

{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Création d'un service Pub / Sub InHouse en utilisant Node.js et Redis
Le monde d'aujourd'hui fonctionne en temps réel. Qu'il s'agisse de négocier des actions ou de commander des aliments, les consommateurs s'attendent aujourd'hui à des résultats immédiats. De même, nous nous attendons tous à savoir les choses immédiatement – que ce soit dans les nouvelles ou les sports. Zero, en d'autres termes, est le nouveau héros.
Cela s'applique également aux développeurs de logiciels – sans doute certains des plus impatients! Avant de plonger dans l'histoire de BrowserStack, il serait négligent de ma part de ne pas fournir quelques informations sur Pub / Sub. Pour ceux d'entre vous qui sont familiers avec les bases, n'hésitez pas à sauter les deux paragraphes suivants.
De nombreuses applications reposent aujourd'hui sur le transfert de données en temps réel. Regardons de plus près un exemple: les réseaux sociaux. Les goûts de Facebook et Twitter génèrent des flux pertinents et vous (via leur application) le consommez et espionnez vos amis. Ils accomplissent cela avec une fonction de messagerie, dans laquelle si un utilisateur génère des données, il sera affiché pour les autres à consommer dans un rien de temps. Les retards importants et les utilisateurs se plaindront, l'utilisation diminuera et, si elle persiste, produira. Les enjeux sont élevés, tout comme les attentes des utilisateurs. Alors comment les services comme WhatsApp, Facebook, TD Ameritrade, Wall Street Journal et GrubHub supportent-ils des volumes élevés de transferts de données en temps réel?
Tous utilisent une architecture logicielle similaire à un niveau élevé appelée "Publier-S'abonner" , communément appelé Pub / Sub.
"Dans l'architecture logicielle publish-subscribe est un modèle de messagerie où les expéditeurs de messages appelés éditeurs, ne programmez pas les messages à envoyer directement à des récepteurs spécifiques, appelés abonnés, mais catégorisez plutôt les messages publiés en classes sans savoir quels abonnés, le cas échéant, peuvent être. De même, les abonnés expriment un intérêt pour une ou plusieurs classes et ne reçoivent que des messages qui les intéressent, sans savoir quels sont les éditeurs, le cas échéant. "
S'ennuyer par la définition? Retour à notre histoire.
Chez BrowserStack, tous nos produits supportent (d'une manière ou d'une autre) un logiciel avec une dépendance en temps réel substantielle – qu'il s'agisse d'automatiser les journaux de test, les captures d'écran du navigateur ou le streaming mobile 15fps. 19659007] Dans de tels cas, si un seul message tombe, un client peut perdre des informations vitales pour prévenir un bug . Par conséquent, nous devions effectuer une mise à l'échelle pour des exigences de taille de données variées. Par exemple, avec les services d'enregistreur de périphérique à un instant donné, il peut y avoir 50 Mo de données générées sous un même message. Des tailles comme celle-ci pourraient planter le navigateur. Sans parler du fait que le système de BrowserStack devra évoluer pour d'autres produits dans le futur.
Comme la taille des données pour chaque message diffère de quelques octets jusqu'à 100 Mo, nous avions besoin d'une solution évolutive pouvant supporter une multitude de scénarios . En d'autres termes, nous avons cherché une épée qui pourrait couper tous les gâteaux. Dans cet article, je vais discuter du pourquoi, du comment et des résultats de la construction interne de notre service Pub / Sub.
À travers l'objectif du problème réel de BrowserStack, vous obtiendrez une meilleure compréhension des exigences et le processus de construction de votre propre Pub / Sub .
Notre besoin d'un Pub / Service secondaire
BrowserStack a environ 100M + messages, dont chacun se situe entre environ 2 octets et 100+ MB. Ils sont transmis partout dans le monde, à des vitesses Internet différentes.
Les plus grands générateurs de ces messages, par taille de message, sont nos produits BrowserStack Automate. Les deux ont des tableaux de bord en temps réel affichant toutes les demandes et les réponses pour chaque commande d'un test utilisateur. Donc, si quelqu'un exécute un test avec 100 requêtes où la taille moyenne de la requête-réponse est de 10 octets, cela transmet 1 × 100 × 10 = 1000 octets.
Maintenant, considérons l'image plus grande – bien sûr – nous ne le faisons pas exécuter un seul test par jour. Plus de 850 000 BrowserStack Automate et App Automate sont exécutés avec BrowserStack chaque jour. Et oui, nous avons en moyenne 235 demandes-réponses par test. Puisque les utilisateurs peuvent prendre des captures d'écran ou demander des sources de pages dans Selenium, notre taille moyenne de demande-réponse est d'environ 220 octets.
Donc, revenons à notre calculatrice:
850,000 × 235 × 220 = 43,945,000,000 octets (approx.) ou seulement 43,945GB par jour
Parlons maintenant de BrowserStack Live et App Live . Nous avons sûrement Automate comme gagnant en termes de taille des données. Cependant, les produits Live prennent la tête en ce qui concerne le nombre de messages transmis. Pour chaque test en direct, environ 20 messages sont passés chaque minute. Nous effectuons environ 100 000 tests en direct, chaque test faisant en moyenne 12 minutes, ce qui signifie:
100 000 × 12 × 20 = 24 000 000 de messages par jour
Maintenant, nous construisons, gérons et maintenons l'application pour ce poussoir appelé avec 6 t1.micro instances de ec2. Le coût de fonctionnement du service? Environ $ 70 par mois .
Choisir de construire contre l'achat
Les choses d'abord: Comme une startup, comme la plupart des autres, nous étions toujours heureux de construire des choses en interne. Mais nous avons encore évalué quelques services là-bas. Les exigences principales que nous avions étaient:
- Fiabilité et stabilité,
- Haute performance, et
- Coût-efficacité.
Laissons les critères de rentabilité, car je ne peux pas penser à des services externes cela coûte moins de 70 $ par mois (tweet moi si vous en connaissez un qui fait!). Donc, notre réponse est évidente.
En termes de fiabilité et de stabilité, nous avons trouvé des entreprises qui fournissaient un service de Pub / Sub avec un SLA de disponibilité de 99,9% et plus, mais il y avait beaucoup de T & C. Le problème n'est pas aussi simple que vous le pensez, surtout lorsque vous considérez les vastes terres de l'Internet ouvert qui se trouvent entre le système et le client. Quiconque connaît l'infrastructure Internet sait que la connectivité est le plus grand défi. De plus, la quantité de données envoyée dépend du trafic. Par exemple, un canal de données à zéro pendant une minute peut éclater pendant le suivant. Les services assurant une fiabilité adéquate lors de tels moments d'explosion sont rares (Google et Amazon)
Les performances de notre projet signifient l'obtention et l'envoi de données à tous les nœuds d'écoute à latence quasi nulle . Chez BrowserStack, nous utilisons les services cloud (AWS) avec l'hébergement de co-location. Cependant, nos éditeurs et / ou abonnés peuvent être placés n'importe où. Par exemple, il peut s'agir d'un serveur d'applications AWS générant des données de journal indispensables ou des terminaux (machines sur lesquelles les utilisateurs peuvent se connecter en toute sécurité pour les tests). Pour en revenir au problème de l'Internet ouvert, si nous devions réduire notre risque, nous devrions nous assurer que notre Pub / Sub exploite les meilleurs services d'hôte et AWS.
Une autre exigence essentielle était la possibilité de transmettre tous types de données (Octets , texte, données médiatiques étranges, etc.). Compte tenu de tout cela, il n'était pas logique de s'appuyer sur une solution tierce pour soutenir nos produits. À notre tour, nous avons décidé de relancer notre esprit de démarrage, retroussant nos manches pour coder notre propre solution.
Construire notre solution
Pub / Sub signifie qu'il y aura un éditeur, générer et envoyer des données, et un abonné l'accepter et le traiter. Ceci est similaire à une radio: Une chaîne radio diffuse (publie) du contenu partout dans une plage. En tant qu'abonné, vous pouvez décider de syntoniser ce canal et d'écouter (ou d'éteindre complètement votre radio).
Contrairement à l'analogie radio où les données sont gratuites pour tous et où chacun peut décider de se connecter, dans notre scénario numérique, nous avons besoin d'une authentification qui signifie que les données générées par l'éditeur ne peuvent concerner qu'un seul client ou abonné. travail de Pub / Sub « />
Ci-dessus est un diagramme fournissant un exemple d'un bon Pub / Sub avec:
- Publishers
Ici, nous avons deux éditeurs générant des messages basés sur une logique prédéfinie. Dans notre analogie radio, ce sont nos jockeys radio qui créent le contenu. - Sujets
Il y en a deux ici, ce qui signifie qu'il y a deux types de données. Nous pouvons dire que ce sont nos canaux radio 1 et 2. - Abonnés
Nous en avons trois qui lisent chacun des données sur un sujet particulier. Une chose à noter est que l'abonné 2 lit plusieurs sujets. Dans notre analogie radio, ce sont les gens qui sont branchés sur une chaîne de radio.
Commençons à comprendre les exigences nécessaires pour le service
- Un composant événementiel
Ceci ne se déclenche que lorsqu'il y a quelque chose à lancer. - Stockage transitoire
Cela maintient les données ont persisté pendant une courte durée donc si l'abonné est lent, il a toujours une fenêtre pour le consommer. - Réduire la latence
Relier deux entités sur un réseau avec un minimum de sauts et de distance.
choisi une pile technologique qui remplissait les conditions ci-dessus:
- Node.js
Parce que pourquoi pas? Évidemment, nous n'aurions pas besoin d'un traitement de données lourd, et il est facile de l'embarquer. - Redis
Prend en charge des données parfaitement éphémères. Il a toutes les capacités pour lancer, mettre à jour et expirer automatiquement. Node.js Pour Business Logic ConnectivityNode.js est un langage presque parfait lorsqu'il s'agit d'écrire du code incorporant des E / S et des événements. Notre problème donné avait les deux, ce qui rend cette option la plus pratique pour nos besoins.
Il est certain que d'autres langages tels que Java pourraient être plus optimisés, ou un langage comme Python offre une évolutivité. Cependant, le coût de démarrage avec ces langages est si élevé qu'un développeur peut finir d'écrire du code dans Node dans la même durée.
Pour être honnête, si le service avait une chance d'ajouter des fonctionnalités plus compliquées, nous aurions pu regarder d'autres langages ou une pile terminée. Mais ici c'est un mariage fait au paradis. Voici notre package.json :
{ "nom": "Pousseur", "version": "1.0.0", "dépendances": { "bstack-analytics": "*****", // Caché pour des raisons BrowserStack. :) "ioredis": "^ 2.5.0", "socket.io": "^ 1.4.4" }, "devDependencies": {}, "scripts": { "start": "nœud server.js" } }Très simplement, nous croyons au minimalisme surtout quand il s'agit d'écrire du code. D'un autre côté, nous aurions pu utiliser des bibliothèques comme Express pour écrire du code extensible pour ce projet. Cependant, nos instincts de démarrage ont décidé de transmettre cela et de l'enregistrer pour le prochain projet. Outils supplémentaires que nous avons utilisés:
- ioredis
Ceci est l'une des bibliothèques les plus pris en charge pour la connectivité Redis avec Node.js utilisé par des sociétés dont Alibaba. - socket.io
La meilleure bibliothèque pour gracieuse connectivité et de secours avec WebSocket et HTTP.
Redis pour le stockage transitoire
Redis en tant que balances de service est fortement fiable et configurable. De plus, il existe de nombreux fournisseurs de services gérés fiables pour Redis, y compris AWS. Même si vous ne voulez pas utiliser un fournisseur, Redis est facile à utiliser.
Décompressons la partie configurable. Nous avons commencé avec la configuration maître-esclave habituelle, mais Redis est également livré avec des modes cluster ou sentinelle. Chaque mode a ses propres avantages.
Si nous pouvions partager les données d'une manière ou d'une autre, un cluster Redis serait le meilleur choix. Mais si nous avons partagé les données par n'importe quelle heuristique, nous avons moins de flexibilité car l'heuristique doit être suivie à travers . Moins de règles, plus de contrôle est bon pour la vie!
Redis Sentinel fonctionne mieux pour nous car la recherche de données est effectuée dans un seul nœud, se connectant à un moment donné alors que les données ne sont pas partagées. Cela signifie également que même si plusieurs nœuds sont perdus, les données sont toujours distribuées et présentes dans d'autres nœuds. Donc, vous avez plus de HA et moins de chances de perte. Bien sûr, cela a supprimé les avantages d'avoir un cluster, mais notre cas d'utilisation est différent.
Architecture à 30000 pieds
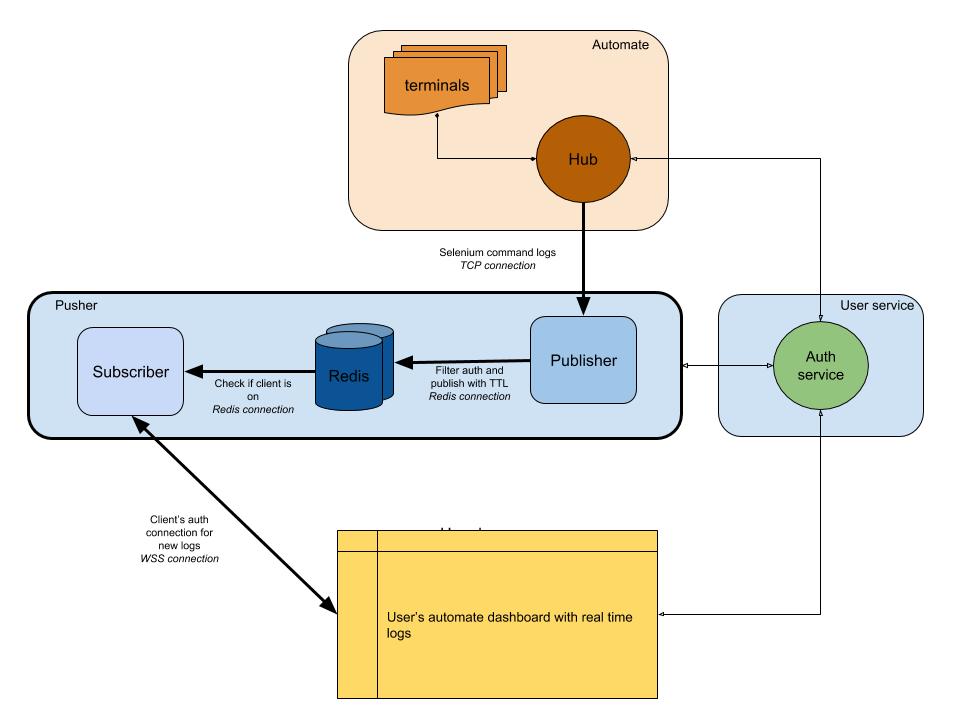
Le diagramme ci-dessous fournit une image de très haut niveau du fonctionnement de nos tableaux de bord Automate et App Automate . Rappelez-vous le système en temps réel que nous avions dans la section précédente

Tableaux de bord Automate et App Automate en temps réel de BrowserStack ( Large preview ) Dans notre diagramme, notre flux de travail principal est mis en évidence avec des bordures plus épaisses. La section "automate" se compose de:
- Terminaux
Comprend les versions vierges de Windows, OSX, Android ou iOS que vous obtenez lors de tests sur BrowserStack. - Hub
point de contact pour tous vos tests Selenium et Appium avec BrowserStack.
La section "service utilisateur" ici est notre gatekeeper, assurant que les données sont envoyées et sauvegardées pour la bonne personne. C'est aussi notre gardien de sécurité. La section «poussoir» incorpore le cœur de ce que nous avons discuté dans cet article. Il se compose des suspects habituels, y compris:
- Redis
Notre stockage transitoire pour les messages, où dans notre cas automatiser les journaux sont temporairement stockés. - Éditeur
Ceci est essentiellement l'entité obtient les données du concentrateur. Toutes les réponses à vos demandes sont capturées par ce composant qui écrit sur Redis avecsession_idcomme canal. - Abonné
Ceci lit les données de Redis générées pour lesession_id. Il est également le serveur Web pour les clients de se connecter via WebSocket (ou HTTP) pour obtenir des données, puis l'envoie aux clients authentifiés.
Enfin, nous avons la section du navigateur de l'utilisateur, représentant une connexion WebSocket authentifiée pour garantir
session_idles journaux sont envoyés. Cela permet au JS frontal de l'analyser et de l'embellir pour les utilisateurs.Similaire au service de logs, nous avons ici un pousseur qui est utilisé pour d'autres intégrations de produits. Au lieu de
session_idnous utilisons une autre forme d'ID pour représenter ce canal.Conclusion (TLDR)
Nous avons eu beaucoup de succès dans la construction de Pub / Sub. Pour résumer pourquoi nous l'avons construit en interne:
- Échelle mieux pour nos besoins;
- Moins cher que les services externalisés;
- Contrôle total sur l'architecture globale.
Sans oublier que JS est le parfait ajustement pour ce genre de scénario. Boucle d'événement et quantité massive d'IO est ce dont le problème a besoin! JavaScript est la magie du pseudo-thread unique.
Evénements et Redis en tant que système gardent les choses simples pour les développeurs, car vous pouvez obtenir des données d'une source et les envoyer à une autre via Redis. Donc, nous l'avons construit.
Si l'utilisation correspond à votre système, je recommande de faire la même chose!
 (rb, ra, il)
(rb, ra, il) - ioredis
Source link