


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Texte en parole avec AWS
Cette série en deux parties présente trois projets qui vous expliquent comment utiliser AWS (Amazon Web Services) pour transformer du texte entre ses états écrit et parlé. Le premier projet utilisera la synthèse vocale pour transformer un article de blog ou tout autre contenu écrit en un fichier .mp3 parlé pour offrir davantage d'options aux utilisateurs aveugles et dyslexiques de votre site.
Dans le prochain article, nous allons commencer le retour. voyage, de parole en texte, et considérez l'exactitude de ces transcriptions en envoyant divers échantillons au moyen d'une traduction aller-retour. Pour suivre ces didacticiels, vous aurez besoin d’un compte AWS avec la facturation activée, bien que les didacticiels restent dans les limites des contraintes des ressources de niveau libre. Les exemples porteront sur l'utilisation de la console AWS, mais je vais également illustrer l'interface AWS CLI (interface de ligne de commande), qui nécessite des connaissances de base en ligne de commande.
Introduction et motivation
La plupart de l'internet est basé sur du texte. Le texte est léger (1 octet par lettre), largement pris en charge, facile à interpréter et possède un précédent aussi ancien que l’Internet comme moyen de communication en ligne par défaut. L'envoi de texte écrit est antérieur à Internet: les télégraphes transportaient le texte par fil il y a des centaines d'années et le courrier physique transmettait l'écriture depuis des siècles. La transmission vocale à la radio et au téléphone est également antérieure à Internet, mais elle n’a pas été traduite sur le même support de base que le texte en ligne. C'est dans presque tous les cas une bonne chose, encore une fois, le texte est léger et facile à interpréter par rapport à l'audio. Cependant, la transformation entre voix et texte peut ajouter des fonctionnalités puissantes et améliorer l'accessibilité d'une grande variété d'applications.
Il a toujours été possible de transformer un fichier audio en un texte, vous pouvez lire un discours écrit ou transcrire un sermon oral. En effet, si nous repensons au télégramme, des opérateurs qualifiés trans-codent les messages en code Morse en mots. Dans chaque exemple, passer de la parole à l’écriture ou à l’arrière, même avec une formation et du matériel spécialisés, a toujours demandé beaucoup de travail. Avec une variété de services cloud, nous pouvons automatiser ces processus pour permettre la transition entre les supports en quelques secondes sans aucun effort humain, ce qui élargit les cas d'utilisation possibles.
L'avantage le plus évident de la mise en œuvre d'options appropriées de synthèse vocale et de parole à texte est accessibilité. Un utilisateur malvoyant ou dyslexique bénéficierait d'une version narrée d'un article, tandis qu'une personne sourde pourrait devenir membre de votre auditoire de podcasting en lisant une transcription de l'émission.
Projet Text to Speech
Dites que vous voulez Ajoutez des versions commentées de chaque article sur votre blog. Vous pouvez acheter un microphone et investir des heures dans l'enregistrement et l'édition de rendus parlés de chaque message. Cela donnerait une expérience d'auditeur supérieure, mais si vous souhaitez profiter de la majeure partie des avantages pour seulement quelques minutes et quelques centimes par publication, envisagez d'utiliser AWS à la place. Si vous êtes le genre de personne qui met à jour et modifie régulièrement du contenu plus ancien ou à feuilles persistantes, cette méthode vous permet également de maintenir la version parlée à jour avec un minimum d'effort.
Nous allons commencer par synthétiser du texte en utilisant Amazon Polly [. Pour une exploration simple, AWS fournit une interface utilisateur graphique via sa console en ligne. Une fois connecté à votre compte AWS, utilisez le menu «Services» pour rechercher «Amazon Polly» ou accédez à https://us-east-1.console.aws.amazon.com/polly/home/SynthesizeSpeech .
Utilisation de la console Polly

Vous pouvez utiliser la console Amazon Polly pour lire 3 000 caractères (environ 500 mots) et obtenir un flux audio ou un téléchargement immédiat. Si vous avez besoin de lire jusqu'à 100 000 caractères (environ 16 600 mots), votre seule option consiste à laisser AWS stocker le résultat dans S3 une fois le traitement terminé, ce qui peut prendre quelques minutes. Au moment de la rédaction de ce document, Amazon Polly ne prend pas en charge les entrées de plus de 100 000 caractères facturables. Si vous souhaitez convertir un texte plus long, comme un livre, vous devrez probablement le faire en morceaux et concaténer vous-même les fichiers audio.
A "Caractère facturable" est celui qui est réellement prononcé par le service. Concrètement, cela signifie que les balises SSML ne sont pas des caractères facturables, ce que nous verrons plus tard. Pour votre première année d'utilisation d'Amazon Polly, vous recevez gratuitement 5 millions de caractères facturables par mois, ce qui est amplement suffisant pour exécuter les exemples de cet article et effectuer vos propres expérimentations. Au-delà, Amazon Polly coûte quatre dollars par million de caractères facturables au moment de la rédaction, ce qui signifie que la conversion d'un roman de longueur standard coûterait environ deux dollars.
La console vous permet également de changer la langue, la région et la voix de. le lecteur. Bien que cet article ne couvre que l'anglais, AWS prend actuellement en charge 21 langues et 29 paires langues / régions distinctes. Bien que la plupart des régions ne disposent que d'une ou deux voix, des options répandues, comme l'anglais américain, disposent de plusieurs options.
I préfèrent souvent utiliser la voix anglaise britannique «Brian». Pour mes oreilles américaines, l'accent britannique couvre certaines inflexions du discours robotique et permet une expérience d'écoute plus douce. Pour être clair, le texte narré par Amazon Polly est très évidemment lu par un robot, mais l'audio ainsi obtenu est très à l'écoute.
Il est nettement meilleur que le lecteur intégré utilisé par la commande de terminal MacOS . , et est comparable à la qualité de la parole d’assistants vocaux tels que Siri et Alexa.
Rédaction SSML
Si vous souhaitez un contrôle total sur la parole résultante, vous pouvez prendre le temps de marquer votre entrée avec SSML. SSML (langage de synthèse de synthèse vocale) est un langage normalisé permettant de représenter des signaux verbaux dans un texte. Comme HTML, XML et d'autres langages de balisage, il utilise des balises d'ouverture et de fermeture. Amazon Polly prend en charge la saisie SSML, et les balises ne comptent pas comme des «caractères facturables». Les compétences Alexa utilisent également SSML pour les réponses préprogrammées, il est donc utile de connaître cette langue.
La balise fondamentale,
pour diviser les paragraphes, ce qui entraîne une pause significative dans la narration. Les petites pauses proviennent de la ponctuation et vous avez toujours la possibilité d'insérer des pauses de dix secondes maximum avec
SSML fournit interpréter comme argument . Examinez les options de cette balise avec l'exemple suivant.
Appelez le 5551230987 avant 11'00 "pour obtenir des conseils sur l'écriture de code JavaScript propre. 5551230987 avant 23h00 pour obtenir des conseils sur l'écriture propre . JavaScript
La balise
Le tag Guten, où se trouve l'aéroport? Le tag Guten où se trouve l'aéroport>
Enfin, si vous souhaitez personnaliser la prononciation dans une langue, Amazon Polly prend en charge la balise
Philip Kiely Kiely
Il ne s'agit pas d'une liste exhaustive des options de personnalisation disponibles avec SSML. Pour une référence complète, consultez la documentation .
Écrire des lexiques
Si vous voulez spécifier une prononciation personnalisée cohérente ou développer une abréviation sans étiqueter chaque instance avec une balise phonème, ou si vous utilisez texte au lieu de SSML, Amazon Polly prend en charge les lexiques des prononciations personnalisées. Vous pouvez appliquer jusqu'à cinq lexiques de 4 000 caractères chacun par langue à une narration, bien que les lexiques plus grands augmentent le temps de traitement.
Comme auparavant, je veux m'assurer que Amazon Polly prononce mon nom correctement, mais cette fois. Je veux le faire sans utiliser SSML. J'ai écrit le lexique suivant:
Kiely kaIli L'en-tête et la balise alphabet vous permet de choisir entre x-sampa et ipa, deux alphabets à prononciation standard. Je préfère x-sampa car il utilise des caractères ASCII standard. Il est donc peu probable que je rencontre des problèmes d'encodage. L'argument xml: lang vous permet de spécifier la langue et la région. Un lexique n'est utilisable que par une voix de cette langue et de cette région
Le lexique lui-même est une séquence de balises

La capture d'écran montre le texte brut qui serait mal prononcé et le lexique appliqué. Utilisez le menu «Personnaliser la prononciation» pour sélectionner jusqu'à cinq lexiques téléchargés, téléchargés à partir de l'onglet de la barre de navigation gauche «Lexicons». L'écoute du discours vérifie que mon nom est correctement prononcé.
Maintenant que nous avons le contrôle total sur le discours résultant Voyons comment enregistrer la sortie pour l’utiliser dans notre application.
Enregistrement et chargement à partir de S3
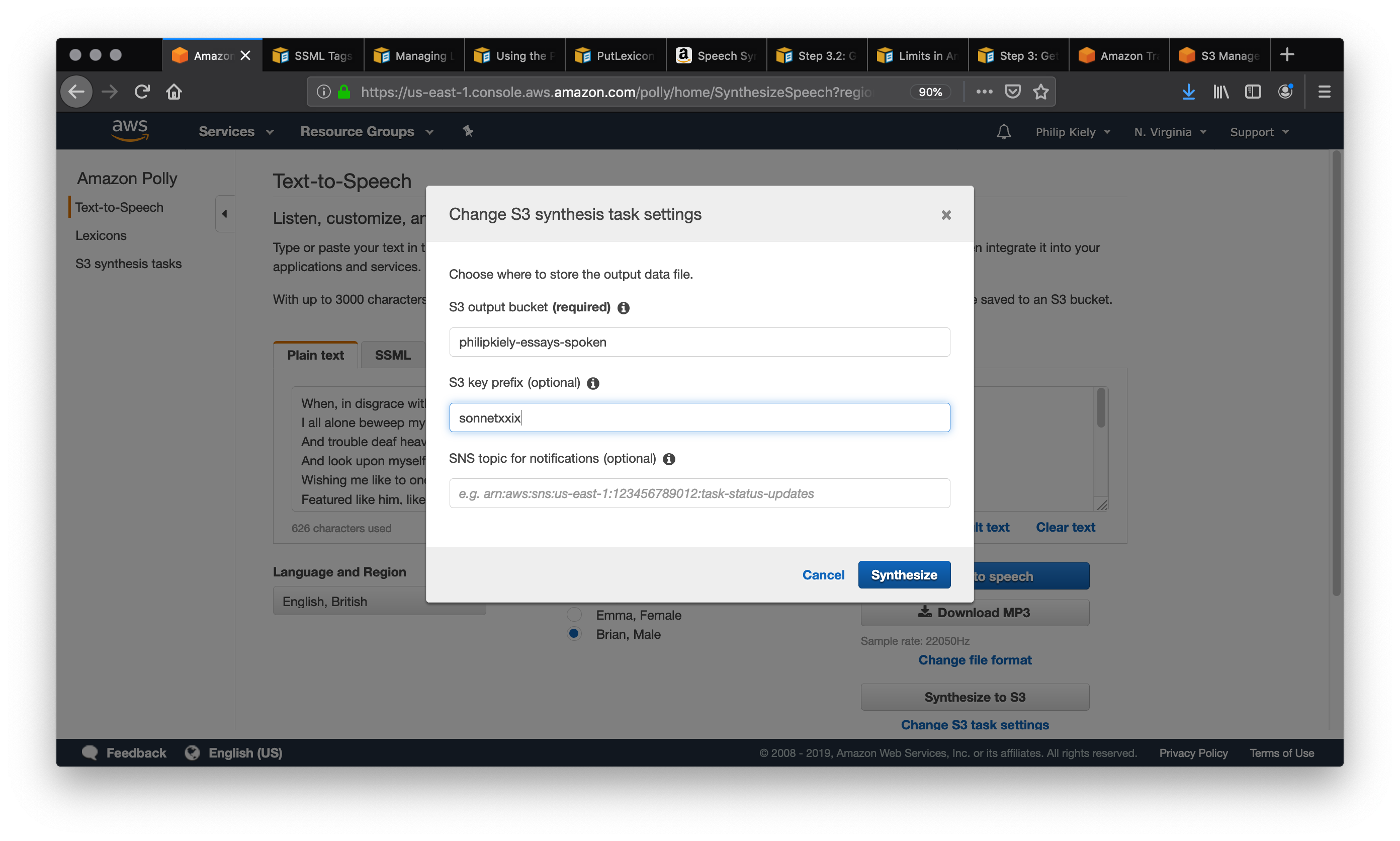
Si vous souhaitez réutiliser du texte parlé dans votre application, vous devez choisir «Synthétiser vers S3». option dans la console Amazon Polly. Dans cet exemple, j’utilise la voix «Brian» pour effectuer une lecture étonnamment capable du sonnet XXIX de Shakespeare . Nous commençons par copier le poème en texte brut et en sélectionnant «Synthétiser en S3», ce qui lance le modal suivant:

Les compartiments S3 ont des noms uniques au monde, et vous pouvez entrer n’importe quel compartiment S3 que vous possédez ou avec les autorisations appropriées. Assurez-vous que le compartiment permet de rendre son contenu public, comme cela sera nécessaire dans une étape ultérieure. Vous devez également définir un «préfixe de clé S3», qui est une chaîne qui vous aidera à identifier la sortie dans le compartiment. Après avoir cliqué sur Synthétiser et lui avoir donné le temps de traiter, nous accédons au compartiment S3 dans lequel nous avons synthétisé le discours.

La flèche pointe vers l'entrée du compartiment que nous venons de créer. La sélection de cet élément nous amène à la page suivante:

Suivez la flèche pour sélectionner l'option “Rendre public”, ce qui rendra le fichier accessible à toute personne disposant d'un lien. Faites défiler et copiez le lien et utilisez-le dans votre application. Par exemple, vous pouvez télécharger le poème ici . Pour de nombreuses applications, vous pouvez passer l'URL à une balise html pour permettre la lecture sur le Web.
Nous avons présenté tous les composants nécessaires à la transformation de texte en parole sur AWS. Nous nous tournons ensuite vers une interface plus avancée capable de fournir un potentiel d’automatisation et d’économiser du temps.
Utilisation de l’AWS CLI
Retour à notre article de blog hypothétique. Le flux de travail le plus simple consiste à extraire la version écrite finale de chaque article, à la copier dans la console, à cliquer sur le bouton «Synthétiser en S3» et à intégrer un lien de téléchargement au fichier .mp3 résultant dans le blog. Honnêtement, il s’agit d’un flux de travail plutôt décent; c'est exactement ce que je fais pour mon site web personnel. Cependant, AWS offre une autre option: l'AWS CLI.
Assurez-vous que vous avez installé et correctement configuré l'AWS CLI. Commencez par entrer aws polly help pour vous assurer que Polly est disponible et pour lire une liste des commandes prises en charge. Pour le dépannage, voir la documentation .
Pour effectuer une conversion à partir de la ligne de commande, j'ai d'abord copié le poème de l'ancien dans un fichier .txt. J'ai alors exécuté la commande suivante dans le terminal (MacOS / Linux):
aws polly synthesize-speech
--output-format mp3
--void-id Joanna
--text "` cat sonnetxxix.txt` "
poème.mp3
En quelques secondes, le fichier .mp3 résultant a été téléchargé sur ma machine, prêt à être inclus dans mon CMS ou une autre application. Notez les caractères spéciaux autour de l'argument - text cela transmet le contenu du fichier plutôt que le nom du fichier.
Enfin, pour les applications plus avancées, Amazon Polly a un SDK pour 9 langues / plates-formes . Le SDK serait excessif pour ces exemples, mais c'est exactement ce que vous voulez pour automatiser les appels Amazon Polly, en particulier en réponse aux actions des utilisateurs.
Conclusion
La synthèse vocale peut vous aider à créer un contenu plus polyvalent et accessible. À partir de la console Amazon Polly, nous pouvons transformer jusqu'à 100 000 caractères facturables en texte brut ou SSML, rendre public le fichier .mp3 résultant et utiliser ce fichier dans une application. Nous pouvons utiliser l'AWS CLI pour l'automatisation et un accès plus pratique.
Restez à l'écoute pour le deuxième volet de la série. Nous allons convertir les supports dans l'autre sens, du discours au texte, et examiner les avantages et les inconvénients de le faire. La deuxième partie s'appuiera sur les technologies que nous avons utilisées jusqu'à présent et présentera Amazon Transcribe.
Référence supplémentaire
 (yk, ra)
(yk, ra)
Source link