeur pratique », dit-il. « Si un praticien de l'industrie trouve ces documents et met en œuvre ces solutions, il n'est pas averti de ce qui peut mal tourner. Bien que des groupes comme le nôtre essaient d'exposer des problèmes potentiels, nous sommes moins visibles pour un praticien qui souhaite utiliser un modèle de sortie précoce. Même inclure un paragraphe sur les risques potentiels impliqués dans une solution va un long chemin. »
Cet article a été initialement publié par Ben Dickson sur TechTalksune publication qui examine les tendances en matière de la technologie, comment ils affectent notre façon de vivre et de faire des affaires, et les problèmes qu'ils résolvent. Mais nous discutons également du côté pervers de la technologie, des implications les plus sombres des nouvelles technologies et de ce que nous devons rechercher. Vous pouvez lire l'article original ici.
Source link