
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
TinyML apporte des modèles d'apprentissage en profondeur aux microcontrôleurs

Cet article fait partie de nos revues d'articles de recherche sur l'IAune série d'articles qui explorent les dernières découvertes en matière d'intelligence artificielle.
Les modèles d'apprentissage en profondeur doivent leur succès initial aux gros serveurs avec de grandes quantités. de mémoire et des grappes de GPU. Les promesses de l'apprentissage en profondeur ont donné naissance à toute une industrie de services de cloud computing pour les réseaux de neurones profonds. Par conséquent, les très grands réseaux de neurones fonctionnant sur des ressources cloud pratiquement illimitées sont devenus très populaires, en particulier parmi les entreprises technologiques riches qui peuvent payer la facture.
Mais en même temps, ces dernières années ont également vu une tendance inverse, un effort concerté pour créer des modèles d'apprentissage automatique pour les appareils de pointe . Appelés TinyML ou TinyML, ces modèles conviennent aux appareils qui ont une mémoire et une puissance de traitement limitées, et dans lesquels la connectivité Internet est soit absente, soit limitée.
Le dernier de ces efforts, un travail conjoint d'IBM et le Massachusetts Institute of Technology (MIT), s'attaque au goulot d'étranglement de la mémoire de pointe des réseaux de neurones convolutifs (CNN), une architecture d'apprentissage en profondeur particulièrement critique pour les applications de vision par ordinateur. Détaillé dans un article présenté à la conférence NeurIPS 2021, le modèle s'appelle MCUNetV2 et peut exécuter des CNN sur des microcontrôleurs à faible mémoire et faible consommation.
Pourquoi TinyML ?
 le deep learning dans le cloud a connu un énorme succès, il n'est pas applicable dans toutes les situations. De nombreuses applications nécessitent une inférence sur l'appareil. Par exemple, dans certains contextes, tels que les missions de sauvetage par drone, la connectivité Internet n'est pas garantie. Dans d'autres domaines, tels que les soins de santé, les exigences et réglementations en matière de confidentialité rendent très difficile l'envoi de données vers le cloud pour traitement. Et le retard causé par l'aller-retour vers le cloud est prohibitif pour les applications qui nécessitent une inférence ML en temps réel.
le deep learning dans le cloud a connu un énorme succès, il n'est pas applicable dans toutes les situations. De nombreuses applications nécessitent une inférence sur l'appareil. Par exemple, dans certains contextes, tels que les missions de sauvetage par drone, la connectivité Internet n'est pas garantie. Dans d'autres domaines, tels que les soins de santé, les exigences et réglementations en matière de confidentialité rendent très difficile l'envoi de données vers le cloud pour traitement. Et le retard causé par l'aller-retour vers le cloud est prohibitif pour les applications qui nécessitent une inférence ML en temps réel.
Toutes ces nécessités ont rendu le ML sur l'appareil à la fois scientifiquement et commercialement attrayant. Votre iPhone exécute maintenant la reconnaissance faciale et la reconnaissance vocale sur l'appareil. Votre téléphone Android peut exécuter la traduction sur l'appareil. Votre Apple Watch utilise l'apprentissage automatique pour détecter les mouvements et les schémas ECG.
Ces modèles ML sur l'appareil ont été en partie rendus possibles par les progrès des techniques utilisées pour rendre les réseaux de neurones compacts et plus efficaces en termes de calcul et de mémoire. Mais ils ont également été rendus possibles grâce aux progrès du matériel. Nos smartphones et appareils portables offrent désormais plus de puissance de calcul qu'un serveur il y a 30 ans. Certains ont même des coprocesseurs spécialisés pour l'inférence ML. dans nos poches et sur nos poignets.
Les microcontrôleurs sont bon marché, avec des prix de vente moyens atteignant moins de 0,50 $, et ils sont partout, intégrés dans les appareils grand public et industriels. En même temps, ils ne disposent pas des ressources trouvées dans les appareils informatiques génériques. La plupart d'entre eux n'ont pas de système d'exploitation. Ils ont un petit processeur, sont limités à quelques centaines de kilo-octets de mémoire basse consommation (SRAM) et à quelques mégaoctets de stockage, et ne disposent d'aucun équipement réseau. Ils n'ont généralement pas de source d'électricité secteur et doivent fonctionner avec des piles et des piles pendant des années. Par conséquent, l'installation de modèles d'apprentissage en profondeur sur les microcontrôleurs peut ouvrir la voie à de nombreuses applications.
Goulets d'étranglement de la mémoire dans les réseaux de neurones convolutifs
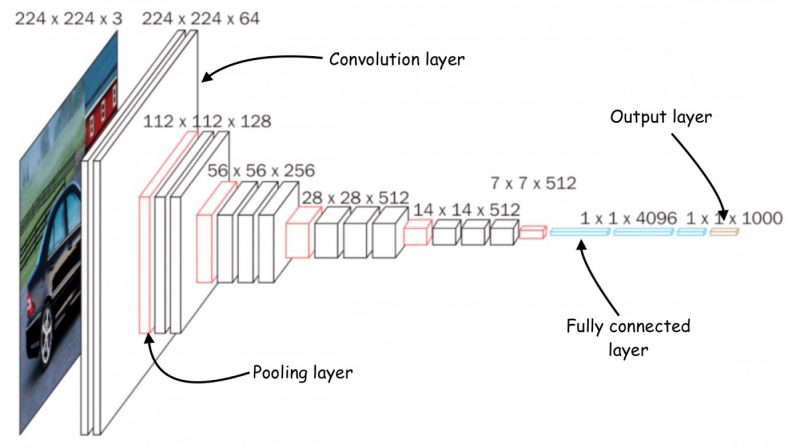

De nombreux efforts ont été déployés pour réduire les réseaux neuronaux profonds à une taille adaptée aux dispositifs informatiques à petite mémoire. Cependant, la plupart de ces efforts se concentrent sur la réduction du nombre de paramètres dans le modèle d'apprentissage en profondeur. Par exemple, "pruning", une classe populaire d'algorithmes d'optimisation, comprime les réseaux de neurones en supprimant les paramètres qui ne sont pas significatifs dans la sortie du modèle.
Le problème avec les méthodes d'élagage est qu'elles ne résoudre le goulot d'étranglement de la mémoire des réseaux de neurones. Les implémentations standard des bibliothèques d'apprentissage en profondeur nécessitent le chargement en mémoire d'une couche réseau complète et de cartes d'activation. Malheureusement, les méthodes d'optimisation classiques n'apportent pas de changements significatifs aux premières couches du réseau, en particulier dans les réseaux de neurones convolutifs. ” problème : Même si le réseau devient plus léger après l'élagage, le périphérique qui l'exécute doit avoir autant de mémoire que la plus grande couche. Par exemple, dans MobileNetV2, un modèle TinyML populaire, les premiers blocs de couche ont un pic de mémoire qui atteint environ 1,4 mégaoctets, tandis que les couches ultérieures ont une très petite empreinte mémoire. Pour exécuter le modèle, un appareil aura besoin d'autant de mémoire que le pic du modèle. La plupart des microcontrôleurs n'ayant pas plus de quelques centaines de kilo-octets de mémoire, ils ne peuvent pas exécuter la version standard de MobileNetV2.
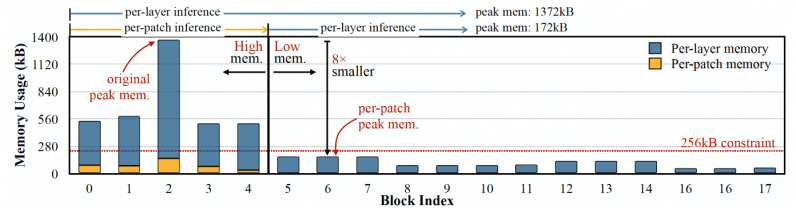

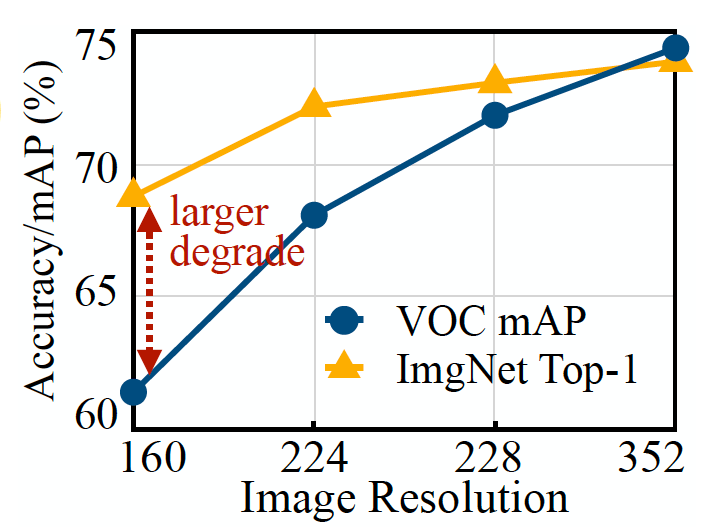


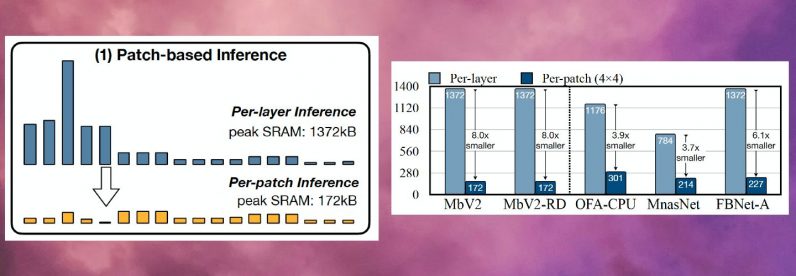

Les avantages d'économie de mémoire de l'inférence basée sur les correctifs s'accompagnent d'un compromis sur les frais généraux de calcul. Les chercheurs du MIT et d'IBM ont découvert que le calcul global du réseau pouvait augmenter de 10 à 17 % dans différentes architectures, ce qui n'est pas adapté aux microcontrôleurs de faible puissance.
Pour surmonter cette limite, les chercheurs ont redistribué le "champ récepteur" de les différents blocs du réseau. Dans les CNN, le champ récepteur est la zone de l'image qui est traitée à tout moment. Des champs récepteurs plus grands nécessitent des patchs plus grands et des chevauchements entre les patchs, ce qui crée une surcharge de calcul plus élevée. En réduisant les champs récepteurs des blocs initiaux du réseau et en élargissant les champs récepteurs des étapes ultérieures, les chercheurs ont pu réduire la surcharge de calcul de plus des deux tiers.
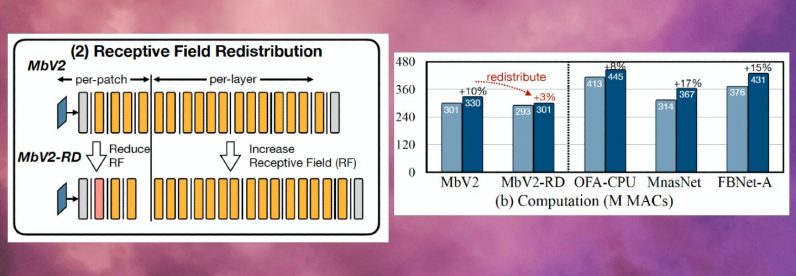

Enfin, les chercheurs ont observé que les ajustements de MCUNetV2 dépendent largement de l'architecture du modèle ML, de l'application et de la capacité de mémoire et de stockage de l'appareil cible. Pour éviter de régler manuellement le modèle d'apprentissage en profondeur pour chaque appareil et application, les chercheurs ont utilisé la "recherche algorithmique neuronale", un processus qui utilise l'apprentissage automatique pour optimiser automatiquement l'architecture du réseau neuronal et la planification des inférences.
Les chercheurs ont testé le architecture d'apprentissage profond dans différentes applications sur plusieurs modèles de microcontrôleurs à faible capacité mémoire. Les résultats montrent que MCUNetV2 surpasse les autres techniques TinyML, atteignant une plus grande précision dans la classification des images et la détection d'objets avec des besoins en mémoire plus faibles et des latences plus faibles. détection de masque.
<iframe srcdoc="

 " height="240" width="320" allow="accéléromètre ; lecture automatique ; écriture dans le presse-papiers ; média chiffré ; gyroscope ; image dans l'image" allowfullscreen="" frameborder="0">
" height="240" width="320" allow="accéléromètre ; lecture automatique ; écriture dans le presse-papiers ; média chiffré ; gyroscope ; image dans l'image" allowfullscreen="" frameborder="0">
Applications de TinyML
Dans un essai de 2018 intitulé "Why the Future of Machine Learning is Tiny", l'ingénieur logiciel Pete Warden a soutenu que l'apprentissage automatique sur les MCU est extrêmement important . "Je suis convaincu que l'apprentissage automatique peut fonctionner sur de minuscules puces à faible consommation d'énergie, et que cette combinaison résoudra un grand nombre de problèmes pour lesquels nous n'avons pas de solution pour le moment", a écrit Warden.
Notre capacité à capturer des données à partir de le monde a énormément augmenté grâce aux progrès des capteurs et des processeurs. Mais notre capacité à traiter et à utiliser ces données via des modèles d'apprentissage automatique a été limitée par la connectivité réseau et l'accès aux serveurs cloud. Comme l'a fait valoir Warden, les processeurs et les capteurs sont beaucoup plus économes en énergie que les émetteurs radio tels que Bluetooth et Wi-Fi.
« La physique du déplacement des données semble nécessiter beaucoup d'énergie. Il semble y avoir une règle selon laquelle l'énergie nécessaire à une opération est proportionnelle à la distance à laquelle vous devez envoyer les bits. Les processeurs et les capteurs envoient des bits de quelques millimètres et sont bon marché, la radio leur envoie des mètres ou plus et coûte cher », a écrit Warden. "[It’s] Il est évident qu'il existe un énorme marché inexploité qui attend d'être débloqué avec la bonne technologie. Nous avons besoin de quelque chose qui fonctionne sur des microcontrôleurs bon marché, qui utilise très peu d'énergie, qui repose sur le calcul et non sur la radio, et qui peut transformer toutes nos données de capteur gaspillées en quelque chose d'utile. C'est l'écart que l'apprentissage automatique, et plus particulièrement l'apprentissage en profondeur, comble. »
Grâce à MCUNetV2 et à d'autres avancées de TinyML, les prévisions de Warden se transforment rapidement en réalité. Dans les années à venir, nous pouvons nous attendre à ce que TinyML se retrouve dans des milliards de microcontrôleurs dans les maisons, les bureaux, les hôpitaux, les usines, les fermes, les routes, les ponts, etc. pour permettre des applications auparavant impossibles.
Cet article a été initialement publié. par Ben Dickson sur TechTalksune publication qui examine les tendances de la technologie, comment elles affectent notre façon de vivre et de faire des affaires, et les problèmes qu'elles résolvent. Mais nous discutons également du côté pervers de la technologie, des implications les plus sombres des nouvelles technologies et de ce que nous devons surveiller. Vous pouvez lire l'article original ici.
Source link