


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Comment rendre les performances visibles avec GitLab CI et Hoodoo d'artefacts GitLab
La dégradation des performances est un problème auquel nous sommes confrontés quotidiennement. Nous pourrions nous efforcer de rendre l'application flamboyante rapidement, mais nous finissons bientôt là où nous avons commencé. Cela se produit en raison de l'ajout de nouvelles fonctionnalités et du fait que nous n'avons parfois pas une seconde pensée sur les packages que nous ajoutons et mettons à jour en permanence, ou pensons à la complexité de notre code. C'est généralement une petite chose, mais il s'agit toujours de petites choses.
Nous ne pouvons pas nous permettre d'avoir une application lente. La performance est un avantage concurrentiel qui peut attirer et fidéliser des clients. Nous ne pouvons pas nous permettre de passer régulièrement du temps à optimiser les applications à nouveau. C'est coûteux et complexe. Et cela signifie qu'en dépit de tous les avantages de la performance d'un point de vue commercial, elle n'est guère rentable. Comme première étape pour trouver une solution à tout problème, nous devons rendre le problème visible. Cet article vous aidera exactement à ce sujet.
Remarque : Si vous avez une compréhension de base de Node.js une vague idée du fonctionnement de votre CI / CD , et nous soucions des performances de l'application ou des avantages commerciaux qu'elle peut apporter, alors nous sommes prêts à partir.
Comment créer un budget de performances pour un projet
Les premières questions que nous devons nous poser sont:
"Quel est le projet performant?"
"Quelles métriques dois-je utiliser?"
"Quelles valeurs de ces métriques sont acceptables?"
La sélection des métriques sort du cadre de cet article et dépend fortement de le contexte du projet, mais je vous recommande de commencer par lire Mesures de performance centrées sur l'utilisateur par Philip Walton .
De mon point de vue, c'est une bonne idée d'utiliser la taille du bibliothèque en kilo-octets en tant que métrique pour le package npm. Pourquoi? Eh bien, c'est parce que si d'autres personnes incluent votre code dans leurs projets, elles voudront peut-être minimiser l'impact de votre code sur la taille finale de leur application.
Pour le site, je considérerais Time To First Byte ( TTFB) en tant que métrique. Cette mesure indique le temps qu'il faut au serveur pour répondre avec quelque chose. Cette métrique est importante, mais assez vague car elle peut inclure n'importe quoi – à partir du temps de rendu du serveur et se terminant par des problèmes de latence. Il est donc agréable de l'utiliser en conjonction avec Timing du serveur ou OpenTracing pour découvrir en quoi il consiste exactement.
Vous devriez également considérer des mesures telles que Temps d'interaction (TTI) et Première peinture significative (cette dernière sera bientôt remplacée par La plus grande peinture contentieuse (LCP) ). Je pense que ces deux éléments sont les plus importants – du point de vue de la performance perçue.
Mais gardez à l'esprit: les mesures sont toujours liées au contexte alors s'il vous plaît, ne prenez pas cela pour acquis. Réfléchissez à ce qui est important dans votre cas spécifique.
La façon la plus simple de définir les valeurs souhaitées pour les métriques est d'utiliser vos concurrents – ou même vous-même. De plus, de temps en temps, des outils tels que Calculateur de budget de performance peuvent être utiles – il suffit de jouer un peu avec.
Utilisez des concurrents à votre avantage
Si jamais vous vous enfuyiez d'un ours extatique surexcité, alors vous savez déjà que vous n'avez pas besoin d'être un champion olympique de course à pied pour sortir de ce problème. Vous devez juste être un peu plus rapide que l'autre gars.
Alors faites une liste de concurrents. S'il s'agit de projets du même type, ils consistent généralement en des types de pages similaires. Par exemple, pour une boutique Internet, il peut s'agir d'une page avec une liste de produits, une page de détails sur le produit, un panier, une caisse, etc.
- Mesurez les valeurs de vos mesures sélectionnées sur chaque type de page pour les projets de votre concurrent ;
- Mesurez les mêmes mesures sur votre projet;
- Trouvez la meilleure valeur la plus proche de votre valeur pour chaque mesure des projets du concurrent. Ajouter 20% à eux et définir vos prochains objectifs.
Pourquoi 20%? Il s'agit d'un nombre magique qui signifie que la différence sera perceptible à l'œil nu. Vous pouvez en savoir plus sur ce numéro dans l'article de Denys Mishunov « Pourquoi les performances perçues sont importantes, partie 1: la perception du temps ».
Un combat avec une ombre
Avez-vous un projet unique? Vous n'avez pas de concurrents? Ou vous êtes déjà meilleur que n'importe lequel d'entre eux dans tous les sens possibles? Ce n'est pas un problème. Vous pouvez toujours rivaliser avec le seul adversaire digne, c'est-à-dire vous-même. Mesurez chaque mesure de performance de votre projet sur chaque type de page, puis améliorez-les de 20%.
Tests synthétiques
Il existe deux façons de mesurer les performances:
- Synthétique (dans un contrôle environnement)
- RUM (Real User Measurements)
Les données sont collectées auprès d'utilisateurs réels en production.
Dans cet article, nous allons utiliser des tests synthétiques et supposer que notre projet utilise GitLab avec son CI intégré pour le déploiement de projet.
Bibliothèque et sa taille en tant que métrique
Supposons que vous avez décidé de développer une bibliothèque et de la publier dans NPM. Vous voulez le garder léger – beaucoup plus léger que vos concurrents – afin qu'il ait moins d'impact sur la taille finale du projet résultant. Cela permet d'économiser du trafic client – parfois du trafic pour lequel le client paie. Il permet également de charger le projet plus rapidement, ce qui est assez important en ce qui concerne la part mobile croissante et les nouveaux marchés avec des vitesses de connexion lentes et une couverture Internet fragmentée.
Package pour mesurer la taille de la bibliothèque
Pour conserver la taille du bibliothèque aussi petite que possible, nous devons surveiller attentivement son évolution au fil du temps de développement. Mais comment pouvez-vous le faire? Eh bien, nous pourrions utiliser le package Size Limit créé par Andrey Sitnik de Evil Martians .
Installons-le.
npm i -D taille- limit @ size-limit / preset-small-lib
Ensuite, ajoutez-le à package.json .
"scripts": {
+ "taille": "taille-limite",
"test": "plaisanterie && eslint."
},
+ "taille limite": [
+ {
+ "path": "index.js"
+ }
+ ],
Le bloc "size-limit": [{},{},…] contient une liste de la taille des fichiers dont nous voulons vérifier. Dans notre cas, il s'agit d'un seul fichier: index.js .
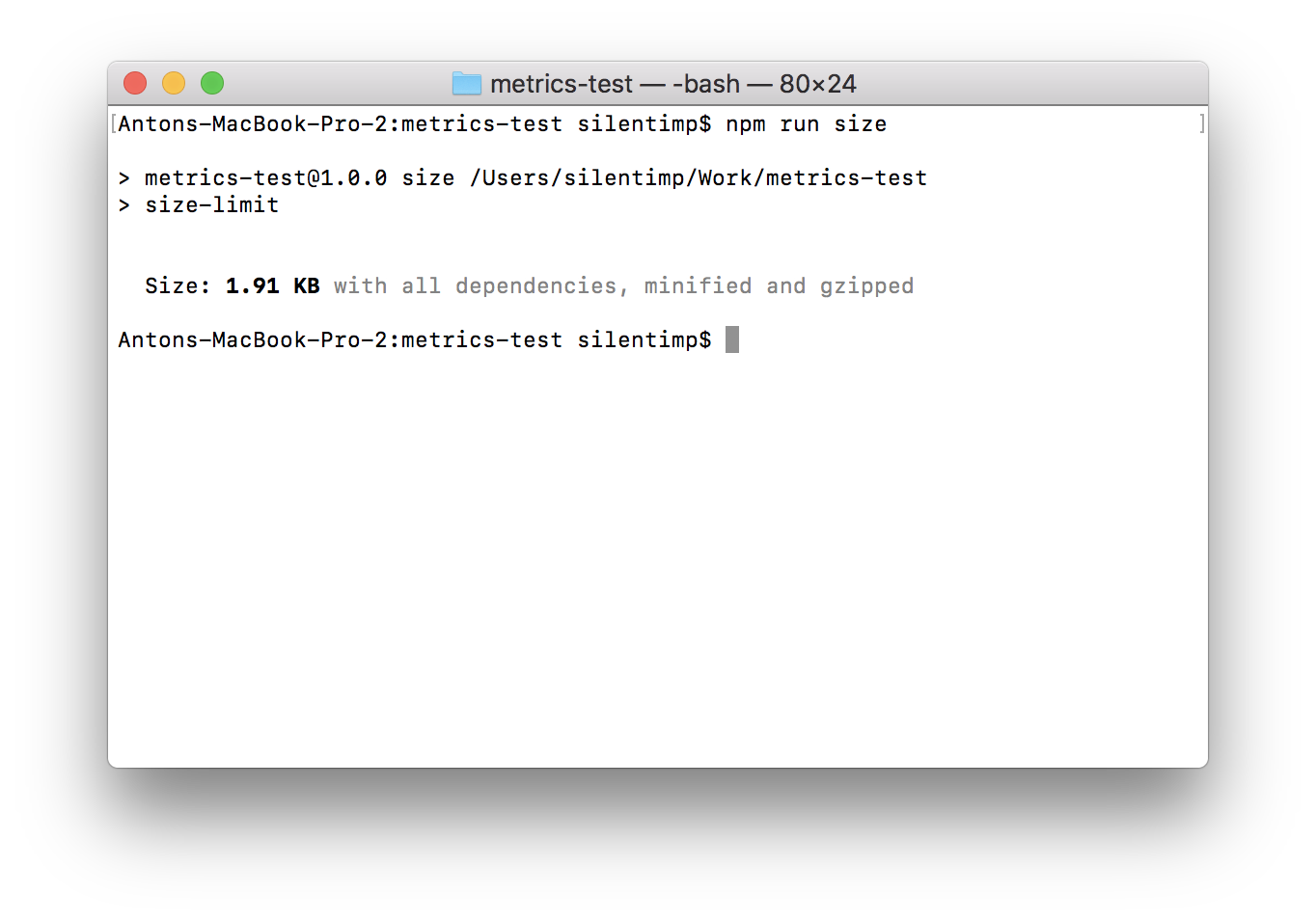
Le script NPM size exécute simplement le package size-limit qui lit la configuration block size-limit mentionné précédemment et vérifie la taille des fichiers qui y sont répertoriés. Exécutons-le et voyons ce qui se passe:
npm run size

Nous pouvons voir la taille du fichier, mais cette taille n'est pas réellement sous contrôle. Corrigeons cela en ajoutant limit à package.json :
"size-limit": [
{
+ "limit": "2 KB",
"path": "index.js"
}
],
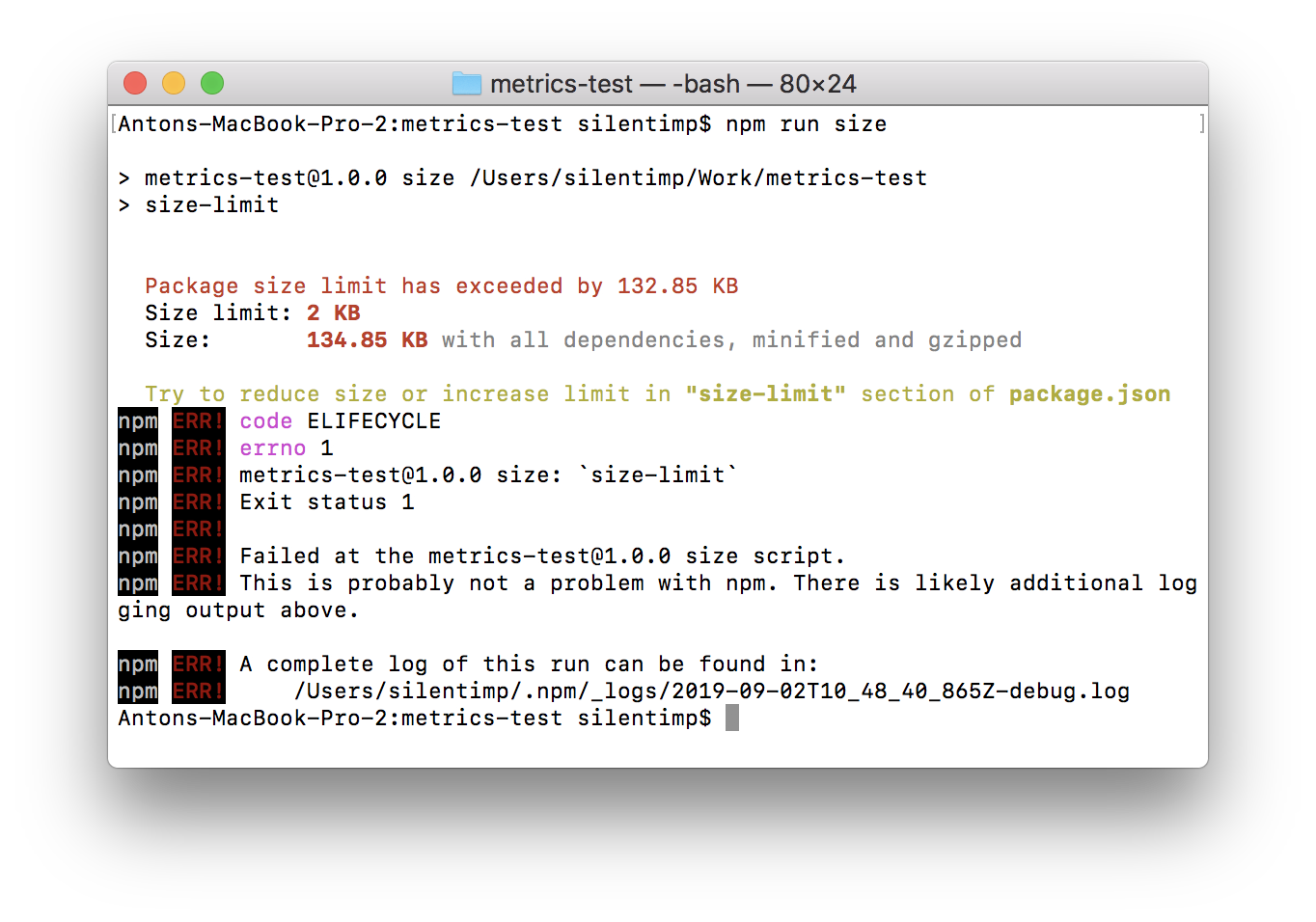
Maintenant, si nous exécutons le script, il sera validé par rapport à la limite que nous avons définie.

Dans le cas où un nouveau développement modifie la taille du fichier au point de dépasser la limite définie, le script se terminera avec un code différent de zéro. Ceci, mis à part d'autres choses, signifie qu'il arrêtera le pipeline dans le GitLab CI.

Maintenant, nous pouvons utiliser git hook pour vérifier la taille du fichier par rapport à la limite avant chaque validation. Nous pouvons même utiliser le package husky pour le faire de manière simple et agréable.
Installons-le.
npm i -D husky
Ensuite, modifiez notre package.json .
"size-limit": [
{
"limit": "2 KB",
"path": "index.js"
}
],
+ "husky": {
+ "crochets": {
+ "pré-commit": "taille d'exécution npm"
+}
+},
Et maintenant, avant que chaque validation ne soit exécutée automatiquement, la commande npm run size et si elle se termine avec un code différent de zéro, la validation ne se produira jamais.

Mais il existe de nombreuses façons d'ignorer les crochets (intentionnellement ou même par accident), nous ne devons donc pas trop compter sur eux.
De plus, il est important de noter que nous ne devrions pas avoir besoin de faire ce blocage de vérification. Pourquoi? Parce que c'est normal que la taille de la bibliothèque augmente pendant que vous ajoutez de nouvelles fonctionnalités. Nous devons rendre les changements visibles, c'est tout. Cela permettra d'éviter une augmentation de taille accidentelle en raison de l'introduction d'une bibliothèque d'aide dont nous n'avons pas besoin. Et, peut-être, donnez aux développeurs et aux propriétaires de produits une raison de se demander si la fonctionnalité ajoutée vaut l'augmentation de taille. Ou, peut-être, s'il existe des packages alternatifs plus petits. Bundlephobia nous permet de trouver une alternative pour presque tous les packages NPM.
Alors, que devons-nous faire? Voyons la modification de la taille du fichier directement dans la demande de fusion! Mais vous ne poussez pas pour maîtriser directement; vous agissez comme un développeur adulte n'est-ce pas?
Exécution de notre vérification sur GitLab CI
Ajoutons un artefact GitLab du type de métriques . Un artefact est un fichier qui «vivra» une fois l'opération de pipeline terminée. Ce type d'artefact spécifique nous permet d'afficher un widget supplémentaire dans la demande de fusion, montrant tout changement dans la valeur de la métrique entre l'artefact dans le maître et la branche de fonctionnalité. Le format de l'artefact de mesure est un format de texte Prométhée . Pour les valeurs GitLab à l'intérieur de l'artefact, c'est juste du texte. GitLab ne comprend pas ce qui a exactement changé la valeur, il sait juste que la valeur est différente. Alors, que devons-nous faire exactement?
- Définir des artefacts dans le pipeline.
- Changer le script pour qu'il crée un artefact sur le pipeline.
Pour créer un artefact, nous devons changer .gitlab- ci.yml de cette façon:
image: node: latest
étapes:
- performance
sizecheck:
performance sur scène
before_script:
- npm ci
scénario:
- taille d'exécution npm
+ artefacts:
+ expire_in: 7 jours
+ chemins:
+ - metric.txt
+ rapports:
+ métriques: metric.txt
expire_in: 7 jours– l'artefact existera pendant 7 jours.chemins: metric.txtIl sera enregistré dans le catalogue racine. Si vous ignorez cette option, il ne sera pas possible de la télécharger.
rapporte: métriques: metric.txtL'artefact aura le type
rapports: métriques
Maintenant, faisons en sorte que Size Limit génère un rapport. Pour ce faire, nous devons modifier package.json :
"scripts": {
- "taille": "taille limite",
+ "taille": "taille-limite --json> taille-limite.json",
"test": "plaisanterie && eslint."
},
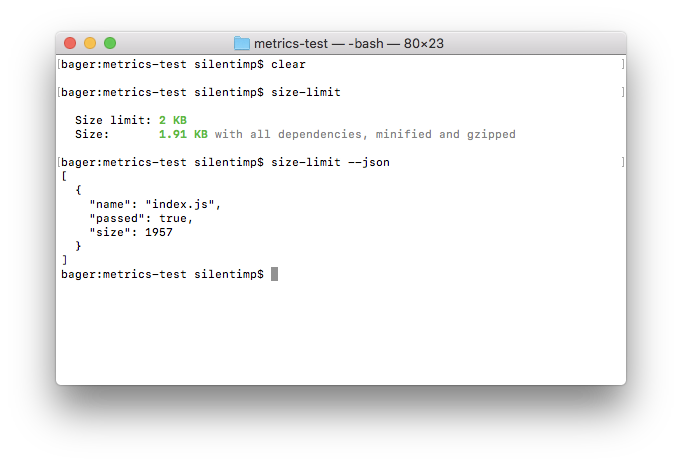
size-limit avec la clé - json affichera les données au format json:

size-limit --json affiche JSON sur la console. JSON contient un tableau d'objets qui contiennent un nom et une taille de fichier, ainsi que nous permet de savoir s'il dépasse la limite de taille. ( Grand aperçu ) Et la redirection > size-limit.json enregistrera JSON dans le fichier size-limit.json .
Maintenant, nous avons besoin pour créer un artefact à partir de cela. Le format se résume à [metrics name][space][metrics value]. Créons le script generate-metric.js :
const report = require ('./ size-limit.json');
process.stdout.write (`size $ {(report [0] .size / 1024) .toFixed (1)} Kb`);
process.exit (0);
Et ajoutez-le à package.json :
"scripts": {
"size": "size-limit --json> size-limit.json",
+ "postsize": "node generate-metric.js> metric.txt",
"test": "plaisanterie && eslint."
},
Comme nous avons utilisé le préfixe post la commande npm run size exécutera le script size en premier, puis exécutera automatiquement le ] script postsize qui entraînera la création du fichier metric.txt notre artefact.
Par conséquent, lorsque nous fusionnons cette branche en master, changez quelque chose et créez une nouvelle demande de fusion, nous verrons ce qui suit:

Dans le widget qui apparaît sur la page, nous voyons d'abord le nom de la métrique ( taille ) suivi de la valeur de la métrique dans la fonction
Maintenant, nous pouvons réellement voir comment changer la taille du package et prendre une décision raisonnable si nous devons le fusionner ou non.
Reprendre
D'ACCORD! Nous avons donc compris comment gérer le cas trivial. Si vous avez plusieurs fichiers, séparez simplement les mesures par des sauts de ligne. Comme alternative à la taille limite, vous pouvez envisager bundlesize . Si vous utilisez WebPack, vous pouvez obtenir toutes les tailles dont vous avez besoin en créant avec - profile et - json flags:
webpack --profile --json> stats .json
Si vous utilisez next.js, vous pouvez utiliser le plug-in @ next / bundle-analyzer . C'est à vous de décider!
Utilisation de Lighthouse
Lighthouse est la norme de facto en analyse de projet. Écrivons un script qui nous permet de mesurer les performances, a11y, les meilleures pratiques et nous fournissons un score SEO.
Script pour mesurer toutes les choses
Pour commencer, nous devons installer le phare ] paquet qui fera les mesures. Nous devons également installer marionnettiste que nous utiliserons comme navigateur sans tête.
npm i -D phare marionnettiste
Ensuite, créons un script lighthouse.js et démarrons notre navigateur:
const puppeteer = require ('puppeteer');
(async () => {
const browser = attendre puppeteer.launch ({
args: ['--no-sandbox', '--disable-setuid-sandbox', '--headless'],
});
}) ();
Écrivons maintenant une fonction qui nous aidera à analyser une URL donnée:
const lighthouse = require ('lighthouse');
const DOMAIN = process.env.DOMAIN;
const buildReport = browser => async url => {
const data = attendent le phare (
`$ {DOMAIN} $ {url}`,
{
port: nouvelle URL (browser.wsEndpoint ()). port,
sortie: 'json',
},
{
étend: «phare: plein»,
}
);
const {report: reportJSON} = data;
const report = JSON.parse (reportJSON);
//…
}
Génial! Nous avons maintenant une fonction qui acceptera l'objet navigateur comme argument et renverra une fonction qui acceptera URL comme argument et générera un rapport après avoir transmis cette URL à lighthouse .
Nous transmettons les arguments suivants au lighthouse :
- L'adresse que nous voulons analyser;
-
lighthouseoptions, navigateurporten particulier, etsortie(format de sortie du rapport); -
rapportconfiguration etphare: plein(tout ce que nous pouvons mesurer) . Pour une configuration plus précise, consultez la documentation .
Merveilleux! Nous avons maintenant notre rapport. Mais que pouvons-nous en faire? Eh bien, nous pouvons vérifier les mesures par rapport aux limites et quitter le script avec un code non nul qui arrêtera le pipeline:
if (report.categories.performance.score Mais nous voulons juste rendre les performances visibles et non Adoptons ensuite un autre type d'artefact: GitLab performance artefact .
GitLab Performance Artifact
Pour comprendre ce format d'artefacts, nous devons lire le code du sitespeed.io plugin. (Pourquoi GitLab ne peut-il pas décrire le format de leurs artefacts dans leur propre documentation? Mystery. )
[
{
"subject":"/",
"metrics":[
{
"name":"Transfer Size (KB)",
"value":"19.5",
"desiredSize":"smaller"
},
{
"name":"Total Score",
"value":92,
"desiredSize":"larger"
},
{…}
]
},
{…}
]
Un artefact est un fichier JSON qui contient un tableau des objets. Chacun d'eux représente un rapport sur une URL .
[{page 1}, {page 2}, …]
Chaque page est représentée par un objet avec les attributs suivants:
-
sujet
Identificateur de page (il est assez pratique d'utiliser un tel nom de chemin); -
métriques
Un tableau des objets (chacun d'eux représente une mesure qui a été faite sur la page).
{
"subject": "/ login /",
"métriques": [{measurement 1}, {measurement 2}, {measurement 3}, …]
}
Une mesure est un objet qui contient les attributs suivants:
-
nom
Nom de la mesure, par ex. il peut êtreTemps jusqu'au premier octetouTemps d'interaction. -
valeur
Résultat de la mesure numérique. -
Taille souhaitée
Si cible la valeur doit être aussi petite que possible, par ex. pour la métriqueTemps d'interactionla valeur doit êtreplus petite. S'il doit être aussi grand que possible, par ex. pour le phareScore de performancepuis utilisezplus grand.
{
"name": "Temps jusqu'au premier octet (ms)",
"valeur": 240,
"taille souhaitée": "plus petit"
}
Modifions notre fonction buildReport de manière à ce qu'elle renvoie un rapport d'une page avec des mesures de phare standard.

const buildReport = browser => async url => {
//…
const metrics = [
{
name: report.categories.performance.title,
value: report.categories.performance.score,
desiredSize: 'larger',
},
{
name: report.categories.accessibility.title,
value: report.categories.accessibility.score,
desiredSize: 'larger',
},
{
name: report.categories['best-practices'] .title,
valeur: report.categories ['best-practices'] .score,
taille souhaitée: 'plus grand',
},
{
nom: report.categories.seo.title,
valeur: report.categories.seo.score,
taille souhaitée: 'plus grand',
},
{
nom: report.categories.pwa.title,
valeur: report.categories.pwa.score,
taille souhaitée: 'plus grand',
},
];
revenir {
sujet: url,
métriques: métriques,
};
}
Maintenant, quand nous avons une fonction qui génère un rapport. Appliquons-le à chaque type de pages du projet. Tout d'abord, je dois préciser que process.env.DOMAIN doit contenir un domaine intermédiaire (vers lequel vous devez déployer votre projet à partir d'une branche de fonctionnalité au préalable).
+ const fs = require ('fs ');
const lighthouse = require ('lighthouse');
const marionnettiste = require ('marionnettiste');
const DOMAIN = process.env.DOMAIN;
const buildReport = browser => async url => {/ *… * /};
+ const urls = [
+ '/inloggen',
+ '/wachtwoord-herstellen-otp',
+ '/lp/service',
+ '/send-request-to/ww-tammer',
+ '/post-service-request/binnenschilderwerk',
+ ];
(async () => {
const browser = attendre puppeteer.launch ({
args: ['--no-sandbox', '--disable-setuid-sandbox', '--headless'],
});
+ const builder = buildReport (navigateur);
+ rapport const = [];
+ pour (laisser l'url des URL) {
+ const metrics = attente du générateur (url);
+ report.push (métriques);
+}
+ fs.writeFileSync (`. / performance.json`, JSON.stringify (report));
+ attendre browser.close ();
}) ();
Note : À ce stade, vous voudrez peut-être m'interrompre et crier en vain: "Pourquoi prenez-vous mon temps – vous ne pouvez même pas utiliser Promise.all correctement!" Pour ma défense, j'ose dire que il n'est pas recommandé d'exécuter plus d'une instance de phare en même temps car cela affecte négativement la précision des résultats de mesure. De plus, si vous ne faites pas preuve d'ingéniosité, cela entraînera une exception.
Utilisation de plusieurs processus
Êtes-vous toujours dans des mesures parallèles? Bien, vous voudrez peut-être utiliser le cluster de nœuds (ou même Threads de travail si vous aimez jouer en gras), mais il est logique de ne le discuter que dans le cas où votre pipeline fonctionne sur le environnement avec plusieurs cors disponibles. Et même dans ce cas, vous devez garder à l'esprit qu'en raison de la nature de Node.js, vous aurez une instance Node.js pleine pondération dans chaque fourche de processus (au lieu de réutiliser la même, ce qui entraînera une augmentation de la consommation de RAM). Tout cela signifie qu'il sera plus coûteux en raison des besoins matériels croissants et un peu plus rapide. Il peut sembler que le jeu n'en vaut pas la chandelle.
Si vous voulez prendre ce risque, vous devrez:
- Fractionner le tableau d'URL en morceaux par nombre de cœurs;
- Créer une fourchette d'un processus en fonction du nombre de cœurs;
- Transférez des parties du tableau vers les fourches, puis récupérez les rapports générés.
Pour fractionner un tableau, vous pouvez utiliser des approches à plusieurs fichiers. Le code suivant – écrit en quelques minutes seulement – ne serait pas pire que les autres:
/ **
* Renvoie le tableau d'url divisé en morceaux selon le nombre de cors
*
* @param urls {String []} - Tableau d'URL
* @param cors {Number} - nombre de cors disponibles
* @return {Array } - Tableau d'URL divisé en morceaux
* /
function chunkArray (urls, cors) {
const chunks = [...Array(cors)] .map (() => []);
soit index = 0;
urls.forEach ((url) => {
if (index> (chunks.length - 1)) {
index = 0;
}
chunks [index] .push (url);
index + = 1;
});
retourner des morceaux;
}
Créer des fourches en fonction du nombre de cœurs:
// Ajout de packages qui nous permettent d'utiliser le cluster
const cluster = require ('cluster');
// Et découvrez combien de cors sont disponibles. Les deux packages sont intégrés à node.js.
const numCPUs = require ('os'). cpus (). length;
(async () => {
if (cluster.isMaster) {
// Processus parent
const chunks = chunkArray (urls, urls.length / numCPUs);
chunks.map (chunk => {
// Création de processus enfants
const worker = cluster.fork ();
});
} autre {
// Processus enfant
}
}) ();
Transférons un tableau de blocs aux processus enfants et aux rapports rétrospectifs:
(async () => {
if (cluster.isMaster) {
// Processus parent
const chunks = chunkArray (urls, urls.length / numCPUs);
chunks.map (chunk => {
const worker = cluster.fork ();
+ // Envoyer un message avec le tableau d'URL au processus enfant
+ worker.send (morceau);
});
} autre {
// Processus enfant
+ // Recevoir le message du processus parent
+ process.on ('message', async (urls) => {
+ const browser = attendre puppeteer.launch ({
+ arguments: ['--no-sandbox', '--disable-setuid-sandbox', '--headless'],
+});
+ const builder = buildReport (navigateur);
+ rapport const = [];
+ pour (laisser l'url des URL) {
+ // Génération d'un rapport pour chaque URL
+ const metrics = attente du générateur (url);
+ report.push (métriques);
+}
+ // Renvoie un tableau de rapports au processus parent
+ cluster.worker.send (rapport);
+ attendre browser.close ();
+});
}
}) ();
Et, enfin, réassemblez les rapports dans un tableau et générez un artefact.
Précision des mesures
Eh bien, nous avons parallélisé les mesures, ce qui a augmenté la grande et déjà malheureuse erreur de mesure du phare . Mais comment pouvons-nous le réduire? Eh bien, faites quelques mesures et calculez la moyenne.
Pour ce faire, nous allons écrire une fonction qui calculera la moyenne entre les résultats de mesure actuels et les précédents.
// Nombre de mesures que nous voulons faire
const MEASURES_COUNT = 3;
/ *
* Réducteur qui calculera une valeur moyenne de toutes les mesures de page
* @param pages {Object} - accumulateur
* @param page {Object} - page
* @return {Object} - page avec des valeurs de mesures moyennes
* /
const mergeMetrics = (pages, page) => {
if (! pages) retourne la page;
revenir {
sujet: pages.subject,
métriques: pages.metrics.map ((mesure, index) => {
let value = (measure.value + page.metrics [index] .value) / 2;
value = + value.toFixed (2);
revenir {
...mesure,
valeur,
}
}),
}
}
Ensuite, changez notre code pour les utiliser:
process.on ('message', async (urls) => {
const browser = attendre puppeteer.launch ({
args: ['--no-sandbox', '--disable-setuid-sandbox', '--headless'],
});
const builder = buildReport (navigateur);
rapport const = [];
for (let url of urls) {
+ // Mesurons MEASURES_COUNT fois et calculons la moyenne
+ let mesures = [];
+ let index = MEASURES_COUNT;
+ while (index -) {
const metric = attente du générateur (url);
+ mesures.poussée (métrique);
+}
+ const mesure = measures.reduce (mergeMetrics);
report.push (mesure);
}
cluster.worker.send (rapport);
attendre browser.close ();
});
}
Et maintenant, nous pouvons ajouter phare au pipeline.
Ajout au pipeline
Créez d'abord un fichier de configuration nommé .gitlab-ci.yml .
image: node: latest
étapes:
# Vous devez déployer un projet sur le transfert et mettre le nom de domaine de transfert
# dans la variable d'environnement DOMAIN. Mais cela dépasse le cadre de cet article,
# principalement parce que cela dépend beaucoup de votre projet spécifique.
# - déployer
# - performance
phare:
performance sur scène
before_script:
- mise à jour apt-get
- apt-get -y install gconf-service libasound2 libatk1.0-0 libatk-bridge2.0-0 libc6
libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4
libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0
libstdc ++ 6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6
libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificats fonts-liberation
libappindicator1 libnss3 lsb-release xdg-utils wget
- npm ci
scénario:
- noeud lighthouse.js
artefacts:
expire_in: 7 jours
chemins:
- performance.json
rapports:
performance: performance.json
Les multiples packages installés sont nécessaires pour le marionnettiste . Comme alternative, vous pouvez envisager d'utiliser docker . En dehors de cela, il est logique que nous définissions le type d'artefact comme performance. Et, dès que la branche principale et la branche de fonctionnalité l'auront, vous verrez un widget comme celui-ci dans la demande de fusion:

Sympa?
Reprendre
Nous avons enfin terminé avec un cas plus complexe. De toute évidence, il existe plusieurs outils similaires en dehors du phare. Par exemple, sitespeed.io . La documentation de GitLab contient même un article qui explique comment utiliser sitespeed dans le pipeline de GitLab . Il existe également un plugin pour GitLab qui nous permet de générer un artefact . Mais qui préférerait les produits open source communautaires à ceux appartenant à un monstre d'entreprise?
Ain't No Rest For The Wicked
Il peut sembler que nous y sommes enfin, mais non, pas encore. Si vous utilisez une version GitLab payante, des artefacts avec des mesures de types de rapports et sont présents dans les plans à partir de premium et argent ] qui coûte 19 $ par mois pour chaque utilisateur. En outre, vous ne pouvez pas simplement acheter une fonctionnalité spécifique dont vous avez besoin – vous pouvez uniquement modifier le plan. Désolé. Donc ce que nous pouvons faire? À la différence de GitHub avec son API de vérification et API d'état GitLab ne vous permettrait pas de créer vous-même un widget réel dans la demande de fusion. Et il n'y a aucun espoir de les obtenir de sitôt .

Une façon de vérifier si vous avez réellement la prise en charge de ces fonctionnalités: Vous pouvez rechercher la variable d'environnement GITLAB_FEATURES dans le pipeline. S'il manque merge_request_performance_metrics et metrics_reports dans la liste, alors ces fonctionnalités ne sont pas prises en charge.
GITLAB_FEATURES = audit_events, burndown_charts, cod_owners, contribution_analytics,
elastic_search, export_issues, group_bulk_edit, group_burndown_charts, group_webhooks,
issuable_default_templates, issue_board_focus_mode, issue_weights, jenkins_integration,
ldap_group_sync, member_lock, merge_request_approvers, multiple_issue_assignees,
multiple_ldap_servers, multiple_merge_request_assignees, protected_refs_for_users,
push_rules, related_issues, repository_mirrors, repository_size_limit, scoped_issue_board,
usage_quotas, visual_review_app, wip_limits
S'il n'y a pas de soutien, nous devons trouver quelque chose. Par exemple, nous pouvons ajouter un commentaire à la demande de fusion, un commentaire avec le tableau, contenant toutes les données dont nous avons besoin. Nous pouvons laisser notre code intact – des artefacts seront créés, mais les widgets afficheront toujours un message «les métriques sont inchangées» .
Comportement très étrange et non évident; I had to think carefully to understand what was happening.
So, what’s the plan?
- We need to read artifact from the
masterbranch; - Create a comment in the
markdownformat; - Get the identifier of the merge request from the current feature branch to the master;
- Add the comment.
How To Read Artifact From The Master Branch
If we want to show how performance metrics are changed between master and feature branches, we need to read artifact from the master. And to do so, we will need to use fetch.
npm i -S isomorphic-fetch
// You can use predefined CI environment variables
// @see https://gitlab.com/help/ci/variables/predefined_variables.md
// We need fetch polyfill for node.js
const fetch = require('isomorphic-fetch');
// GitLab domain
const GITLAB_DOMAIN = process.env.CI_SERVER_HOST || process.env.GITLAB_DOMAIN || 'gitlab.com';
// User or organization name
const NAME_SPACE = process.env.CI_PROJECT_NAMESPACE || process.env.PROJECT_NAMESPACE || 'silentimp';
// Repo name
const PROJECT = process.env.CI_PROJECT_NAME || process.env.PROJECT_NAME || 'lighthouse-comments';
// Name of the job, which create an artifact
const JOB_NAME = process.env.CI_JOB_NAME || process.env.JOB_NAME || 'lighthouse';
/*
* Returns an artifact
*
* @param name {String} - artifact file name
* @return {Object} - object with performance artifact
* @throw {Error} - thhrow an error, if artifact contain string, that can’t be parsed as a JSON. Or in case of fetch errors.
*/
const getArtifact = async name => {
const response = await fetch(`https://${GITLAB_DOMAIN}/${NAME_SPACE}/${PROJECT}/-/jobs/artifacts/master/raw/${name}?job=${JOB_NAME}`);
if (!response.ok) throw new Error('Artifact not found');
const data = await response.json();
return data;
};
We need to build comment text in the markdown format. Let’s create some service funcions that will help us:
/**
* Return part of report for specific page
*
* @param report {Object} — report
* @param subject {String} — subject, that allow find specific page
* @return {Object} — page report
*/
const getPage = (report, subject) => report.find(item => (item.subject === subject));
/**
* Return specific metric for the page
*
* @param page {Object} — page
* @param name {String} — metrics name
* @return {Object} — metric
*/
const getMetric = (page, name) => page.metrics.find(item => item.name === name);
/**
* Return table cell for desired metric
*
* @param branch {Object} - report from feature branch
* @param master {Object} - report from master branch
* @param name {String} - metrics name
*/
const buildCell = (branch, master, name) => {
const branchMetric = getMetric(branch, name);
const masterMetric = getMetric(master, name);
const branchValue = branchMetric.value;
const masterValue = masterMetric.value;
const desiredLarger = branchMetric.desiredSize === 'larger';
const isChanged = branchValue !== masterValue;
const larger = branchValue > masterValue;
if (!isChanged) return `${branchValue}`;
if (larger) return `${branchValue} ${desiredLarger ? '?' : '?' } **+${Math.abs(branchValue - masterValue).toFixed(2)}**`;
return `${branchValue} ${!desiredLarger ? '?' : '?' } **-${Math.abs(branchValue - masterValue).toFixed(2)}**`;
};
/**
* Returns text of the comment with table inside
* This table contain changes in all metrics
*
* @param branch {Object} report from feature branch
* @param master {Object} report from master branch
* @return {String} comment markdown
*/
const buildCommentText = (branch, master) =>{
const md = branch.map( page => {
const pageAtMaster = getPage(master, page.subject);
if (!pageAtMaster) return '';
const md = `|${page.subject}|${buildCell(page, pageAtMaster, 'Performance')}|${buildCell(page, pageAtMaster, 'Accessibility')}|${buildCell(page, pageAtMaster, 'Best Practices')}|${buildCell(page, pageAtMaster, 'SEO')}|
`;
return md;
}).join('');
return `
|Path|Performance|Accessibility|Best Practices|SEO|
|--- |--- |--- |--- |--- |
${md}
`;
};
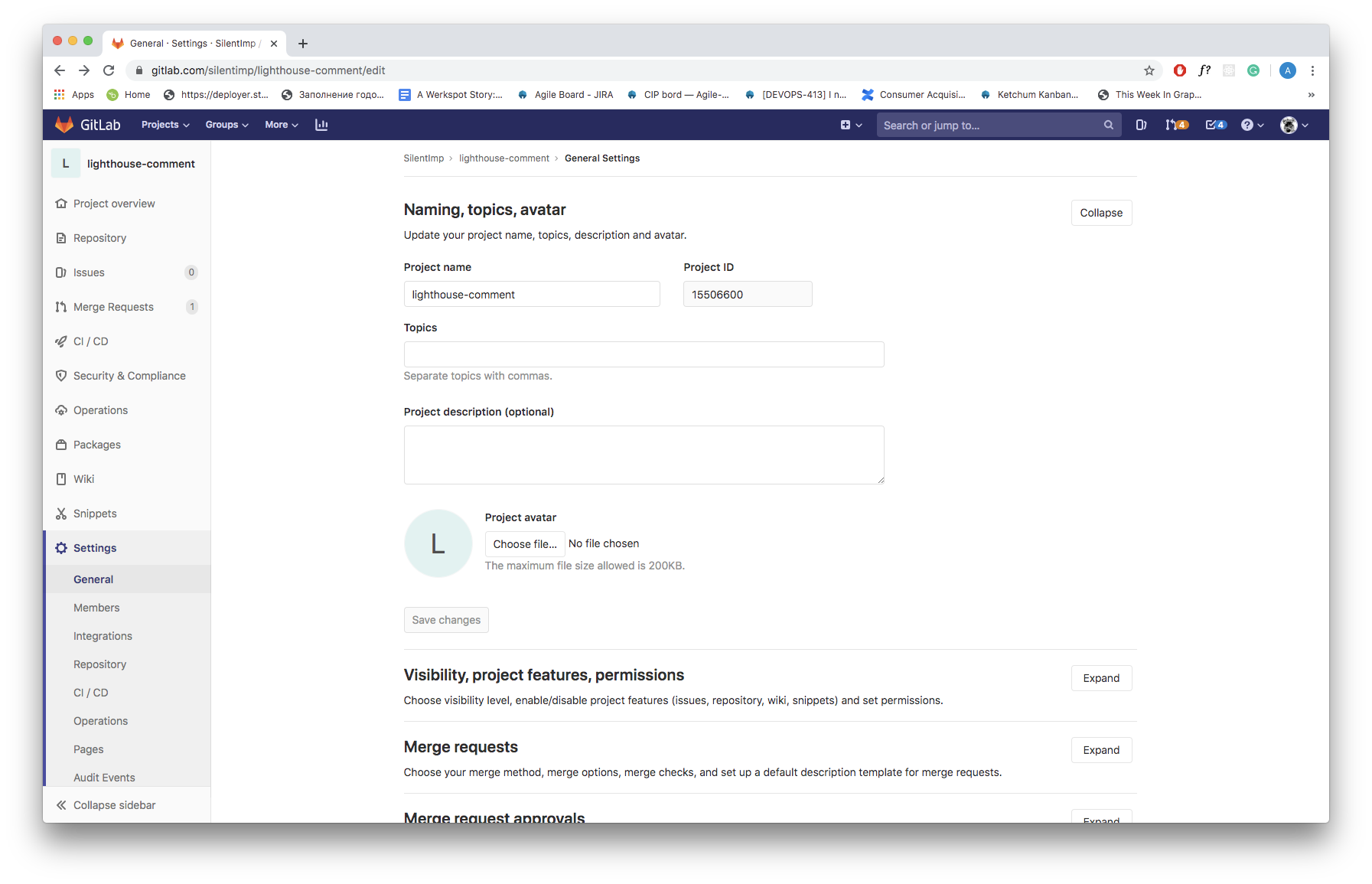
You will need to have a token to work with GitLab API. In order to generate one, you need to open GitLab, log in, open the ‘Settings’ option of the menu, and then open ‘Access Tokens’ found on the left side of the navigation menu. You should then be able to see the form, which allows you to generate the token.

Also, you will need an ID of the project. You can find it in the repository ‘Settings’ (in the submenu ‘General’):

To add a comment to the merge request, we need to know its ID. Function that allows you to acquire merge request ID looks like this:
// You can set environment variables via CI/CD UI.
// @see https://gitlab.com/help/ci/variables/README#variables
// I have set GITLAB_TOKEN this way
// ID of the project
const GITLAB_PROJECT_ID = process.env.CI_PROJECT_ID || '18090019';
// Token
const TOKEN = process.env.GITLAB_TOKEN;
/**
* Returns iid of the merge request from feature branch to master
* @param from {String} — name of the feature branch
* @param to {String} — name of the master branch
* @return {Number} — iid of the merge request
*/
const getMRID = async (from, to) => {
const response = await fetch(`https://${GITLAB_DOMAIN}/api/v4/projects/${GITLAB_PROJECT_ID}/merge_requests?target_branch=${to}&source_branch=${from}`, {
method: 'GET',
headers: {
'PRIVATE-TOKEN': TOKEN,
}
});
if (!response.ok) throw new Error('Merge request not found');
const [{iid}] = await response.json();
return iid;
};
We need to get a feature branch name. You may use the environment variable CI_COMMIT_REF_SLUG inside the pipeline. Outside of the pipeline, you can use the current-git-branch package. Also, you will need to form a message body.
Let’s install the packages we need for this matter:
npm i -S current-git-branch form-data
And now, finally, function to add a comment:
const FormData = require('form-data');
const branchName = require('current-git-branch');
// Branch from which we are making merge request
// In the pipeline we have environment variable `CI_COMMIT_REF_NAME`,
// which contains name of this banch. Function `branchName`
// will return something like «HEAD detached» message in the pipeline.
// And name of the branch outside of pipeline
const CURRENT_BRANCH = process.env.CI_COMMIT_REF_NAME || branchName();
// Merge request target branch, usually it’s master
const DEFAULT_BRANCH = process.env.CI_DEFAULT_BRANCH || 'master';
/**
* Adding comment to merege request
* @param md {String} — markdown text of the comment
*/
const addComment = async md => {
const iid = await getMRID(CURRENT_BRANCH, DEFAULT_BRANCH);
const commentPath = `https://${GITLAB_DOMAIN}/api/v4/projects/${GITLAB_PROJECT_ID}/merge_requests/${iid}/notes`;
const body = new FormData();
body.append('body', md);
await fetch(commentPath, {
method: 'POST',
headers: {
'PRIVATE-TOKEN': TOKEN,
},
body,
});
};
And now we can generate and add a comment:
cluster.on('message', (worker, msg) => {
report = [...report, ...msg];
worker.disconnect();
reportsCount++;
if (reportsCount === chunks.length) {
fs.writeFileSync(`./performance.json`, JSON.stringify(report));
+ if (CURRENT_BRANCH === DEFAULT_BRANCH) process.exit(0);
+ try {
+ const masterReport = await getArtifact('performance.json');
+ const md = buildCommentText(report, masterReport)
+ await addComment(md);
+ } catch (error) {
+ console.log(error);
+ }
process.exit(0);
}
});
Now create a merge request and you will get:

Resume
Comments are much less visible than widgets but it’s still much better than nothing. This way we can visualize the performance even without artifacts.
Authentication
OK, but what about authentication? The performance of the pages that require authentication is also important. It’s easy: we will simply log in. puppeteer is essentially a fully-fledged browser and we can write scripts that mimic user actions:
const LOGIN_URL = '/login';
const USER_EMAIL = process.env.USER_EMAIL;
const USER_PASSWORD = process.env.USER_PASSWORD;
/**
* Authentication sctipt
* @param browser {Object} — browser instance
*/
const login = async browser => {
const page = await browser.newPage();
page.setCacheEnabled(false);
await page.goto(`${DOMAIN}${LOGIN_URL}`, { waitUntil: 'networkidle2' });
await page.click('input[name=email]');
await page.keyboard.type(USER_EMAIL);
await page.click('input[name=password]');
await page.keyboard.type(USER_PASSWORD);
await page.click('button[data-testid="submit"]', { waitUntil: 'domcontentloaded' });
};
Before checking a page that requires authentication, we may just run this script. Done.
Summary
In this way, I built the performance monitoring system at Werkspot — a company I currently work for. It’s great when you have the opportunity to experiment with the bleeding edge technology.
Now you also know how to visualize performance change, and it’s sure to help you better track performance degradation. But what comes next? You can save the data and visualize it for a time period in order to better understand the big picture, and you can collect performance data directly from the users.
You may also check out a great talk on this subject: “Measuring Real User Performance In The Browser.” When you build the system that will collect performance data and visualize them, it will help to find your performance bottlenecks and resolve them. Good luck with that!
 (ra, il)
(ra, il)
Source link