
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
API des règles de spéculation Boost Speed : prérendu, prélecture
Découvrez comment pré-afficher et pré-extraire à l’aide de l’API Speculation Rules pour améliorer les performances de votre site.
Le prérendu est un modèle couramment utilisé pour accélérer les applications Web. C’est une technique que certains navigateurs (par exemple Chrome) et frameworks JavaScript (par exemple Next.js) utilisent pour améliorer les performances de chargement d’une page Web.
Chaque page du routeur de pages Next.js est pré-rendue par défaut. Cela signifie qu’il génère du HTML pour chaque page à l’avance, au lieu de s’appuyer entièrement sur JavaScript côté client. Chrome prend en charge le <link rel="prerender" href="https://www.telerik.com/next-route"> indice de ressource, mais il n’était pas largement pris en charge au-delà de Chrome.
Bien que Chrome, Next.js et d’autres aient évolué dans la manière dont ils appliquent ce modèle, cela démontre que le prérendu peut entraîner de meilleures performances et un meilleur référencement.
Les techniques de prérendu dans les frameworks JavaScript sont propres à chaque framework, et celles de Chrome <link rel="prerender" /> a été déprécié au profit de Aucune prélecture d’état. Cependant, il existe un meilleur moyen, qui fait désormais partie de l’API de la plate-forme Web : le API des règles de spéculation.
Présentation de l’API des règles de spéculation
Le API des règles de spéculation est une fonctionnalité récente du navigateur qui vous permet dis au navigateur quelles pages récupérer ou afficher en arrière-plan, améliorant ainsi la navigation suivante vitesse. En d’autres termes, vous définissez un ensemble de règles que le navigateur utilise pour prédire quand une page doit être récupérée ou pré-affichée, avant que l’utilisateur ne navigue activement vers cette page.
Il est explicitement conçu pour les sites Web multipages (MPA) plutôt que pour les applications à page unique (SPA). Si vous créez un SPA, vous devez utiliser l’API de prélecture ou de prérendu de votre framework.
Il existe deux types d’actions spéculatives (ou types de chargement) :
- Pré-rendu: Ceci télécharge les ressources d’une page et affiche la page en arrière-plan. La page rendue est immédiatement affiché lorsque l’utilisateur y accède.
- Prélecture: cela récupère les ressources clés d’une page mais ne restitue pas la page. La page doit toujours être affichée lorsque l’utilisateur y accède.
Les règles de spéculation sont utiles chaque fois que vous le pouvez prédire quelle page un utilisateur est susceptible de visiter ensuite. Les scénarios courants pour leur utilisation incluent les sites de commerce électronique et les sites multimédias. Par exemple, pré-afficher une page de détail d’un produit ou pré-extraire les ressources pour la page de paiement. La même idée s’applique à un site de documentation, où le pré-affichage impatient de la page suivante la fera se charger instantanément lorsque l’utilisateur y accédera. Cela peut améliorer les Core Web Vitals (comme LCP) sur ces navigations et stimule souvent l’engagement.
Anatomie des règles de spéculation
Les règles de spéculation sont écrites en JSON, à l’intérieur d’un <script type="speculationrules"> block dans votre HTML ou dans un fichier JSON externe référencé via le Speculation-Rules En-tête HTTP. Le JSON a des clés distinctes pour "prefetch" et "prerender"qui représentent les deux types de chargement spéculatif. Ils correspondent chacun à un tableau d’objets de règle. Par exemple:
<script type="speculationrules">
{
"prerender": [
{ "urls": ["/blog", "/newsletter"] }
],
"prefetch": [
{ "urls": ["/contact.html"] }
]
}
</script>
Dans cet extrait, deux URL (/blog et /newsletter) sont répertoriés sous prerenderet une URL (/contact.html) sous prefetch. Le prerender règle oblige le navigateur à restituer entièrement ces pages en arrière-plan, tandis qu’un prefetch la règle récupère uniquement le code HTML.
Le urls list (comme on le voit dans l’exemple) sera activée immédiatement après l’analyse. Le navigateur suppose qu’il s’agit d’URL hautement prioritaires que vous souhaitez rendre disponibles dès que possible. Mon règle générale est de toujours préciser le eagerness propriété pour la rendre explicite aux autres développeurs et au navigateur.
Le eagerness La propriété spécifie quelle heuristique le navigateur doit utiliser pour déterminer quand appliquer la règle. Les options sont :
- immédiat: La prélecture/prérendu doit démarrer dès que possible.
- désireux: La prélecture/prérendu doit démarrer dès qu’une légère suggestion indique qu’un lien peut être suivi. Par exemple, déplacer le curseur vers le lien ou faire défiler la section du lien dans la fenêtre.
- conservateur: Utilisé lorsque vous souhaitez obtenir un avantage mais avec un compromis de ressources assez faible. L’action spéculative ne doit démarrer que lorsque l’utilisateur commence à cliquer sur le lien, par exemple sur le
mousedownévénement. - modéré: établit un équilibre entre désireux et conservateur.
Exemple concret
Il existe de nombreuses règles au-delà de ce que vous avez vu dans la section précédente, et je ne les aborderai pas toutes en détail. Regardons un exemple pratique et revisitons les règles plus tard. Nous utiliserons mon site Web pmbanugo.me à titre d’exemple. Il existe quelques itinéraires importants :
- Le Page d’accueil.
- Le Listes de blogs page (/blog), qui affiche la liste des articles du blog, ainsi que la navigation.
- Le Article de blog page (/blog/ :), qui contient le contenu des messages réels.
Je souhaite utiliser le chargement spéculatif pour les pré-afficher. Je veux avec impatience charger les pages d’accueil et de liste de blogs, car ce sont généralement les pages suivantes que les visiteurs de mon site Web consultent. La page du billet de blog (/blog/:) utilisera le modéré algorithme.

Voici comment nous allons définir la règle pour cette exigence :
<script type="speculationrules">
{
"prerender": [
{
"urls": ["https://www.telerik.com/", "/blog"],
"eagerness": "eager"
},
{
"where": {
"href_matches": "/blog/*"
},
"eagerness": "moderate"
}
]
}
</script>
Le where La propriété spécifie le filtre appliqué lors de la recherche dans le document de liens répondant aux critères. Le href_matches précise un Modèle d’URL qui sera utilisé pour le filtrage. En résumé, le navigateur analysera la page à la recherche de liens correspondant à ce modèle d’URL, puis les préaffichera lorsqu’il y aura une indication que l’utilisateur est sur le point de naviguer vers cette page.
Passons en revue les performances de chargement de pmbanugo.me avant d’appliquer le changement. L’enregistrement vidéo ci-dessous me montre en train de naviguer sur le site avec le cache du navigateur désactivé.
J’ai limité les performances à une connexion Fast 4G afin que nous puissions voir comment cela fonctionne sans la vitesse de navigation habituelle de mon Internet domestique. Je ferai de même pour la version avec des règles de spéculation.
La vidéo ci-dessus montre les mêmes navigations mais en utilisant des règles de spéculation. Vous remarquerez peut-être que malgré la limitation à 4G rapideles pages se chargent instantanément. Pour le /blog/:<slug> page, j’ai attendu un peu avant de cliquer. Cela lui donne suffisamment de temps pour récupérer et restituer dans des conditions limitées. Sinon, les demandes de ressources pourraient être encore en cours et la page pourrait ne pas encore être pré-affichée.
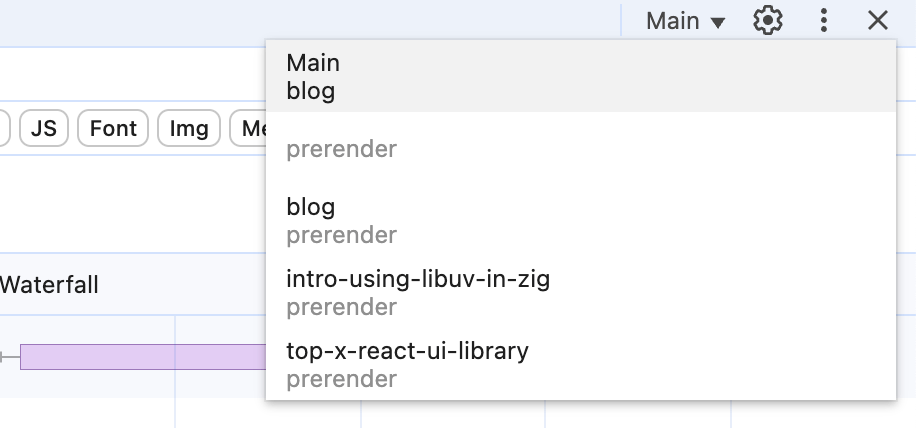
Vous devrez peut-être inspecter le comportement de vos règles de spéculation. Cela diffère selon les navigateurs et peut changer avec le temps. La capture d’écran ci-dessous montre à quoi cela ressemble dans Chrome 136.
La liste déroulante affiche le document actuel avec le titre Main. Toute autre ressource préextraite ou pré-rendue affichera le chemin de la ressource et l’action de spéculation. Dans cet exemple, blog/top-x-react-ui-library a été pré-rendu.
La vidéo ci-dessous montre le comportement des règles de spéculation et l’effet réseau/performance associé. Vous devriez également remarquer que les navigations se font instantanément.
Indice: Faites attention à la fenêtre DevTools.
Plus de propriétés de règle
J’ai mentionné quelques règles de l’exemple que vous avez vu. Il y a plus de règles et je ne peux pas toutes les utiliser dans mon exemple. Chaque objet de règle peut inclure plusieurs propriétés pour contrôler quand et comment le chargement a lieu. Certaines propriétés importantes des règles sont :
urls: un tableau d’URL de chaîne à pré-extraire/pré-afficher.where: Un objet pour filtrer les liens sur la page (utilisé dans règles de documents). Il peut utiliser des conditions telles quehref_matches(avec des caractères génériques),selector_matches(sélecteurs CSS) et wrappers logiquesand/or/notpour inclure ou exclure certains liens. Par exemple,{ "where": { "href_matches": "/blog/*" } }correspondrait à tous les liens de même origine sous/blog/.eagerness: Ceci contrôle quand déclencher la spéculation. Les options sont"immediate","eager","moderate"ou"conservative". Par exemple,"immediate"se déclenche dès que la règle est analysée, tandis que"moderate"attend que l’utilisateur survole un lien pendant environ 200 ms (ou souris enfoncée). Utilisation des règles de liste d’URLimmediatepar défaut.requires: Un tableau de chaînes d’exigences, par exemple,"anonymous-client-ip-when-cross-origin"qui applique les paramètres de confidentialité. Il supprime l’adresse IP du client lors des requêtes intersites.referrer_policy: Une chaîne comme"no-referrer"pour contrôler leRefereren-tête sur les demandes spéculatives.relative_to: Une chaîne spécifiant où vous voulez que les liens correspondent à un URL à correspondre par rapport à.expects_no_vary_search: Un indice de mise en cache utilisé lorsque les paramètres de requête ne modifient pas réellement le contenu.tag: chaîne utilisée pour identifier une règle ou un ensemble de règles. Cela pourrait être utile pour le débogage.source: Une propriété facultative indiquant la source des URL auxquelles la règle s’applique. La valeur peut être soit"list"ou"document".
C’est un emballage
Les règles de spéculation sont une nouvelle façon pour les développeurs d’indiquer aux navigateurs de charger les ressources plus tôt, avant que l’utilisateur ne les demande réellement. Ils améliorent les performances de votre site Web et peuvent conduire à une fidélisation et une conversion client plus élevées. Ils proposent deux modèles de chargement spéculatifs : la prélecture et le prérendu. Nous avons examiné ce qu’elles sont et concentré l’exemple sur quelques règles et le modèle de pré-rendu.
Vous êtes probablement ravi de les utiliser en fonction de ce que vous avez vu dans les démos/vidéos. Notez qu’ils ne sont pas encore implémentés dans tous les navigateurs. Ils sont disponibles dans les navigateurs basés sur Chromium comme Chrome, Edge et Opera. Lorsque vous les utilisez, pensez à proposer des alternatives aux utilisateurs sur les navigateurs sur lesquels ils ne sont pas pris en charge. Les liens ci-dessous contiennent plus d’informations :
- API des règles de spéculation (MDN)
- Spécification détaillée des règles (MDN)
- Compatibilité du navigateur (MDN)
- Projet de spécification par le groupe communautaire Web Platform Incubator.
Source link