
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Implémentation de la génération augmentée de récupération (RAG) avec la sortie JSON
Précédemment publié sur Nuclia.com. Nuclia est maintenant Progress Agentic RAG.
But
Historiquement, lorsqu’ils interagissaient avec des machines, les humains devaient s’adapter au langage de la machine pour poser des questions, généralement à l’aide de requêtes SQL, puis interpréter la réponse de la machine. Cette réponse se présente généralement dans un format de données structuré, tel qu’un tableau ou une chaîne JSON, suivant un schéma spécifique.
Les réponses génératives sont bénéfiques car elles permettent aux utilisateurs de poser des questions en langage naturel, comme le feraient les humains, et de recevoir des réponses lisibles par l’homme.
Cependant, les réponses lisibles par l’homme ne sont pas idéales lorsque la réponse doit être traitée par une autre machine. Dans de tels cas, un format de données structuré est plus approprié.
Par exemple, si vous souhaitez connaître le dernier livre écrit par Isaac Asimov dans la série Foundation, vous pouvez demander un LLM et obtenir une réponse claire. Mais si vous souhaitez commander ce livre automatiquement, vous avez besoin de la réponse dans un format structuré à envoyer au système de commande.
Dans ce scénario, avoir le meilleur des deux mondes est idéal : poser la requête en langage naturel (« S’il vous plaît, commandez le dernier livre d’Isaac Asimov de la série Foundation ») et recevoir une réponse de données structurées.
C’est le but de l’option de sortie JSON sur le point de terminaison /ask de Nuclia.
Remarque : Concernant l’exemple, vous vous demandez peut-être s’il est important de dire « S’il vous plaît » dans la requête. La réponse est oui. Premièrement, les LLM sont connus pour être plus précis lorsque la requête est polie. Deuxièmement, c’est une bonne pratique d’être poli lorsque vous interagissez avec une entité, en particulier celle qui imite la conversation humaine, pour éviter de développer une habitude d’impolitesse (croyez-moi, je suis français et j’ai été formé pour être impoli dès mon plus jeune âge).
Principe
Pour obtenir une sortie JSON du LLM, vous devez définir la structure de données attendue. En utilisant l’exemple de commande de livres, vous vous attendez probablement à un objet JSON avec les champs suivants :
title: le titre du livre,author: l’auteur du livre,ISBN: l’ISBN du livre,price: le prix du livre.
Pour y parvenir, vous devez spécifier le schéma JSON que vous souhaitez que la réponse suive. Ce schéma est transmis au point de terminaison dans le paramètreanswer_json_schema de la requête. Il utilise le Schéma JSON format. Voici un exemple de schéma pour le cas d’utilisation de commande de livres :
{
"name": "book_ordering",
"description": "Structured answer for a book to order",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The title of the book"
},
"author": {
"type": "string",
"description": "The author of the book"
},
"ref_num": {
"type": "string",
"description": "The ISBN of the book"
},
"price": {
"type": "number",
"description": "The price of the book"
}
},
"required": ["title", "author", "ref_num", "price"]
}
}Les attributs les plus importants sont les attributs de description car c’est ce que le LLM utilisera pour comprendre ce que vous attendez.
Parfois, la description n’est pas nécessaire, par exemple, l’auteur est suffisamment explicite comme nom d’attribut et le LLM le comprendra correctement. Parfois, il faut être précis, comme pour ref_num qui ne peut pas être facilement lié à l’ISBN du livre sans une description appropriée. Ou disons que vous voulez la date de publication, publication_date serait suffisant pour le LLM, mais si vous ajoutez la description suivante :
"Publication date in ISO format"Ensuite, le LLM formatera pour vous la date au format ISO.
Le format JSON Schema est assez puissant et vous pouvez définir des structures complexes, comme des objets imbriqués, des tableaux, etc., ou même définir des contraintes sur les valeurs (comme une valeur minimale ou maximale pour un nombre, ou la liste des propriétés requises) :
{
"name": "book_ordering",
"description": "Structured answer for a book to order",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The title of the book"
},
"price": {
"type": "number",
"description": "The price of the book"
},
"details": {
"type": "object",
"description": "Details of the book",
"properties": {
"publication_date": {
"type": "string",
"description": "Publication date in ISO format"
},
"pages": {
"type": "number",
"description": "Number of pages"
},
"rating": {
"type": "number",
"description": "Rating of the book",
"minimum": 0,
"maximum": 5
}
},
"required": ["publication_date"]
}
},
"required": ["title", "details"]
}
}Cas d’utilisation
Les cas d’utilisation sont infinis, mais l’un des plus évidents est d’offrir à vos utilisateurs une interface conversationnelle où ils peuvent poser des questions en langage naturel, obtenir à la fois une réponse régulière en texte brut et un ensemble d’actions à effectuer en fonction de la réponse.
Dans la plupart des cas, vous ne souhaitez pas ignorer complètement la réponse lisible par l’homme, car c’est un bon moyen de vérifier si le LLM a correctement compris la requête.
Dans notre exemple, si le LLM est un vrai fan d’Isaac Asimov, il répondra probablement que le dernier livre du cycle Fondation est soit «Faire avancer la Fondation» si vous vouliez dire dernier selon la date de publication, ou «Fondation et Terre » Si vous vouliez dire le dernier selon la chronologie de l’histoire. Alors, hé, lequel veux-tu réellement commander ici, hein ??!
Vous allez donc ajouter une réponse lisible par l’homme dans la sortie JSON pour permettre à l’utilisateur de continuer à interagir avec le LLM jusqu’à ce que la requête soit correctement comprise :
{
"name": "book_ordering",
"description": "Structured answer for a book to order",
"parameters": {
"type": "object",
"properties": {
"answer": {
"type": "string",
"description": "Text responding to the user's query with the given context."
}
// then the rest of the schema
}
}
}Et vous pouvez utiliser les données structurées pour automatiser les étapes suivantes.
Extraire des informations structurées à partir d’images
Comme Nuclia propose une stratégie RAG fournissant des images avec le texte, il est possible d’extraire des informations structurées à partir des images si vous sélectionnez un LLM visuel.
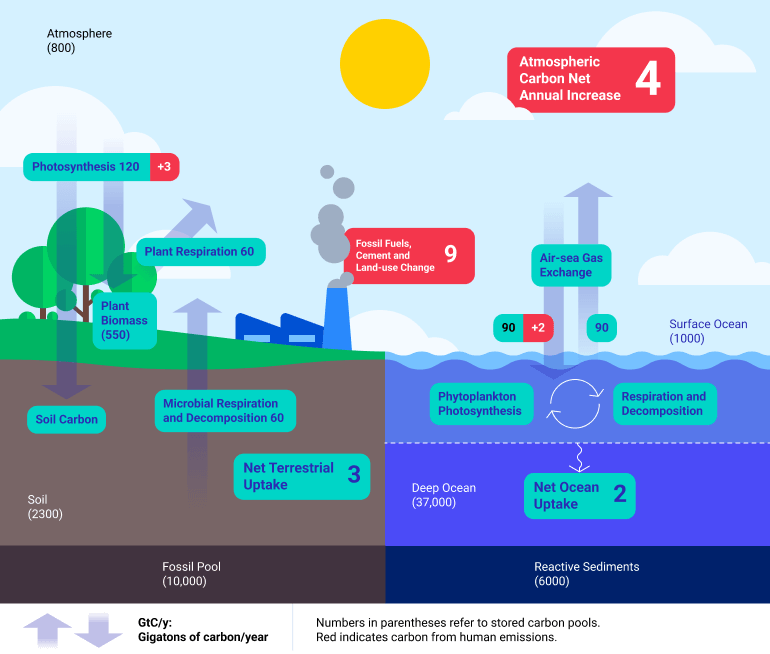
Par exemple, si vous indexez un document contenant une image comme celle-ci :

Vous pouvez demander au LLM « Combien de carbone est stocké dans le sol ? » et obtenez la réponse sous forme de nombre avec :
{
"query": "How many carbon is stored in the soil?",
"answer_json_schema": {
"name": "carbon_cycle",
"description": "Structured answer for the carbon cycle",
"parameters": {
"type": "object",
"properties": {
"carbon_in_soil": {
"type": "number",
"description": "Amount of carbon stored in the soil in gigatons"
}
},
"required": ["carbon_in_soil"]
}
}
}et vous obtiendrez la sortie JSON suivante :
{
"answer": "",
"answer_json": {
"carbon_in_soil": 2300
},
"status": "success",
…
}Cela fonctionnerait également avec le SDK Nuclia Python :
from nuclia import sdk
search = sdk.NucliaSearch()
answer = search.ask_json(
query="How many carbon is stored in the soil?",
generative_model="chatgpt-vision",
rag_images_strategies=[{"name": "paragraph_image", "count": 1}],
answer_json_schema={
"name": "carbon_cycle",
"description": "Structured answer for the carbon cycle",
"parameters": {
"type": "object",
"properties": {
"carbon_in_soil": {
"type": "number",
"description": "Amount of carbon stored in the soil in gigatons"
}
},
"required": ["carbon_in_soil"]
}
}
)
print(answer.object["carbon_in_soil"]) # 2300
Voir le documentation pour plus de détails.
Utiliser des métadonnées
Vous devrez peut-être récupérer des informations supplémentaires qui ne sont pas présentes dans le texte, comme la date de publication, l’auteur, l’URL de la source, etc. Ces informations peuvent être stockées dans les métadonnées de la ressource puis utilisées dans la sortie JSON.
Pour permettre au LLM d’accéder à ces métadonnées, vous pouvez utiliser le metadata_extension Stratégie RAG puis définissez le schéma JSON en conséquence.
Source link