
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Accélérateur de données pour les applications Oracle Fusion

Suivre mon post précédent qui met en évidence différentes approches d’accès aux données des applications de cloud Oracle Fusion à partir de données, je présente dans ce post les détails de l’approche D, qui exploite la solution d’accélérateur perficient. Et cet accélérateur s’applique à toutes les applications de cloud Oracle Fusion: ERP, SCM, HCM et CX.
Comme démontré dans le post précédentl’accélérateur perficient diffère des autres approches en ce qu’elle a des exigences minimales pour des services de plate-forme cloud supplémentaires. Les autres approches d’extraction de données efficacement et de manière évolutive nécessitent le déploiement de services cloud supplémentaires tels que les services d’intégration / réplication de données et un entrepôt de données intermédiaire. Avec l’accélérateur perficient, cependant, la réplication est motivée par des techniques qui dépendent uniquement de la fusion d’Oracle native et de Databricks. L’accélérateur se compose d’un workflow Databricks avec des tâches configurables pour gérer le processus de bout en bout de la gestion de la réplication des données d’Oracle Fusion dans la couche argentée des tables de données. Lors du déploiement de la solution, vous avez accès à tous les ordinateurs portables Python / SQL sous-jacents qui peuvent être plus personnalisés en fonction de vos besoins.
Pourquoi envisager de déployer l’accélérateur perficient?
Il y a plusieurs avantages à déployer cet accélérateur plutôt que de créer des réplications de données d’Oracle Fusion à partir de zéro. Construit avec l’automatisation, la solution est à l’épreuve du temps et permet d’évoluer pour répondre facilement aux exigences de données en évolution. Le diagramme ci-dessous met en évidence les considérations clés.
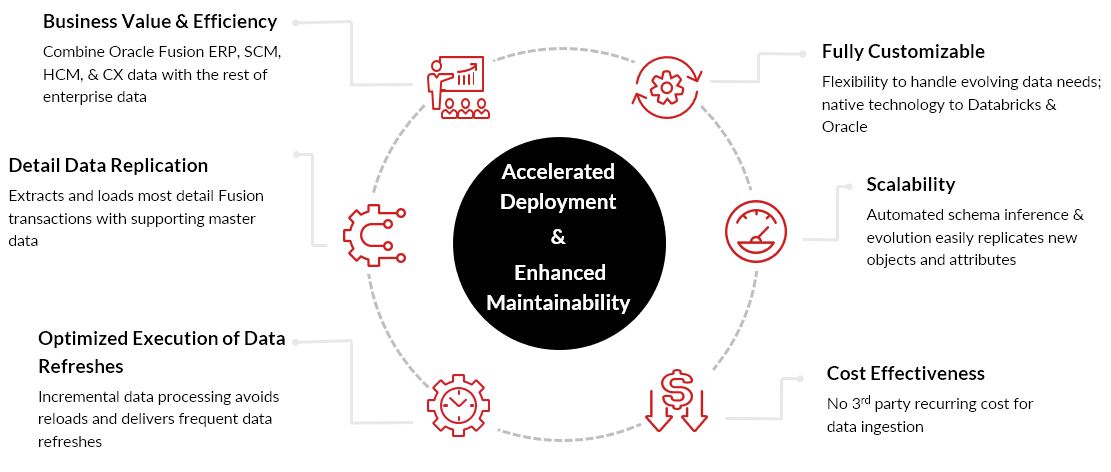
Un regard plus approfondi sur la façon dont c’est fait
Dans le cloud Oracle: La solution perfictive exploite le connecteur Cloud Oracle BI (BICC) qui est la méthode préférée d’extraction des données en vrac d’Oracle Fusion tout en minimisant l’impact sur l’application de fusion elle-même. Les données et les métadonnées extraites sont temporairement disponibles dans les seaux de stockage d’objets OCI pour le traitement en aval. L’archivisme des données exportées du côté OCI (Oracle Cloud Infrastructure) est également géré automatiquement, si nécessaire, avec des règles de purge.

Dans le cloud d’hébergement de données de données:
- Hébergé dans l’un des: AWS, Azure ou GCP, le travail de workflow et les carnets de workflow de l’accélérateur sont déployés dans l’espace de travail de Databricks. Le schéma de tables delta de Databricks, les fichiers de configuration et de journal sont tous hébergés dans le catalogue d’unité Databricks.
- Les ordinateurs portables exploitent le code paramétré pour déterminer par programmation quels objets de vue de fusion se répliquent via les tables en argent.
- Le flux de travail Databricks déclenche l’extraction de données d’Oracle Fusion BICC basé sur un travail de fusion BICC prédéfini. Le travail BICC détermine les objets extraits.
- Les fichiers sont ensuite transférés de OCI vers un magasin d’objets de zone d’atterrissage dans le cloud qui héberge les données de données.
- Databricks Autoloader gère l’ingestion de données dans des tables en direct en bronze qui stockent des opérations historiques, de mise à jour et de supprimer des opérations pertinentes pour les objets extraits.
- Les tables en direct Silver en direct sont ensuite chargées à partir de bronze via un pipeline DLT géré par Databricks. Les tables en argent sont dénudées et représentent le même niveau de granularité des données pour chaque objet de vue de fusion que dans la fusion.
- Les rafraîchissements de table incrémentiels sont configurés en tirant automatiquement des métadonnées d’objet Oracle Fusion qui permet aux données incrémentielles de fusion dans les données de données. Cela inclut la délétion de toute suppression des données d’Oracle Fusion et le traitement des suppressions dans les tables d’argent.
Qu’il s’agisse de commencer petit avec quelques tables ou de chercher facilement à évoluer à des centaines et des milliers de tables, l’accélérateur de données de données perficient pour Oracle Fusion Data gère l’orchestration de flux de travail de bout en bout. En conséquence, vous finissez par passer moins de temps avec l’intégration des données et les efforts de concentration sur les modèles de données analytiques auxquels sont confrontés les entreprises.
Pour obtenir de l’aide pour activer l’intégration des données entre les applications Oracle Fusion et Databricks, contactez mazen.manasseh@perficient.com.
Source link