
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Un cours de thérapie intensive pour votre forfait

Statoscope est un instrument qui analyse vos webpack-bundles. Créé par Sergey Melukov, il a commencé comme une version expérimentale fin 2016, qui est maintenant devenue une boîte à outils à part entière pour visualiser, analyser et valider les webpack-bundles.
Note de l'éditeur : cet article est une transcription du performance live de Sergey (russe).
En 2016, j'ai sorti la première version de l'outil, qui ne s'appelait alors pas Statoscope, mais Webpack Runtime Analyzer. Il s'agissait d'une démonstration technique d'un autre outil rempl créé par Roman Dvornov.
Nous voulions fournir une interface visuelle pour analyser les bundles en temps réel. Autrement dit, vous exécutez l'outil spécial dans votre navigateur et il vous montre ce qui se passe à l'intérieur de votre bundle : en quoi il consiste, fonctionne-t-il maintenant, quelles erreurs se sont produites. Au début, les utilitaires pour ces tâches étaient disponibles dans la console, mais pas dans le navigateur.
Après un an de travail sur le projet, j'étais à court d'idées, alors je l'ai mis en pause. Mais à peu près au même moment, j'ai commencé à travailler plus étroitement avec webpack, contribuant à son noyau. Ainsi, en 2018, j'ai voulu faire revivre Webpack Runtime Analyzer, en utilisant mon expérience nouvellement accumulée.
En octobre 2020, j'ai publié la première version de Statoscope. Fondamentalement, c'est la même chose que Webpack Runtime Analyzer mais dans un emballage différent et avec des fonctionnalités plus sophistiquées. Il s'agit simplement d'un outil plus élaboré et plus approfondi pour analyser votre bundle.
Analyse de contenu
C'est l'une des principales caractéristiques de Statoscope. Mais d'abord, voyons comment fonctionne le bundling et en quoi il consiste.
Voici une configuration assez typique avec deux points d'entrée :
module.exports = {
entrée : {
principal : './main.js',
administrateur : './admin.js',
},
}Il s'agit de la page principale et de la zone d'administration. Rien de spécial, apparemment.

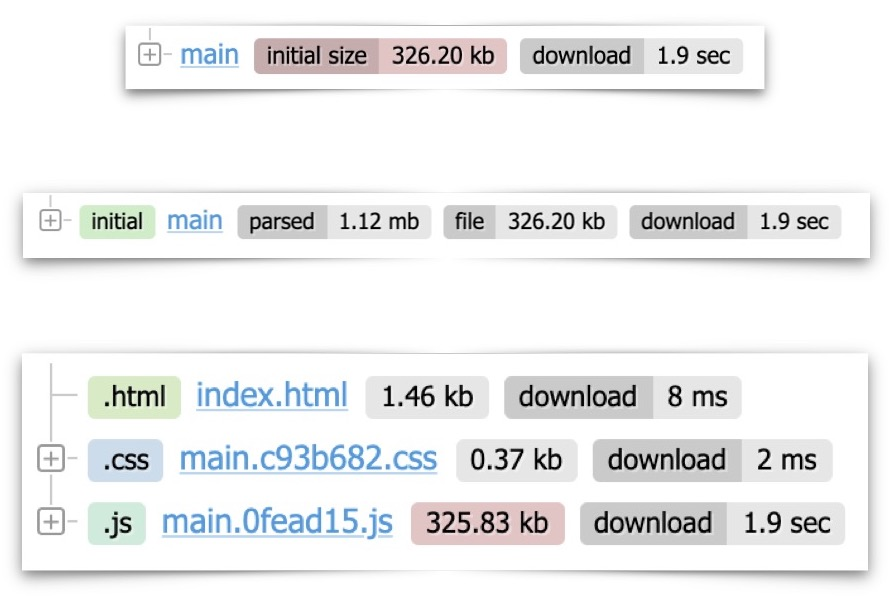
Lorsque nous exécutons le regroupement, Webpack définit chaque fichier JS ou TS comme un module. Le bundle est composé de nombreux modules JS (les carrés jaunes dans l'illustration ci-dessus).
Les modules sont formés en groupes – appelés morceaux (les carrés bleus). Il y a un groupe de modules pour la page principale, un autre pour la zone d'administration, et ainsi de suite (les carrés bleus). Ce sont les fichiers de sortie, que vous voyez dans le répertoire dist (ou buildselon la façon dont le vôtre est configuré). C'est avec cela que Webpack fonctionne.
Voyons les étapes du regroupement, afin que nous puissions mieux comprendre ce qui se passe.
- Wepback prend les modules JS, TS ou CSS en entrée et les analyse dans un « arbre de syntaxe » abstrait.
- Ensuite, Webpack définit les liens entre les modules. Par exemple, le module A importe le module B. Et le module B exporte quelque chose. En gros, un graphe de dépendances entre les modules est créé.
- Ensuite, Webpack optimise ce graphe. Ce n'est peut-être pas complètement efficace si nous utilisons des modules sous forme brute, tels qu'ils sont dans le système de fichiers : il peut y avoir des doublons, certains modules peuvent être combinés et d'autres ne sont que partiellement utilisés.
Autre exemple : un module a deux exportations, mais nous n'en utilisons qu'une. Nous n'avons pas besoin de la deuxième exportation, nous pouvons donc la supprimer sans douleur sans endommager le code fourni. Tout cela fait partie du processus d'optimisation de Webpack, afin de réduire la taille des ressources de sortie. - Webpack génère ensuite le contenu des fichiers qui se retrouveront dans le répertoire
dist. Il s'agit du rendu des actifs. - Enfin, ces fichiers sont fusionnés dans le répertoire.
Ce sont les étapes de base du fonctionnement de Webpack et de ce qu'il fait avec ces modules.
Plus après le saut ! Continuez à lire ci-dessous ↓
Avec quoi fonctionne Statoscope ?
Webpack fournit à Statoscope des informations sur tous les modules, morceaux et ressources qu'il rencontre pendant la construction traiter. Ils sont fournis sous la forme de ce qu'on appelle stats – un gros fichier stats.jsonque Webpack génère avec le bundle. Ce fichier est transféré au Statoscope (en fait, la plupart du temps, le Statoscope le prend lui-même). Statoscope lit le fichier et génère un rapport dans le navigateur que nous pouvons consulter, analyser, etc.
En bref, voici le processus : Webpack génère des statistiques et les envoie à Statoscope, qui génère ensuite un rapport HTML basé sur eux.
Comment recevoir des statistiques ?
Il y a deux façons. Tout d'abord, vous pouvez exécuter webpack avec l'argument --json et spécifier dans quel fichier enregistrer les stats. Ensuite, vous pouvez télécharger les stats sur le site sandboxque j'ai configuré spécifiquement pour que vous puissiez y déposer facilement vos stats et les analyser. C'est le moyen le plus simple d'obtenir un rapport Statoscope sans intégrer Statoscope n'importe où :
$ webpack –json stats.jsonCependant, je recommande la deuxième méthode, car elle collecte beaucoup plus d'informations sur votre bundle. Il vous suffit d'ajouter le plugin Statoscope à votre configuration de webpack.
config.plugins.push(new StatoscopeWebpackPlugin())C'est tout ! Ajoutez simplement le plug-in Statoscope à votre configuration de pack Web.
"modules": [/*…*/],
"morceaux": [/*…*/],
"actifs": [/*…*/],
"points d'entrée": {/*…*/},
/*…*/
}
Stats sont les informations internes de Webpack : quels modules, fichiers JS, TS et CSS ont été rencontrés, dans quels morceaux ces fichiers ont été combinés et les actifs qui en résultent. Tout cela est fusionné dans un seul gros fichier .jsonque Statoscope analyse ensuite.
Détails
Regardons quelques informations de module plus en détail :
{
"identifier": "babel-loader!./src/index.js",
"nom": "./src/index.js",
"raisons": [/*...*/],
/*...*/
}Par exemple : Notre fichier d'application principal, index.jsa un identifiant et un nom de fichier en tant que tels ; il est situé dans ce chemin. Dans la propriété reasonsnous pouvons voir où ce fichier est importé et où il est utilisé. C'est le type d'informations que Webpack fournit dans les stats.
Statoscope traite les statistiques, effectue une analyse et fournit une représentation visuelle pour interpréter les résultats sous une forme pratique :

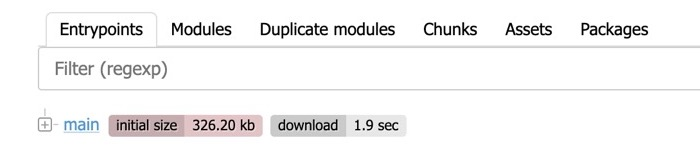
Toutes les choses que j'ai mentionnées ci-dessus sont ici : points d'entrée, modules, morceaux et ressources.

Dans l'image du milieu ci-dessus, on peut voir le morceau main qui est asynchrone.
Il existe généralement deux types de morceau :
initial
Celui-ci doit se charger lorsque la page est chargé.async
Celui-ci est le résultat d'une importation dynamique et peut ne pas se charger immédiatement sur la page ; d'où le nom,asynchrone. Si vous divisez votre application en parties dynamiques – par exemple, si vous disposez d'une grande bibliothèque d'animations qui ne doit être chargée que lorsque l'animation est nécessaire – il s'agit d'un blocasynchrone.
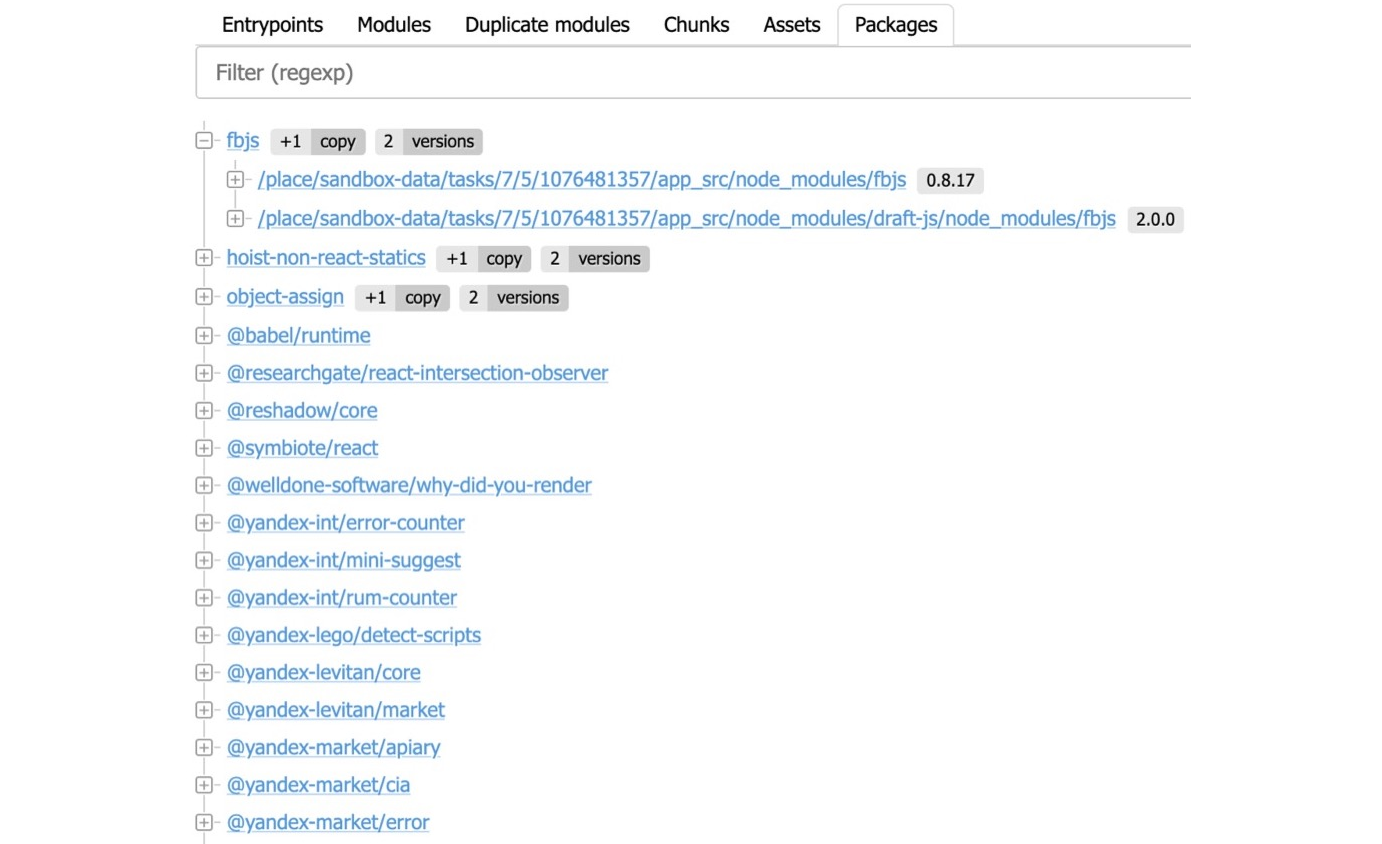
Copies de packages et Leurs versions

Sur la base de ces mêmes informations, Statoscope calcule également l'arborescence des packages – essentiellement le package npm qui est utilisé dans votre bundle : quels packages et combien de copies de chacun.
Vous pourriez avoir un situation lorsque vous configurez, par exemple, le package A et le package B. Ces deux packages utilisent tous deux le même package C, mais des versions différentes. Il s'avère que tout à coup un double du Package C apparaît dans votre bundle. Statoscope vous dit : « Vous avez deux versions du package fbjs. À la racine, la version 0.8.17 est utilisée, tandis que la version 2.0.0 est utilisée quelque part dans draft-js. Veuillez résoudre ce problème. Mettez à jour vos dépendances et le package en double a disparu. »
Comme vous pouvez le voir, Statoscope enrichit les stats avec quelques informations supplémentaires : par exemple, sur les versions de package. Initialement, Webpack stats n'inclut pas d'informations sur les versions de package. Plus tard, j'expliquerai comment cela se produit.
Si vous avez déjà utilisé d'autres outils pour analyser les statistiquespar ex. Webpack Bundle Analyzer, alors vous devriez être familiarisé avec la carte des modules.
La carte des modules fait partie de Statoscope. La différence est que Webpack Bundle Analyzer analyse les composants internes de Webpack plutôt que les stats. L'idée est fondamentalement la même, mais les approches sont différentes. Statoscope vous permet d'analyser des modules, des cartes de modules, des morceaux et des actifs – le tout en un seul endroit.
Nous pouvons ouvrir une page de package – par exemple, asn1 – et voir en quoi elle consiste. Vous voulez savoir pourquoi le colis pèse si cher ? Ouvrez simplement une page de package spécifique et jetez-y un coup d'œil.
Nous pouvons sélectionner les stats précédentes et actuelles, cliquer sur le bouton et Statoscope montrera ce qui a changé, généralement : quels modules étaient présents, lesquels ont été créés, supprimés, ajoutés ou simplement modifiés (par exemple, la taille monnaie); quels morceaux ont été ajoutés, modifiés, supprimés, etc.
Par exemple, disons que les stats actuelles proviennent de votre branche feature actuelle. Vous créez une fonctionnalité géniale, et les stats « avant » pourraient être stats de la branche master. Vous voulez savoir : ma nouvelle fonctionnalité va-t-elle alourdir le bundle ? Ai-je aggravé ce qui est actuellement dans le master ? Vous pouvez demander ces choses à Statoscope, et il vous dira si la situation s'est aggravée (ou améliorée) et comment.
Rapports personnalisés
Si Statoscope ne vous fournit pas suffisamment de rapports, vous pouvez générer vos propres rapports. .
Mais il y a quelques problèmes que Statoscope peut également résoudre.
Les statistiques sont de gros fichiers .jsonqui peuvent atteindre plusieurs gigaoctets. Ce fichier a son propre format, et pour extraire des données, il est souvent nécessaire d'écrire beaucoup de code. Probablement, personne ne veut écrire ce code, surtout s'il y en a beaucoup. Si seulement il y avait un moyen plus simple…
Jora
Une solution à ce problème est un langage de requête appelé jora.
Voici du code JS que nous pouvons utiliser pour extraire du stat une liste de modules et triez-les par nom :
const modules = [] ;
pour (const compilation de compilations) {
pour (module const de compilation.modules) {
modules.push(module);
}
}
modules.sort((a, b) => a.name.localeCompare(b.name))Et voici un petit morceau de code dans Jora, qui fait exactement la même chose.
compilations.modules.sort (=>nom)Nous disons : prenez toutes les compilations, et prenez-en tous les modules, et triez-les par nom. C'est tout !
Comme vous pouvez le voir, Jora nous permet de réduire la quantité de code JS que nous écrivons. C'est un langage léger, sémantique et compréhensible pour les requêtes en JSON.
Si vous avez déjà travaillé avec des bibliothèques comme jqalors vous le connaissez.
Voici trois exemples de Jora. :
Filtrer
les modules.[size > 1000]On peut dire : donnez-moi tous les modules qui sont plus grands que mille octets.
Mappez
les modules.({module : $, size} )Nous voulons convertir des modules en un autre objet. Nous disons : donnez-moi des modules et ajoutez-leur des tailles. Nous aurons maintenant un objet avec deux champs : module et taille. Simple et concis.
Map Call
modules.(getModuleSize(hash)).sizeNous créons une carte et pour obtenir l'objet résultant, nous générons également une fonction qui nous renvoie l'objet.[19659098]UI
Nous avons donc compris comment Statoscope nous permet de faire des requêtes de statistiques et de créer des rapports à l'aide du langage de requête Jora. Mais comment l'afficher ? Nous avons besoin d'une interface utilisateur – nous ne pouvons pas simplement afficher la structure de l'objet JS. Nous voulons ajouter la liste, le titre, les boutons et les badges.
Il semble que nous puissions créer l'interface utilisateur dans React. Mais ensuite, nous rencontrons d'autres problèmes : l'interface doit être regroupée et hébergée quelque part. Statoscope fournit un moyen de résoudre ce problème.
Discovery.js est une plate-forme pour l'interface utilisateur déclarative.

Vérifiez cet exemple. Sur la gauche, vous pouvez voir les éléments d'interface utilisateur prédéfinis. Discovery.js contient un kit d'interface utilisateur prêt à l'emploi : boutons, titres, badges, indicateurs, etc. Tout est prêt à être utilisé.
Mais la principale caractéristique est que vous pouvez décrire la "mise en page" (composition des vues) avec JSON.

C'est-à-dire que nous disons : j'ai besoin d'un indicateur, le libellé et la valeur seront tels quels.
Discovery.js créera une vue HTML au lieu du JSON. En créant une composition à partir de tels objets JSON, vous pouvez créer vos propres rapports.
Avec l'aide de jora, vous recevez des données ; avec 'layout' dans Discover.js vous obtenez une vue. Rassemblez-les et vous obtenez un rapport.
Mettre tout ensemble
Voici à quoi ça ressemble :

Si vous cliquez sur le bouton Créer un rapport dans Statoscope, puis en haut, vous pouvez saisir n'importe quelle requête dans Jora, dans le champ ci-dessous, vous pouvez saisir l'interface utilisateur – c'est-à-dire décrire la mise en page dans le JSON formulaire, et en dessous vous obtenez votre rapport.
Dans cet exemple, nous prenons les modules de toutes les compilations et les trions par taille. Nous obtenons un rapport super simple. Les modules les plus lourds seront en haut.
Un avantage supplémentaire est que nous pouvons partager un lien vers le rapport avec des collègues. Par exemple, vous avez exécuté un rapport dans CI, l'avez analysé et compris que quelque chose ne fonctionnait pas correctement. Créez simplement le rapport, copiez le lien directement dans CI et envoyez-le à votre collègue. Votre collègue l'ouvrira et verra exactement le même rapport que vous. Si simple.
C'est une façon de générer des rapports personnalisés lors de vos déplacements. Nous avons cliqué sur "Créer un rapport", rédigé une requête Jora, utilisé la mise en page Discovery.js et voila : obtenu un rapport, c'est bon.
Intégration dans l'interface utilisateur
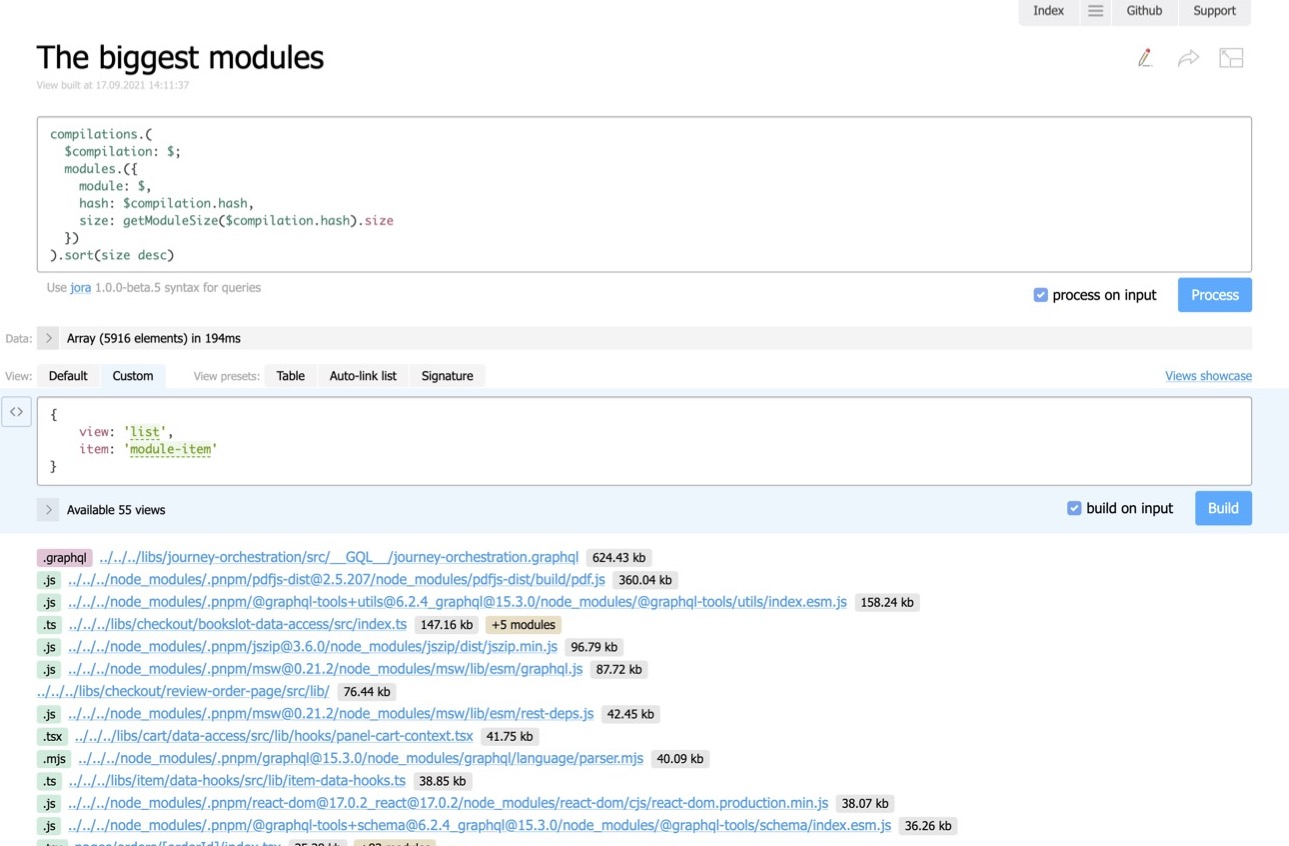
Des rapports personnalisés comme ceux-ci peuvent également être intégrés à vos rapports dans CI, à l'aide du plug-in Statoscope pour Webpack. Ce plugin a la propriété reportsque vous dites : intégrez mon rapport personnalisé dans mon rapport HTML. C'est pratiquement la même chose que la variante précédente, mais ici nous n'avons que les 20 modules les plus lourds ; nous avons coupé la bordure inférieure.
nouveau StatoscopeWebpackPlugin({
rapports : [
{
id: 'top-20-biggest-modules',
name: 'Top 20 biggest modules',
data: { some: { custom: 'data' } }, // or () => fetchAsyncData()
view: {
{
data: `#.stats.compilations.(
$compilation: $;
modules.({
modules: $,
hash: $compilation.hash,
size: getModuleSize($compilation.hash)
})
).sort(size.size desc)[:20]`,
Afficher la liste',
item : 'module-item',
},
},
},
],
})Le nom du rapport est sur la 5ème ligne, les données sur la 6ème – si nous en avons besoin. Nous pourrions en avoir besoin, par exemple, si nous voulons créer un rapport personnalisé avec des métriques sur la façon dont notre bundle a changé. Nous pouvons importer des informations de notre stockage de métriques dans les données. Par exemple, nous pouvons enregistrer le temps de construction moyen quotidien du bundle, l'envoyer au stockage avec les métriques, puis l'intégrer dans le rapport personnalisé. Nous disons : prenez les mesures à partir de là et créez un rapport d'interface utilisateur avec un graphique linéaire montrant comment notre offre a changé au fil du temps. Discovery.js peut également créer des graphiques comme celui-ci. Tellement pratique.
Les rapports que vous intégrez dans le rapport de l'interface utilisateur apparaissent dans un menu déroulant comme celui-ci :

Vous pouvez partager ce rapport avec des collègues. Rappelez-vous la différence : dans le premier cas, vous créez votre rapport en déplacement et le partagez avec vos collègues ; dans ce cas, vous intégrez votre rapport dans le HTML, que vous obtenez dans CI. Ce ne sera pas un lien avec la requête, la vue, etc. codés dans les paramètres GET ; ce rapport sera véritablement intégré au HTML.
Validation
C'est une chose très intéressante et très importante. Pourquoi est-ce si important pour moi ? Je m'y suis pris pendant des semaines, essayant de trouver comment valider stats. Je veux le configurer de manière à ce que nos demandes d'extraction ne se retrouvent pas dans le maître au cas où elles aggraveraient la qualité de notre bundle (par exemple en augmentant la taille du bundle ou le temps de construction). Le maître n'a pas besoin de ça.
Comment faciliter le processus de validation ? J'ai regardé autour de moi, mais je n'ai pas trouvé de solutions simples.
J'ai essayé différentes façons de trouver quelque chose moi-même, en essayant et en échouant, en essayant et en échouant… mais finalement j'ai réussi. C'est ainsi que Statoscope CLI est né. C'est un utilitaire de console qui vous permet de valider les statistiques.
Installer CLI
npm install -D @statoscope/statoscope/stats-validator-plugin-webpackInstaller le plugin de validation des bundles webpack
npm install -g @statoscope/cliComment ça marche ? Je ne voulais pas inventer quelque chose de complètement nouveau, alors voici un ESLint qui vous sera familier. Il vous permet de trouver et de résoudre les problèmes dans vos fichiers JS/TS. Si quelque chose ne va pas, comme si notre code ne respecte pas les règles de la configuration ESLint, nous sommes informés de l'erreur dans la console. Si les vérifications échouent dans CI, vous devez aller les réparer.
Je voulais faire quelque chose de similaire pour ne pas avoir à réinventer la roue. Il y a déjà beaucoup de choses sympas comme Jora et Discovery.js. Nous avons donc décidé d'utiliser l'utilitaire console Statoscope CLI ainsi que le plugin de validation webpack-stats (pour webpack stats à valider).
Pour le moment, Statoscope ne fonctionne qu'avec webpack statsmais idéalement, ce sera une plate-forme pour n'importe quel bundler. C'est pourquoi j'ai fait des efforts pour sculpter architecturalement chaque élément de la boîte à outils (ce n'est pas pour rien qu'il s'agissait d'une boîte à outils) afin qu'elle fonctionne comme un plugin, pas comme quelque chose de codé en dur. Et j'y arrive, petit à petit.
Alors, on installe Statoscope CLI et le plugin webpack pour valider précisément webpack stats. Si vous avez Rollup, vous aurez à l'avenir un plugin précisément pour ses statsou de même pour esbuild stats. C'est comme dans ESLint : si vous voulez vérifier les fichiers TypeScript, vous installez le plugin correspondant ; si vous voulez vérifier autre chose, vous installez un plugin séparé et configurez les règles.
Voici à quoi ressemble la configuration du Statoscope pour la validation (en fait, pas seulement pour la validation) :
module.exports = {
valider : {
// utilise un plugin avec des règles spécifiques au webpack
greffons : ['@statoscope/webpack'},
reporters: [
// use console reporter
'@statoscope/console',
// use reporter that generated an HTML-report with validation results
['@statoscope/stats-report', {open: true}],
].
des règles: {
// une règle qui échoue à la validation si le temps de construction est dégradé d'au moins 10 secondes
'@statoscope/webpack/build-time-limits' : ['error', {global: 10000}],
// vous pouvez utiliser d'autres règles
}
}
}Ici, tout ressemble à ESLint – encore une fois, pas besoin de réinventer la roue. Nous avons des plugins pour valider les stats avec.
Nous avons des reporters pour signaler le résultat de la validation. Pour l'instant, Statoscope a deux rapports intégrés : un rapport de console (qui envoie tout à la console) et stats-report (qui génère des rapports). La génération de rapports est une fonctionnalité majeure de la validation, car il est difficile de rechercher et d'analyser des messages d'erreur en grand nombre.
Ensuite, je souhaite connecter ces messages d'erreur à des modules spécifiques. Je veux ouvrir un module et voir quels messages y sont liés. Faire cela dans la console est impossible : le format texte n'est pas interactif, et je ne veux pas faire de trucs d'interface utilisateur vraiment compliqués.
Dans la propriété rules, nous disons quelles règles nous voulons appliquer à la validation. Il y a environ 12 règles maintenant. Par exemple, il existe des règles pour budgétiser la taille du bundle, la taille initiale du bundle et la taille de chargement du bundle côté client.
Par exemple, vous ne voulez pas de demandes d'extraction, ce qui augmente le temps de téléchargement de votre bundle. sur 3G lente — pour se retrouver dans le maître. Ainsi, vous définissez la règle, que Statoscope possède déjà.
Vous pouvez accéder au référentiel de Statoscope et trouver la documentation sur chaque règle. Il existe des règles pour de nombreuses situations diverses, par exemple "ne pas autoriser l'utilisation de copies de package". S'il vous arrive de faire une pull request qui ajoute un double, cette requête ne sera pas acceptée, et vous serez renvoyé pour la refaire (ce genre de chose arrive en CI). assez simple. Nous lançons ceci dans la console :
$ statoscope validate --input ./stats.jsonNous saisissons la commande statoscope validatequi nous permet de valider, et nous indiquons sur laquelle stats-fichier, nous voulons exécuter un test. Nous recevons un rapport (dans la console et le navigateur).
Nous avons ici validé un fichier stats. Mais en plus d'une règle qui analyse un seul fichier stats (comme "y a-t-il des doublons ?"), pouvons-nous créer une règle qui compare, par exemple, de combien vous avez augmenté la taille du bundle ? Par exemple, vous ne voulez pas augmenter plus de 2 %. Pour cela, vous devez utiliser les stats de la branche actuelle et de la branche principale.
Donc, un peu de terminologie :
input
Un fichierstatsactuel ( de votre agence).référence
Le fichierstatsprécédent avec lequel la référence est faite (du maître).
Réception d'un rapport
Regardons ce que nous vu dans la console, mais dans un format digeste :

C'est un arbre où tout est mis en évidence, des éléments peuvent être cachés ou révélés, ils peuvent être des liens (vous pouvez vérifier le message d'erreur, ou à quelle erreur il est lié). Ici, vous pouvez même filtrer en utilisant le champ ci-dessus. C'est beaucoup plus pratique que d'utiliser des outils de type grep et d'analyser la sortie de la console.
Requêtes de statistiques
Passons à la partie suivante concernant la CLI. Pourquoi pourrions-nous avoir besoin de requêtes stats ?
Voici votre stats.json : des informations sur les modules, les blocs et les actifs. Nous voulons obtenir à partir des stats la taille ou la longueur de votre paquet. Vous pourriez en avoir besoin, par exemple, pour créer des commentaires personnalisés pour votre pull request ou pour envoyer des métriques.
Si vous n'avez accès qu'à la partie visuelle, cela devient un problème : on ne sait pas comment en extraire les données. Mais vous avez l'utilitaire de console requête du statoscopeavec lequel nous pouvons tout résoudre. Cela nous permet de faire une requête Jora.

Sous la ligne verte : quelle requête voulons-nous effectuer ; sous le bleu : quelles statistiques nous voulons interroger. Par exemple, nous disons : donnez-nous le nombre de modules. Et l'utilitaire répond.
Nous pouvons faire n'importe quelle requête Jora et l'enregistrer dans un fichier séparé. Donc, nous pouvons dire : donnez-moi la requête du fichier query.joraenvoyez-la à la requête du statoscope, appliquez-la à ces statspuis enregistrez le résultat dans le result.json.

Par exemple, nous voulons joindre le nombre d'erreurs de validation au commentaire de la pull request – s'il vous plaît !
CI – Mettre tout ensemble
Voyons ce qui se passe si nous réunissons la validation et la requête du statoscope. Je vais montrer cela sur la base des actions Github. (du maître). Comment les obtient-on et les stocke-t-on ? Pour chaque commit dans le maître, nous créons un bundle (si nous avons commis quelque chose dans le maître, cela signifie que tout va bien). Nous en obtenons les statsappelons le fichier reference.json et l'envoyons à notre stockage d'artefacts, ce qui peut être n'importe quoi.
Si nous parlons de GitHub, il y a déjà un stockage d'artefacts intégré. Nous n'avons rien à faire de spécial, dites simplement télécharger l'artefact. À partir de là, vous avez stats du maître et elles sont enregistrées quelque part.
Commits In Pull Requests
Mais le plus intéressant : nous avons aussi des commentaires dans les pull requests. Pour chaque commit dans une pull request, nous construisons le bundle, récupérons le webpack statsappelons ce fichier input.jsontéléchargeons l'artefact reference.json de l'étape précédente, et vous avez maintenant deux fichiers. Nous donnons ces deux stats au statoscope pour valider (nous obtenons un report.html) et la requête du statoscope (nous obtenons un result.json).
C'est ce! Nous avons un rapport d'interface utilisateur et des données personnalisées à partir de la requête, et nous pouvons maintenant créer (par exemple) des commentaires personnalisés au nom de notre bot.

Comment pouvons-nous faire cela ? Voyons voir. Le texte du commentaire sera des données de la requête, plus une sorte de modèle. Je vais donner une requête Jora comme exemple – ce n'est pas aussi long que cela puisse paraître :

Il obtient le temps de construction à partir de deux stats (référence et entrée), soustrait l'une de l'autre et obtient la différence – pour le meilleur ou pour le pire. La même chose se produit avec la taille initiale : combien notre paquet a grossi ou diminué. Il examine également le nombre d'erreurs de validation et le vide dans JSON.
Voici notre modèle de commentaire :
Note : J'ai choisi le moteur de template moustachemais ça pourrait être n'importe quel autre.

Nous disons : le temps de construction a changé comme ça, la taille initiale comme ça, le nombre d'erreurs de validation comme ça. Et un lien vers le rapport complet.
Donc, voici ce que nous obtenons : nous attachons un commentaire aux demandes d'extraction au nom de notre bot.
 Grand aperçu
Grand aperçu
Nous faisons tout cela dans le cadre de notre processus, notre CI. Nous avons une gamme de vérifications comme la vérification de notre code, et dans une étape distincte, nous avons la vérification Statoscope : validations, téléchargement d'artefacts, nos propres requêtes et création de commentaires. Ce sont des étapes distinctes. Dans ce cas, nous avons une croix rouge à côté de la vérification du statoscope, ce qui signifie que quelque chose s'est mal passé lors de la validation.
Vous voulez savoir quoi ? Accédez simplement au rapport de l'interface utilisateur à partir du commentaire et profitez. . Ce n'est pas quelque chose d'éphémère que je viens de montrer ; tout fonctionne déjà, pour chaque demande d'extraction dans ce référentiel, un rapport sera généré. Vous pouvez saisir une demande d'extraction de test et voir ce qui se passe. (Le code source de chaque action Github se trouve dans le fichier workflowsvous pouvez donc voir comment tout cela fonctionne.)
Plans
À la fin de cet article, je vais vous parler de nos projets à venir, car ils sont énormes.
- Format
statistiquespersonnalisé.
N'oubliez pas que j'emmène Statoscope vers l'indépendance de tout bundle spécifique. Mais afin de ne pas le bloquer de différents formats destatsje veux tous les transformer en un seul format universel. - Je veux vraiment vous laisser étendre l'interface utilisateur.
Généralement, l'extensibilité est une particularité clé du projet, vers lequel je travaille. Je veux que Statoscope soit étendu avec des plugins. - Le support d'autres bundlers.
Je veux dissocier Statoscope de webpack, afin qu'aucune mention de webpack ne soit faite dans Statoscope – seulement dans les plugins. - Processus plus simple.
Je souhaite combiner le processus d'intégration dans CI en une seule action Github et la publier sous forme de package, afin de ne pas copier et coller le code source mais plutôt installer Github Action et l'utiliser. Si vous allez dans le référentiel, vous verrez le dossier packages, et il y a essentiellement de la documentation pour certains packages. J'aimerais vraiment un portail unique pour la documentation – quelque chose comme la façon dont Jest l'a fait (j'adore la façon dont ils l'ont fait). est apparu sous forme de démo sous le nom de Webpack Bundle Analyzer en 2016).
L'idée est que si vous utilisez un bundle dans un mode montre comme HMR (Hot Module Replacement), vous ouvrez votre navigateur et vous aurez directement accès à Statoscope in the developer tools in the browser. You change something in the source code (like properties of some React component), you save it, HMR works it out for you, Statoscope is in the develop tools of your browser as well, and you don’t need to generate reports constantly. - Analysis of the bundler config.
Configuration, in particular webpack, is of course a separate story and a separate skill. And I really want to provide colleagues with some advice and modify the config in real time, so that it is effective. When Statoscope has functionality like this, it will be easier to make effective bundles. - Recommendation on the optimization of bundles.
I would like Statoscope to be able to say: “Listen colleague, you’ve got this thing wrong, you can optimise something here — make these changes, and you’ll reduce the size of your bundle by this many megabytes.” - Redesign.
I want to give special thanks to my colleague Danil Avdoshin, who found the free time to work on the redesign. For now it’s only saved in Figma prototypes, but I’m sure that we’ll get round to finishing it soon. - And my personal dream: bundle rating.
I want to be able to compare the quality of bundles. For now, I’m just thinking about how to do this, but I would like to see the top bundles in terms of configuration efficiency, the efficiency of using webpack possibilities, and so on.
Why am I telling you about my plans? Statoscope is a fully open-source project, so I welcome issues and pull requests. I quickly respond to issues. If you want to participate in a serious project, you can help with any of the points above.
Here’s how Danila designed how it could look:

The point here is the flexible UI: you can customize which blocks you need on the page, and decide generally what you want to show. For example, I don’t need a list of modules, but instead I can show a chart in that space.
Danila designed this prototype, it’s in Figma, you can also contribute here. I’ll get there eventually, but meanwhile, you can help.
Call To Action
Finally, what I’m asking for in this article:
- Try
statoscope.tech. It’s a sandbox, there’s demo data, and you can load your own. - Try
@statoscope/webpack-plugin. Remember, this plugin collects much more information than webpack itself provides. - Try
@statoscope/clifor validation, queries and creating commentaries. By the way, Statoscope is currently used in Andrei Sitnik’ssize-limitpackage. Not long ago we integrated it there together, replacing Webpack Bundle Analyzer. Now when you runsize-limitwith the--why(“Why did the size increase”), Statoscope will open. - Share feedback, ask questions.
- Get familiar with Jora. It’s a simple, concise language without too many constructions. And you’ll be able to write reports at least, and then rules.
- Take a look at
Discovery.js. - Write your report.
- Write your validation rule.
- Write your permission.
- Bring your PR/Issue.
- Put a star on GitHub. I’d like that. 🙂
Source link