


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Outils de données quantitatives pour les concepteurs UX
De nombreux concepteurs UX ont quelque peu peur des données, le croyant nécessite une connaissance approfondie des statistiques et des mathématiques. Bien que cela puisse être vrai pour la science des données avancée, ce n'est pas le cas pour l'analyse des données de recherche fondamentale requise par la plupart des concepteurs UX. Comme nous vivons dans un monde de plus en plus axé sur les données, la littératie de base des données est utile pour presque tous les professionnels – pas seulement les concepteurs UX.
Aaron Gitlin, concepteur d'interaction chez Google, fait valoir que de nombreux concepteurs ne sont pas encore data-driven:
«Alors que de nombreuses entreprises se présentent comme étant axées sur les données, la plupart des concepteurs sont mus par l'instinct, la collaboration et les méthodes de recherche qualitative.»
– Aaron Gitlin, « Devenir un data-aware Designer »
Avec cet article, je voudrais donner aux concepteurs UX les connaissances et les outils pour incorporer des données dans leurs routines quotidiennes.
Mais d'abord, quelques concepts de données
Dans cet article, je parlerai sur les données structurées, c'est-à-dire les données qui peuvent être représentées dans un tableau, avec des lignes et des colonnes. Les données non structurées, étant un sujet en soi, sont plus difficiles à analyser, comme l'a souligné Devin Pickell (spécialiste du marketing de contenu chez G2 Crowd, écrivant sur les données et l'analyse) « Structured vs Unstructured Data – Quelle est la différence? . »Si les données structurées peuvent être représentées sous forme de tableau, les principaux concepts sont:
Dataset
L'ensemble complet de données que nous avons l'intention d'analyser. Cela pourrait être, par exemple, un tableau Excel. Un autre format populaire pour stocker des ensembles de données est le fichier de valeurs séparées par des virgules (CSV). Les fichiers CSV sont de simples fichiers texte utilisés pour stocker des informations de type tableau. Chaque ligne CSV correspond à une ligne du tableau et chaque ligne CSV a des valeurs séparées (naturellement) par des virgules, qui correspondent aux cellules du tableau.
Point de données
Une seule ligne d'une table de jeu de données est un point de données. De cette façon, un ensemble de données est une collection de points de données.
Variable de données
Une seule valeur d'une ligne de points de données représente une variable de données – en termes simples, une cellule de tableau. Nous pouvons avoir deux types de variables de données: les variables qualitatives et les variables quantitatives. Les variables qualitatives (également appelées variables catégorielles) ont un ensemble discret de valeurs, comme color = rouge / vert / bleu . Les variables quantitatives ont des valeurs numériques, telles que hauteur = 167 . Une variable quantitative, contrairement à une variable qualitative, peut prendre n'importe quelle valeur.
Création de notre projet de données
Maintenant que nous connaissons les bases, il est temps de se salir les mains et de créer notre premier projet de données. La portée du projet est d'analyser un ensemble de données en parcourant l'intégralité du flux de données d'importation, de traitement et de traçage des données. Tout d'abord, nous choisirons notre jeu de données, puis nous téléchargerons et installerons les outils d'analyse des données.
Jeu de données Cars
Aux fins de cet article, j'ai choisi un jeu de données voitures, car il est simple et intuitif. L'analyse des données confirmera simplement ce que nous savons déjà sur les voitures – ce qui est bien, car nous nous concentrons sur le flux de données et les outils.
Nous pouvons télécharger un ensemble de données sur les voitures d'occasion à partir de Kaggle l'un des les plus grandes sources de jeux de données gratuits. Vous devez d'abord vous enregistrer.
Après avoir téléchargé le fichier, ouvrez-le et jetez un œil. C'est un très gros fichier CSV, mais vous devriez comprendre l'essentiel. Une ligne dans ce fichier ressemblera à ceci:
19500,2015,2965, Miami, FL, WBA3B1G54FNT02351, BMW, 3
Comme vous pouvez le voir, ce point de données a plusieurs variables séparées par des virgules. Puisque nous avons maintenant le jeu de données, parlons un peu des outils.
Tools of the Trade
Nous utiliserons le langage R et RStudio pour analyser le jeu de données. R est une langue très populaire et facile à apprendre, utilisée non seulement par les scientifiques des données, mais aussi par les gens des marchés financiers, de la médecine et de nombreux autres domaines. RStudio est l'environnement dans lequel les projets R sont développés, et il existe une version gratuite, qui est plus que suffisante pour nos besoins en tant que concepteurs UX.
Il est probable que certains concepteurs UX utilisent Excel pour leur flux de données. Si cela signifie que vous, essayez R – il y a de fortes chances que vous l'aimiez, car il est facile à apprendre, et plus flexible et puissant qu'Excel. L'ajout de R à votre trousse d'outils fera une différence.
Installation des outils
Tout d'abord, nous devons télécharger et installer R et RStudio . Vous devez d'abord installer R, puis RStudio. Les processus d’installation de R et RStudio sont simples et directs.
Configuration du projet
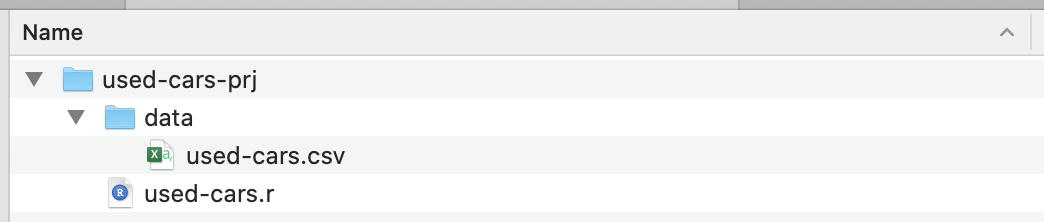
Une fois l’installation terminée, créez un dossier de projet – je l’ai appelé used-cars-prj . Dans ce dossier, créez un sous-dossier appelé data puis copiez le fichier de l'ensemble de données (téléchargé depuis Kaggle ) dans ce dossier et renommez-le en used-cars.csv . Revenez maintenant à notre dossier de projet ( used-cars-prj ) et créez un fichier texte brut appelé used-cars.r . Vous devriez vous retrouver avec la même structure que dans la capture d'écran ci-dessous.

Nous avons maintenant la structure du dossier en place, nous pouvons ouvrez RStudio et créez un nouveau projet R. Choisissez Nouveau projet… dans le menu Fichier et sélectionnez la deuxième option, Répertoire existant . Sélectionnez ensuite le répertoire du projet ( used-cars-prj ). Enfin, appuyez sur le bouton Créer un projet et vous avez terminé. Une fois le projet créé, ouvrez used-cars.r dans RStudio – c'est le fichier où nous ajouterons tout notre code R.
Importation de données
Nous ajouterons notre première ligne dans used-cars.r pour lire les données du fichier used-cars.csv . N'oubliez pas que les fichiers CSV ne sont que des fichiers de texte brut utilisés pour stocker des données. Notre première ligne de code R ressemblera à ceci:
Cela peut sembler un peu intimidant, mais ce n'est vraiment pas le cas – en passant, c'est la ligne la plus complexe de tout l'article. Ce que nous avons ici est la fonction read.csv qui prend trois paramètres.
Le premier paramètre est le fichier à lire, dans notre cas used-cars.csv qui se trouve dans le dossier data . Le deuxième paramètre, stringsAsFactors = FALSE est réglé pour s'assurer que les chaînes comme «BMW» ou «Audi» ne sont pas converties en facteurs (le jargon R pour les données catégorielles) – comme vous vous en souvenez, variables qualitatives ou catégorielles ne peut avoir que des valeurs discrètes comme rouge / vert / bleu . Enfin, le troisième paramètre, sep = "," spécifie le type de séparateur utilisé pour séparer les valeurs du fichier CSV: une virgule.
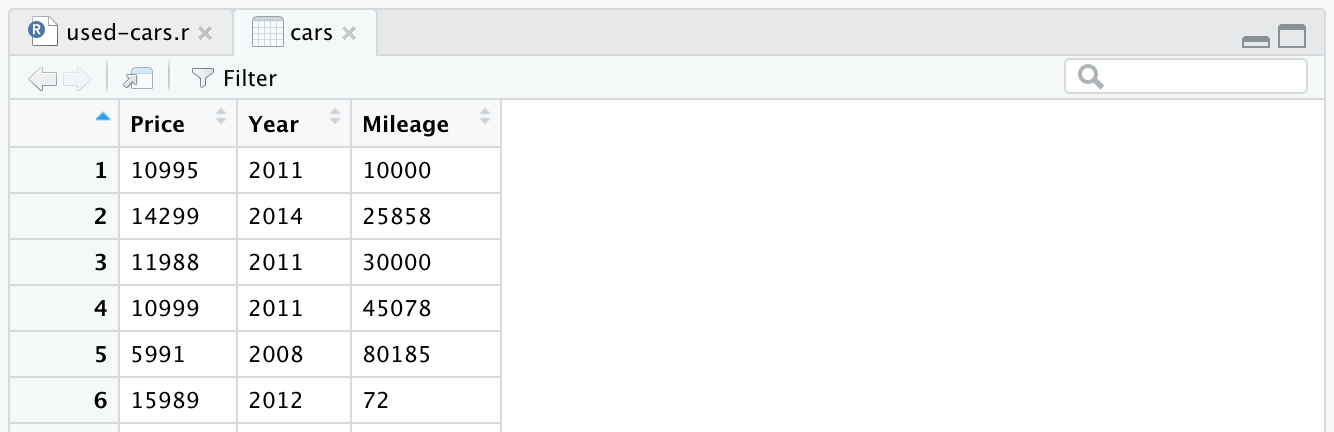
Après avoir lu le fichier CSV, les données sont stockées dans le voitures objet de trame de données. Une trame de données est une structure de données bidimensionnelle (comme un tableau Excel), qui est très utile dans R pour manipuler des données. Après avoir introduit la ligne et l'avoir exécutée, un cadre de données voitures sera créé pour vous. Si vous regardez dans le quadrant supérieur droit de RStudio, vous remarquerez le bloc de données voitures dans la section Données sous l'onglet Environnement . Si vous double-cliquez sur voitures un nouvel onglet s'ouvrira dans le quadrant supérieur gauche de RStudio et présentera le bloc de données voitures . Comme vous pouvez vous y attendre, il ressemble à un tableau Excel.

Il s'agit en fait des données brutes que nous avons téléchargées de Kaggle. Mais comme nous voulons effectuer une analyse des données, nous devons d'abord traiter notre ensemble de données.
Traitement des données
Par traitement, nous entendons supprimer, transformer ou ajouter des informations à notre ensemble de données, afin de préparer le type d'analyse que nous veulent effectuer. Nous avons les données dans un objet de trame de données, nous devons donc maintenant installer la bibliothèque dplyr une bibliothèque puissante pour manipuler des données. Pour installer la bibliothèque dans notre environnement R, nous devons écrire la ligne suivante en haut de notre fichier R.
install.packages ("dplyr")
Ensuite, pour ajouter la bibliothèque à notre projet actuel, nous utiliserons la ligne suivante:
library (dplyr)
Une fois la bibliothèque dplyr ajoutée à notre projet, nous pouvons commencer le traitement des données. Nous avons un ensemble de données vraiment volumineux, et nous n'avons besoin que des données représentant le même constructeur automobile et le même modèle, afin de corréler cela avec le prix. Nous utiliserons le code R suivant pour ne conserver que les données concernant la BMW Série 3 et supprimer le reste. Bien sûr, vous pouvez choisir n'importe quel autre fabricant et modèle de l'ensemble de données et vous attendre à avoir les mêmes caractéristiques de données.
filtre% voitures (Marque == "BMW", Modèle == "3")
Nous avons maintenant un ensemble de données plus facile à gérer, mais contenant toujours plus de 11 000 points de données, qui correspond à notre objectif: analyser les distributions des prix, de l'âge et du kilométrage des voitures, ainsi que les corrélations entre elles. Pour cela, nous devons conserver uniquement les colonnes "Prix", "Année" et "Kilométrage" et supprimer le reste – cela se fait avec la ligne suivante.
voitures% select (Prix, Année, Kilométrage)
Après avoir supprimé les autres colonnes, notre bloc de données ressemblera à ceci:

Il y a encore un changement nous voulons apporter à notre jeu de données: remplacer l'année de fabrication par l'âge de la voiture. Nous pouvons ajouter les deux lignes suivantes, la première pour calculer l'âge, la seconde pour changer le nom de la colonne.
cars% mutate (Year = max (Year) - Year)
voitures% renommer (âge = année)
Enfin, notre bloc de données entièrement traité ressemble à ceci:

À ce stade, notre code R ressemblera comme ce qui suit, et c'est tout pour le traitement des données. Nous pouvons maintenant voir à quel point le langage R est simple et puissant. Nous avons traité le jeu de données initial de façon assez spectaculaire avec seulement quelques lignes de code.
install.packages ("dplyr")
bibliothèque (dplyr)
cars = read.csv ("./ data / cars.csv", stringsAsFactors = FALSE, sep = ",")
filtre% voitures (Marque == "BMW", Modèle == "3")
% voitures sélectionnées (Prix, Année, Kilométrage)
voitures% mutent (Année = max (Année) - Année)
voitures% renommer (âge = année)
Analyse des données
Nos données sont maintenant dans la bonne forme, nous pouvons donc aller faire quelques tracés. Comme déjà mentionné, nous nous concentrerons sur deux aspects: la distribution des variables individuelles et les corrélations entre elles. La distribution variable nous aide à comprendre ce qui est considéré comme un prix moyen ou élevé pour une voiture d'occasion – ou le pourcentage de voitures au-dessus d'un prix spécifique. Il en va de même pour l'âge et le kilométrage des voitures. Les corrélations, d'autre part, sont utiles pour comprendre comment les variables comme l'âge et le kilométrage sont liées les unes aux autres.
Cela dit, nous utiliserons deux types de visualisation des données: les histogrammes pour la distribution des variables et les nuages de points pour les corrélations. [19659064] Distribution des prix
Le tracé de l'histogramme des prix des voitures en langage R est aussi simple que cela:
hist (voitures $ Prix)
Un petit conseil: si vous êtes dans RStudio, vous pouvez exécuter le code ligne par ligne; par exemple, dans notre cas, vous devez exécuter uniquement la ligne ci-dessus pour afficher l'histogramme. Il n'est pas nécessaire d'exécuter à nouveau tout le code puisque vous l'avez déjà exécuté une fois. L'histogramme devrait ressembler à ceci:

Si nous regardons l'histogramme, nous remarquons une distribution en forme de cloche de la les prix des voitures, ce que nous attendions. La plupart des voitures se situent dans le milieu de gamme, et nous en avons de moins en moins lorsque nous nous déplaçons de chaque côté. Près de 80% des voitures se situent entre 10 000 $ et 30 000 $ USD, et nous avons un maximum de plus de 2 500 voitures entre 20 000 $ et 25 000 $ USD. Sur le côté gauche, nous avons probablement environ 150 voitures de moins de 5 000 $ US, et sur le côté encore moins.
Distribution par âge
Tout comme pour les prix des voitures, nous utiliserons une ligne similaire pour tracer l'histogramme des âges des voitures.
hist (voitures $ Age)
Et voici l'histogramme:

Cette fois, l'histogramme semble contre-intuitif – au lieu d'une simple forme de cloche, nous avons ici quatre cloches. Fondamentalement, la distribution a trois maximums locaux et un maximum global, ce qui est inattendu. Il serait intéressant de voir si cette étrange répartition des âges des voitures reste vraie pour un autre constructeur et modèle automobile. Aux fins de cet article, nous resterons avec l'ensemble de données BMW Série 3, mais vous pouvez approfondir les données si vous êtes curieux. Concernant la répartition par âge de nos voitures, nous constatons que plus de 90% des voitures ont moins de 10 ans et plus de 80% moins de 7 ans. De plus, nous remarquons que la majorité des voitures ont moins de 5 ans.
Répartition du kilométrage
Maintenant, que pouvons-nous dire du kilométrage? Bien sûr, nous nous attendons à avoir la même forme de cloche que nous avions pour le prix. Voici le code R et l'histogramme:
hist (voitures $ Kilométrage)

Ici, nous avons une forme de cloche de gauche, ce qui signifie qu'il y a plus de voitures avec moins de kilométrage sur le marché. Nous notons également que la majorité des voitures ont moins de 60 000 miles, et nous avons un maximum autour de 20 000 à 40 000 miles.
Corrélation âge-prix
En ce qui concerne les corrélations, examinons de plus près le prix par âge des voitures. corrélation. Nous pourrions nous attendre à ce que le prix soit négativement corrélé avec l’âge – à mesure que l’âge d’une voiture augmente, son prix baissera. Nous utiliserons la fonction R plot pour afficher la corrélation prix-âge comme suit:
plot (cars $ Age, cars $ Price)
Et l'intrigue ressemble à ceci:

Nous remarquons comment les prix des voitures baissent avec l'âge: il y a des voitures neuves chères et des voitures anciennes moins chères. Nous pouvons également voir l'intervalle de variation des prix pour tout âge spécifique, une variation qui diminue avec l'âge d'une voiture. Cette variation est largement due au kilométrage, à la configuration et à l'état général de la voiture. Par exemple, dans le cas d'une voiture de 4 ans, le prix varie entre 10 000 USD et 40 000 USD.
Corrélation kilométrage-âge
Compte tenu de la corrélation kilométrage-âge, nous nous attendons à ce que le kilométrage augmente avec l'âge, ce qui signifie une corrélation positive. Voici le code:
plot (voitures $ Kilométrage, voitures $ Âge)
Et voici l'intrigue:

Comme vous pouvez le voir, l'âge et le kilométrage d'une voiture sont corrélés positivement, contrairement au prix et à l'âge d'une voiture, qui sont négativement corrélés. Nous avons également une variation de kilométrage attendue pour un âge spécifique; c'est-à-dire que les voitures du même âge ont des kilométrages variables. Par exemple, la plupart des voitures de 4 ans ont un kilométrage compris entre 10 000 et 80 000 miles. Mais il y a aussi des valeurs aberrantes, avec un kilométrage plus élevé.
Corrélation kilométrage-prix
Comme prévu, il y aura une corrélation négative entre le kilométrage des voitures et le prix, ce qui signifie que l'augmentation du kilométrage réduit le prix. [19659022] terrain (voitures $ kilométrage, voitures $ prix)
Et voici l'intrigue:

Comme nous nous y attendions, corrélation négative. Nous pouvons également remarquer l'intervalle de prix brut entre 3 000 $ et 50 000 $ USD, et le kilométrage entre 0 et 150 000 $. Si nous regardons de plus près la forme de distribution, nous voyons que le prix baisse beaucoup plus rapidement pour les voitures avec moins de kilométrage que pour les voitures avec plus de kilométrage. Il y a des voitures avec un kilométrage presque nul, où le prix baisse considérablement. De plus, au-delà de 200 000 miles, car le kilométrage est très élevé, le prix reste constant.
Des nombres aux visualisations de données
Dans cet article, nous avons utilisé deux types de visualisation: les histogrammes pour les distributions de données et les diagrammes de dispersion pour corrélations de données. Les histogrammes sont des représentations visuelles qui prennent les valeurs d'une variable de données (nombres réels ) et montrent comment elles sont réparties sur une plage. Nous avons utilisé la fonction R hist () pour tracer un histogramme.
Les diagrammes de dispersion, d'autre part, prennent des paires de nombres et les représentent sur deux axes. Les diagrammes de dispersion utilisent la fonction plot () et fournissent deux paramètres: les première et deuxième variables de données de la corrélation que nous voulons étudier. Ainsi, les deux fonctions R, hist () et plot () nous aident à traduire des ensembles de nombres en représentations visuelles significatives.
Conclusion
Avoir les mains sales à travers l'intégralité du flux de données d'importation, de traitement et de traçage des données, les choses semblent beaucoup plus claires maintenant. Vous pouvez appliquer le même flux de données à tout nouvel ensemble de données brillant que vous rencontrerez. Dans la recherche utilisateur, par exemple, vous pouvez représenter graphiquement le temps sur la distribution des tâches ou des erreurs, et vous pouvez également tracer un temps sur la corrélation tâche / erreur.
Pour en savoir plus sur le langage R Quick-R est un bon point de départ, mais vous pouvez également envisager R Bloggers . Pour la documentation sur les packages R, comme dplyr vous pouvez visiter RDocumentation . Jouer avec les données peut être amusant, mais il est également extrêmement utile pour tout concepteur UX dans un monde axé sur les données. À mesure que davantage de données sont collectées et utilisées pour éclairer les décisions commerciales, les concepteurs ont de plus en plus de chances de travailler sur la visualisation de données ou des produits de données, où la compréhension de la nature des données est essentielle.
 og)
og) Source link