
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Comment créer des interfaces utilisateur JavaScript résilientes —
Adopter la fragilité du Web nous permet de créer des interfaces utilisateur capables de s'adapter aux fonctionnalités qu'elles peuvent offrir, tout en offrant de la valeur aux utilisateurs. Cet article explore comment la dégradation gracieuse, le codage défensif, l'observabilité et une attitude saine envers les échecs nous équipent mieux avant, pendant et après qu'une erreur se produise.
Les choses sur le Web peuvent casser – les chances sont contre nous. Beaucoup de choses peuvent mal tourner : une requête réseau échoue, une bibliothèque tierce se casse, une fonctionnalité JavaScript n'est pas prise en charge (en supposant que JavaScript soit même disponible), un CDN tombe en panne, un utilisateur se comporte de manière inattendue (il double-clique sur un bouton de soumission), le la liste continue.
Heureusement, en tant qu'ingénieurs, nous pouvons éviter, ou au moins atténuer l'impact des pannes dans les applications Web que nous créons. Cela nécessite cependant un effort conscient et un changement d'état d'esprit pour penser à des scénarios malheureux autant qu'à des scénarios heureux.
L'expérience utilisateur (UX) n'a pas besoin d'être tout ou rien – juste ce qui est utilisable. Cette prémisse, connue sous le nom de dégradation gracieuse, permet à un système de continuer à fonctionner lorsque certaines parties de celui-ci sont dysfonctionnelles, un peu comme un vélo électrique devient un vélo ordinaire lorsque sa batterie meurt. Si quelque chose échoue, seule la fonctionnalité qui en dépend devrait être affectée.
Les interfaces utilisateur doivent s'adapter aux fonctionnalités qu'elles peuvent offrir, tout en offrant autant de valeur que possible aux utilisateurs finaux.
Pourquoi être résilient
La résilience est [intrinsèque au Web.
Les navigateurs ignorent les balises HTML non valides et les propriétés CSS non prises en charge. Cette attitude libérale est connue sous le nom de loi de Postel, qui est superbement véhiculée par Jeremy Keith dans Resilient Web Design :
« Même s'il y a des erreurs dans le HTML ou le CSS, le navigateur tentera toujours de traiter le informations, en sautant sur tous les éléments qu'il ne peut pas analyser. »
JavaScript est moins tolérant. La résilience est extrinsèque. Nous indiquons à JavaScript quoi faire si quelque chose d'inattendu se produit. Si une demande d'API échoue, il nous incombe de détecter l'erreur et de décider par la suite quoi faire. Et cette décision a un impact direct sur les utilisateurs.
La résilience renforce la confiance avec les utilisateurs. Une expérience de buggy reflète mal la marque. Selon Kim et Mauborgne, la commodité (disponibilité, facilité de consommation) est l'une des six caractéristiques associées à une marque à succès, ce qui rend la dégradation gracieuse synonyme de perception de la marque.
Une UX robuste et fiable est un signal de qualité et de fiabilité, qui alimentent la marque. Un utilisateur incapable d'effectuer une tâche parce que quelque chose est cassé sera naturellement déçu qu'il pourrait associer à votre marque.
Souvent, les défaillances du système sont qualifiées de « cas extrêmes » – des choses qui se produisent rarement, cependant, le Web a de nombreux coins. Différents navigateurs fonctionnant sur différentes plates-formes et matériels, respectant nos préférences d'utilisateur et nos modes de navigation (Safari Reader/technologies d'assistance), étant servis à des géolocalisations avec une latence et une intermittence variables augmentent la ressemblance de quelque chose qui ne fonctionne pas comme prévu.
Plus après. saut! Continuez à lire ci-dessous ↓
Error Equality
Tout comme le contenu d'une page Web a une hiérarchie, les échecs – les choses qui tournent mal – suivent également un ordre hiérarchique. Toutes les erreurs ne sont pas égales, certaines sont plus importantes que d'autres.
Nous pouvons classer les erreurs en fonction de leur impact. Comment XYZ ne fonctionne-t-il pas pour empêcher un utilisateur d'atteindre son objectif ? La réponse reflète généralement la hiérarchie du contenu.
Par exemple, un aperçu du tableau de bord de votre compte bancaire contient des données d'importance variable. La valeur totale de votre solde est plus importante qu'une notification vous invitant à vérifier les messages de l'application. La méthode de hiérarchisation de MOSCoWs classe le premier comme un incontournable, et le second comme un bon à avoir.

Si les informations primaires ne sont pas disponibles (c'est-à-dire que la demande réseau échoue), nous devons être transparents et informer les utilisateurs, généralement via un message d'erreur. Si les informations secondaires ne sont pas disponibles, nous pouvons toujours fournir l'expérience de base (indispensable) tout en masquant gracieusement le composant dégradé.

a href='/notifications' vers le centre de notification. ( Grand aperçu)Savoir quand afficher ou non un message d'erreur peut être représenté à l'aide d'un arbre de décision simple :

La catégorisation supprime la relation 1-1 entre les échecs et les messages d'erreur dans l'interface utilisateur. Sinon, nous risquons de bombarder les utilisateurs et d'encombrer l'interface utilisateur avec trop de messages d'erreur. Guidés par la hiérarchie du contenu, nous pouvons sélectionner les défaillances signalées à l'interface utilisateur et ce qui se passe à l'insu des utilisateurs finaux.

Mieux vaut prévenir que guérir
La médecine a un adage selon lequel il vaut mieux prévenir que guérir.
Appliqué au contexte de la construction d'interfaces utilisateur résilientes, il est plus souhaitable d'empêcher une erreur de se produire en premier lieu que de devoir récupérer D'un. Le meilleur type d'erreur est celui qui ne se produit pas.
Il est prudent de supposer de ne jamais faire d'hypothèses, en particulier lors de la consommation de données distantes, de l'interaction avec des bibliothèques tierces ou de l'utilisation de fonctionnalités linguistiques plus récentes. Les pannes ou les modifications imprévues de l'API ainsi que les navigateurs que les utilisateurs choisissent ou doivent utiliser sont hors de notre contrôle. Bien que nous ne puissions pas empêcher les casses hors de notre contrôle de se produire, nous pouvons nous protéger contre leurs effets (secondaires). Le pessimisme plutôt que l'optimisme favorise la résilience. L'exemple de code ci-dessous est trop optimiste :
const debitCards = useDebitCards();
revenir (
{debitCards.map(card => {
- {card.lastFourDigits}
})}
);
Cela suppose que les cartes de débit existent, le point de terminaison renvoie un tableau, le tableau contient des objets et chaque objet a une propriété nommée lastFourDigits. La mise en œuvre actuelle oblige les utilisateurs finaux à tester nos hypothèses. Il serait plus sûr et plus convivial si ces hypothèses étaient intégrées dans le code :
const debitCards = useDebitCards();
if (Array.isArray(debitCards) && debitCards.length) {
revenir (
{debitCards.map(card => {
if (card.lastFourDigits) {
retour - {card.lastFourDigits}
}
})}
);
}
renvoie "Autre chose" ;
L'utilisation d'une méthode tierce sans vérifier au préalable que la méthode est disponible est tout aussi optimiste :
stripe.handleCardPayment(/* ... */);
L'extrait de code ci-dessus suppose que l'objet stripe existe, qu'il possède une propriété nommée handleCardPayment et que cette propriété est une fonction. Il serait plus sûr, et donc plus défensif, si ces hypothèses étaient vérifiées par nous au préalable :
si (
type de bande === 'objet' &&
typeof stripe.handleCardPayment === 'fonction'
) {
stripe.handleCardPayment(/* ... */);
}
Les deux exemples vérifient que quelque chose est disponible avant de l'utiliser. Ceux qui connaissent bien la détection de caractéristiques peuvent reconnaître ce modèle :
if (navigator.clipboard) {
/* ... */
}
Le simple fait de demander au navigateur s'il prend en charge l'API Clipboard avant d'essayer de couper, copier ou coller est un exemple simple mais efficace de résilience. L'interface utilisateur peut s'adapter à l'avance en masquant la fonctionnalité du presse-papiers aux navigateurs non pris en charge ou aux utilisateurs qui n'ont pas encore accordé l'autorisation.

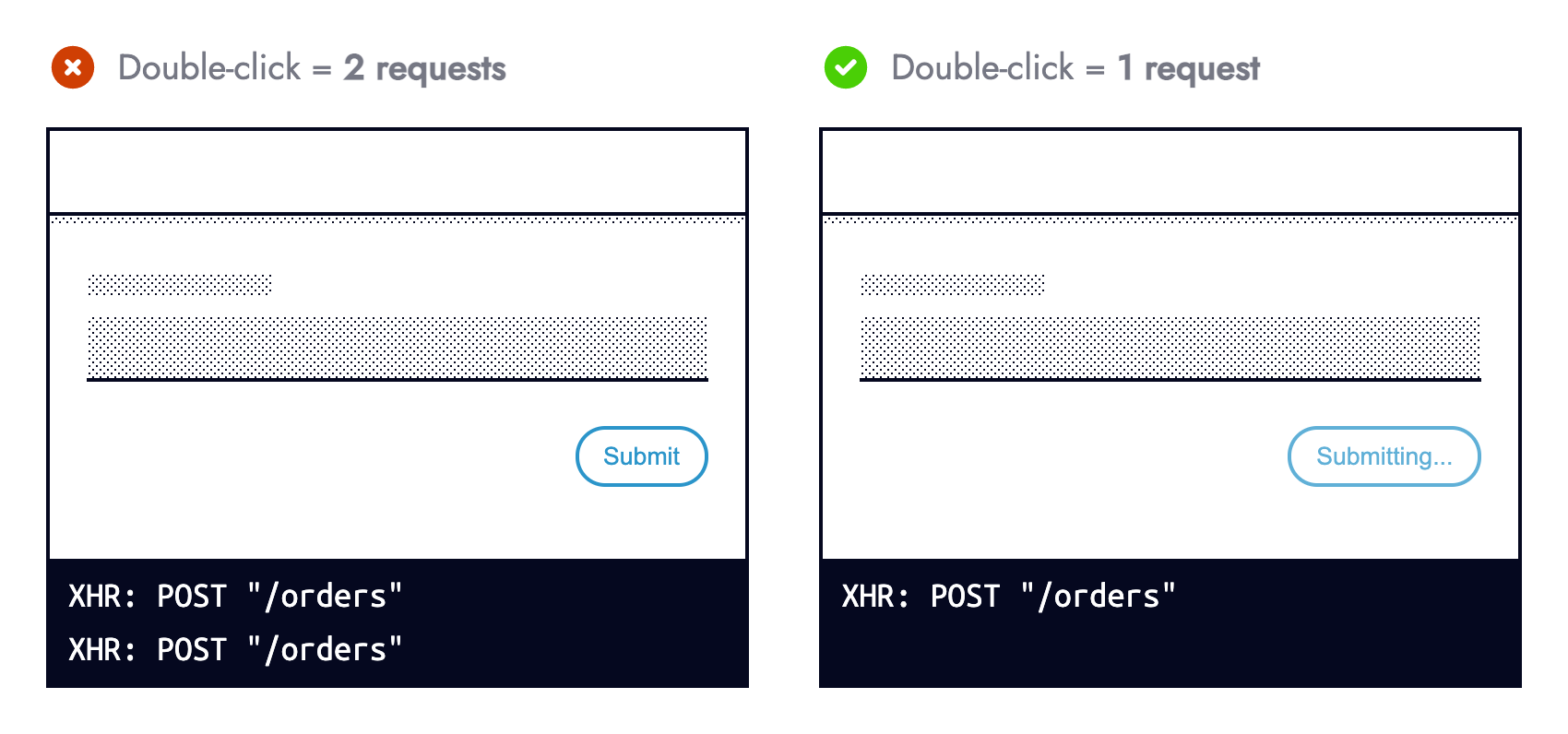
Les habitudes de navigation des utilisateurs sont un autre domaine hors de notre contrôle. Bien que nous ne puissions pas dicter la façon dont notre application est utilisée, nous pouvons installer des garde-corps qui empêchent ce que nous percevons comme une « utilisation abusive ». Certaines personnes double-cliquez sur les boutons – un comportement principalement redondant sur le Web, mais pas une infraction punissable.
Double-cliquer sur un bouton qui soumet un formulaire ne doit pas soumettre le formulaire deux fois, en particulier pour les méthodes HTTP non idempotentes . Lors de la soumission du formulaire, empêchez les soumissions suivantes pour atténuer les retombées de plusieurs demandes.

Empêcher la resoumission du formulaire en JavaScript en même temps que l'utilisation de aria-disabled="true" est plus utilisable et accessible que l'attribut HTML disabled. Sandrina Pereira explique Rendre les boutons désactivés plus inclusifs en détail.
Répondre aux erreurs
Toutes les erreurs ne sont pas évitables via une programmation défensive. Cela signifie que la réponse à une erreur opérationnelle (celles qui se produisent dans des programmes correctement écrits) nous incombe.
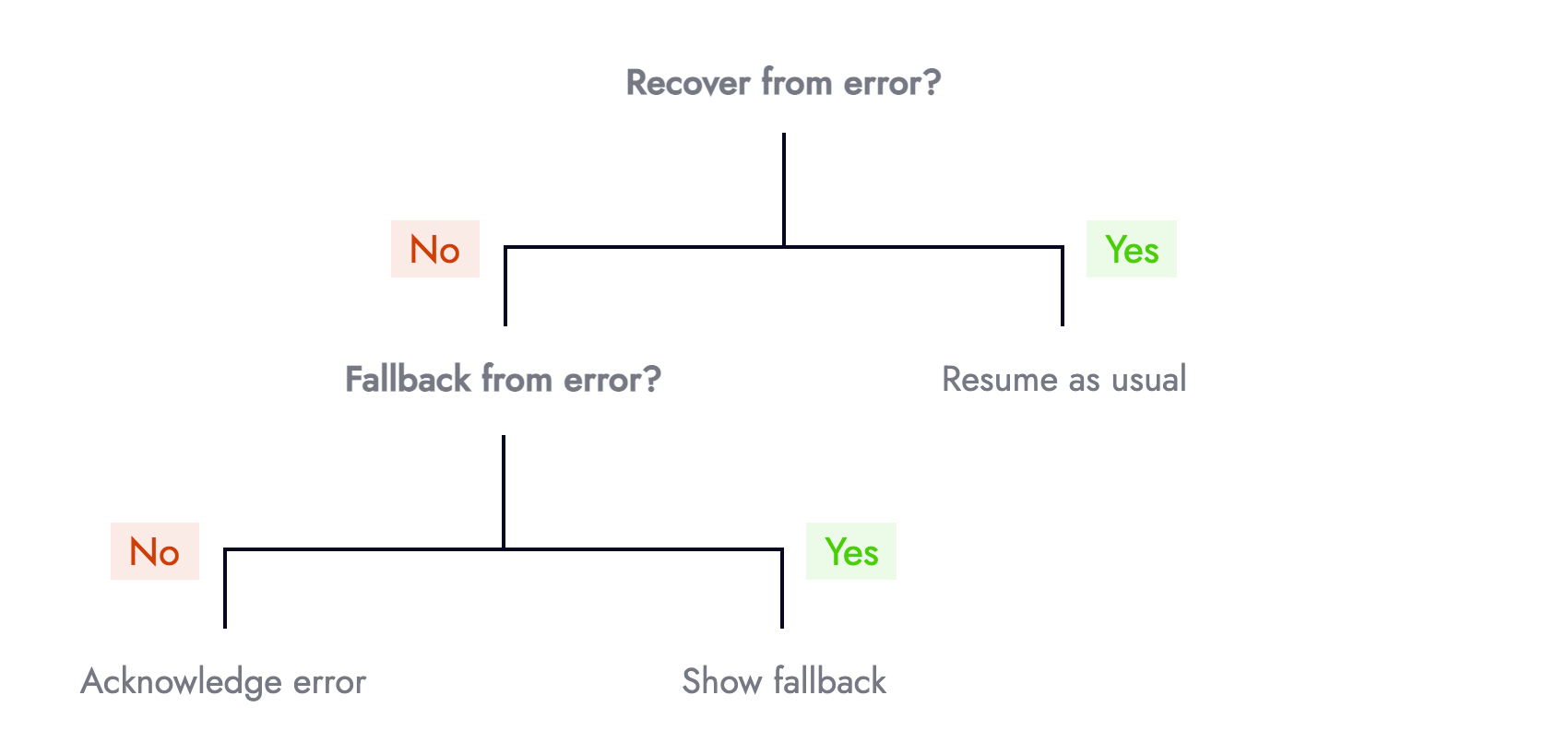
La réponse à une erreur peut être modélisée à l'aide d'un arbre de décision. Nous pouvons soit récupérer, revenir en arrière ou accuser réception de l'erreur :

Face à une erreur, la première question devrait être : « pouvons-nous récupérer ? » Par exemple, est-ce que la nouvelle tentative d'une requête réseau qui a échoué pour la première fois réussit lors des tentatives suivantes ? Des micro-services intermittents, des connexions Internet instables ou une éventuelle cohérence sont autant de raisons de réessayer. Les bibliothèques de récupération de données telles que SWR offrent cette fonctionnalité gratuitement.
L'appétit pour le risque et le contexte environnant influencent les méthodes HTTP que vous êtes à l'aise de réessayer. Chez Nutmeg, nous réessayons les lectures échouées (requêtes GET), mais pas les écritures (POST/ PUT/ PATCH/ DELETE). Il est plus sûr de tenter de récupérer des données (performances du portefeuille) à plusieurs reprises que de les muter (en soumettant à nouveau un formulaire).
La deuxième question devrait être : si nous ne pouvons pas récupérer, pouvons-nous fournir une solution de secours ? Par exemple, si un paiement par carte en ligne échoue, pouvons-nous proposer un autre moyen de paiement tel que PayPal ou Open Banking.

Les solutions de repli n'ont pas toujours besoin d'être aussi élaborées, elles peuvent être subtiles. Une copie contenant du texte dépendant de données distantes peut revenir à un texte moins spécifique lorsque la requête échoue :

La troisième et dernière question devrait être : si nous ne pouvons pas récupérer, ou replier, quelle est l'importance de cet échec (qui se rapporte à « Error Equality »). L'interface utilisateur doit reconnaître les erreurs principales en informant les utilisateurs que quelque chose s'est mal passé, tout en fournissant des invites exploitables telles que contacter le support client ou créer un lien vers des articles d'assistance pertinents.

Observabilité
L'adaptation des interfaces utilisateur à quelque chose qui ne va pas n'est pas la fin. Il y a un revers à la même médaille.
Les ingénieurs ont besoin de visibilité sur la cause profonde derrière une expérience dégradée. Même les erreurs non signalées aux utilisateurs finaux (erreurs secondaires) doivent se propager aux ingénieurs. Les services de surveillance des erreurs en temps réel tels que Sentry ou Rollbar sont des outils inestimables pour le développement Web moderne. Un message d'erreur s'affiche : Impossible de lire la propriété func de undefined. Au-dessous de l'erreur se trouve une trace de pile de l'endroit où l'exception a été levée »/>
La plupart des fournisseurs de surveillance des erreurs capturent automatiquement toutes les exceptions non gérées. La configuration nécessite un effort d'ingénierie minimal qui rapporte rapidement des dividendes pour un environnement de production sain amélioré et un MTTA (temps moyen de reconnaissance). Bien que cela implique plus d'efforts initiaux, cela nous permet d'enrichir les erreurs enregistrées avec plus de sens et de contexte, ce qui facilite le dépannage. Dans la mesure du possible, visez les messages d'erreur compréhensibles pour les membres non techniques de l'équipe.

L'extension de l'exemple Stripe précédent avec une branche else est le candidat idéal pour la journalisation explicite des erreurs :
if (
type de bande === "objet" &&
typeof stripe.handleCardPayment === "fonction"
) {
stripe.handleCardPayment(/* ... */);
} autre {
logger.capture(
"[Payment] Frais de carte — Impossible d'effectuer le paiement par carte car stripe.handleCardPayment n'était pas disponible"
);
}
Note : Ce style défensif n'a pas besoin d'être lié à la soumission de formulaire (au moment de l'erreur), cela peut arriver lorsqu'un composant est monté pour la première fois (avant l'erreur) nous donnant ainsi que le L'interface utilisateur a plus de temps pour s'adapter.
L'observabilité aide à identifier les faiblesses du code et les zones qui peuvent être renforcées. Une fois qu'une faiblesse fait surface, regardez si/comment elle peut être durcie pour éviter que la même chose ne se reproduise. Examinez les tendances et les zones à risque telles que les intégrations de tiers pour identifier ce qui pourrait être encapsulé dans un indicateur de fonctionnalité opérationnelle (autrement appelé kill switch).

Les utilisateurs prévenus de quelque chose qui ne fonctionne pas seront moins frustrés que ceux sans avertissement. Connaître les travaux routiers à l'avance aide à gérer les attentes, permettant aux conducteurs de planifier des itinéraires alternatifs. Lorsque vous traitez une panne (découverte, espérons-le, par la surveillance et non signalée par les utilisateurs), soyez transparent.

Rétrospectives
Il est très tentant de passer sous silence les erreurs.
Cependant, elles offrent de précieuses opportunités d'apprentissage pour nous et nos collègues actuels ou futurs. Il est crucial d'éliminer la stigmatisation de l'inévitabilité que les choses tournent mal. Dans La pensée de la boîte noirecela est décrit comme suit :
« Dans les organisations très complexes, le succès ne peut arriver que lorsque nous affrontons nos erreurs, apprenons de notre propre version d'une boîte noire et créons un climat où il est sûr d'échouer. »
Être analytique permet d'éviter ou d'atténuer la même erreur de se reproduire. Tout comme les boîtes noires de l'industrie aéronautique enregistrent les incidents, nous devons documenter les erreurs. À tout le moins, la documentation des incidents antérieurs aide à réduire le MTTR (temps moyen de réparation) si la même erreur se reproduit. quel était le problème, son impact, les détails techniques, comment il a été résolu et les actions qui devraient suivre l'incident.
Réflexions finales
Accepter la fragilité du Web est une étape nécessaire vers la construction de systèmes résilients. Une expérience utilisateur plus fiable est synonyme de clients satisfaits. Être équipé pour le pire (proactif) vaut mieux que d'éteindre des incendies (réactif) du point de vue de l'entreprise, du client et du développeur (moins de bugs !). offrir, tout en apportant de la valeur aux utilisateurs ;
Source link