


{kind=link}
{kind=link}
{kind=link}
{kind=link}
L’outil secret pour exploser ton chiffre d'affaires en 2025 !
Comment nous avons utilisé WebAssembly pour accélérer notre application Web en 20X (étude de cas)
À propos de l'auteur
Robert est ingénieur en logiciels en bioinformatique à Invitae, ce qui signifie qu'il passe son temps à… des logiciels d'ingénierie à des fins de bioinformatique. …
Pour en savoir plus sur Robert …
Si vous ne l'avez pas entendu, voici le TL; DR: WebAssembly est un nouveau langage qui s'exécute dans le navigateur parallèlement à JavaScript. Oui c'est vrai. JavaScript n'est plus le seul langage qui fonctionne dans le navigateur!
Mais au-delà du simple “non JavaScript”, son facteur distinctif est qu'il permet de compiler du code à partir de langages tels que C / C ++ / Rust ( et plus encore!). ) à WebAssembly et exécutez-les dans le navigateur. Etant donné que WebAssembly est typé de manière statique, utilise une mémoire linéaire et est stocké dans un format binaire compact, il est également très rapide et pourrait éventuellement nous permettre d'exécuter du code à des vitesses «presque natives», c'est-à-dire à des vitesses proches de ce que vous ' d obtenir en exécutant le binaire sur la ligne de commande. La capacité à exploiter des outils et des bibliothèques existants pour une utilisation dans le navigateur et le potentiel d’accélération associé, sont deux raisons qui rendent WebAssembly si attrayant pour le Web.
Jusqu'à présent, WebAssembly a été utilisé pour toutes sortes d’applications, allant de jeux (par exemple, Doom 3 ), pour le portage d’applications bureautiques sur le Web (par exemple, Autocad et Figma ). Il est même utilisé en dehors du navigateur, par exemple en tant que langage efficace et flexible pour l'informatique sans serveur .
Cet article présente une étude de cas sur l'utilisation de WebAssembly pour accélérer un outil Web d'analyse de données. À cette fin, prenons un outil existant écrit en C qui effectue les mêmes calculs, le compilons dans WebAssembly et l’utilisons pour remplacer les calculs JavaScript lents.
Note : Cet article explore des sujets avancés tels que la compilation de code C, mais ne vous inquiétez pas si vous n'en avez pas l'expérience; vous pourrez toujours suivre et avoir une idée de ce qu'il est possible de faire avec WebAssembly.
Contexte
L'application Web avec laquelle nous allons travailler est fastq.bio un outil Web interactif qui fournit scientifiques avec un aperçu rapide de la qualité de leurs données de séquençage de l'ADN; le séquençage est le processus par lequel nous lisons les “lettres” (c'est-à-dire les nucléotides) dans un échantillon d'ADN.
Voici une capture d'écran de l'application en action:
![Tracés interactifs montrant les métriques de l'utilisateur pour évaluer la qualité de ses données [19659013] Une capture d'écran de fastq.bio en action (<a href=](https://i0.wp.com/cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/06e27be8-1fef-468b-9d23-40ae53e0a354/webassembly-speed-web-app1.png?ssl=1) Grand aperçu )
Grand aperçu )Nous n'entrerons pas dans les détails des calculs, mais en résumé, les graphiques ci-dessus donnent aux scientifiques une idée de leur efficacité. le séquençage a servi et sert à identifier rapidement les problèmes de qualité des données.
Bien qu'il existe des dizaines d'outils en ligne de commande permettant de générer de tels rapports de contrôle de la qualité, l'objectif de fastq.bio est de donner un aperçu interactif de la qualité des données sans quitter le navigateur. Ceci est particulièrement utile pour les scientifiques qui ne maîtrisent pas la ligne de commande.
L'entrée de l'application est un fichier texte généré par l'instrument de séquençage, qui contient une liste de séquences d'ADN et un score de qualité pour chaque nucléotide. dans les séquences d'ADN. Le format de ce fichier est appelé «FASTQ», d'où le nom fastq.bio.
Si vous souhaitez en savoir plus sur le format FASTQ (inutile de comprendre cet article), consultez la page Wikipedia . ] pour FASTQ. (Avertissement: le format de fichier FASTQ est connu dans le domaine pour induire facepalms.)
fastq.bio: l'implémentation de JavaScript
Dans la version d'origine de fastq.bio, l'utilisateur commence par sélectionner un fichier FASTQ à partir de son ordinateur. . Avec l'objet File l'application lit un petit bloc de données commençant à une position d'octet aléatoire (à l'aide de l'API FileReader API ). Dans ce bloc de données, nous utilisons JavaScript pour effectuer des manipulations de base des chaînes et calculer les métriques pertinentes. Une de ces métriques nous aide à suivre le nombre de A, C, G et T. que nous voyons généralement à chaque position le long d'un fragment d'ADN.
Une fois que les métriques sont calculées pour cette partie de données, nous traçons les résultats de manière interactive avec . .js et passez au bloc suivant dans le fichier. Le traitement du fichier par petits morceaux a simplement pour but d'améliorer l'expérience de l'utilisateur: le traitement du fichier entier en une fois serait trop long, car les fichiers FASTQ représentent généralement des centaines de gigaoctets. Nous avons constaté qu'une taille de bloc comprise entre 0,5 Mo et 1 Mo rendrait l'application plus transparente et renverrait plus rapidement les informations à l'utilisateur, mais ce nombre variera en fonction des détails de votre application et de la charge des calculs.
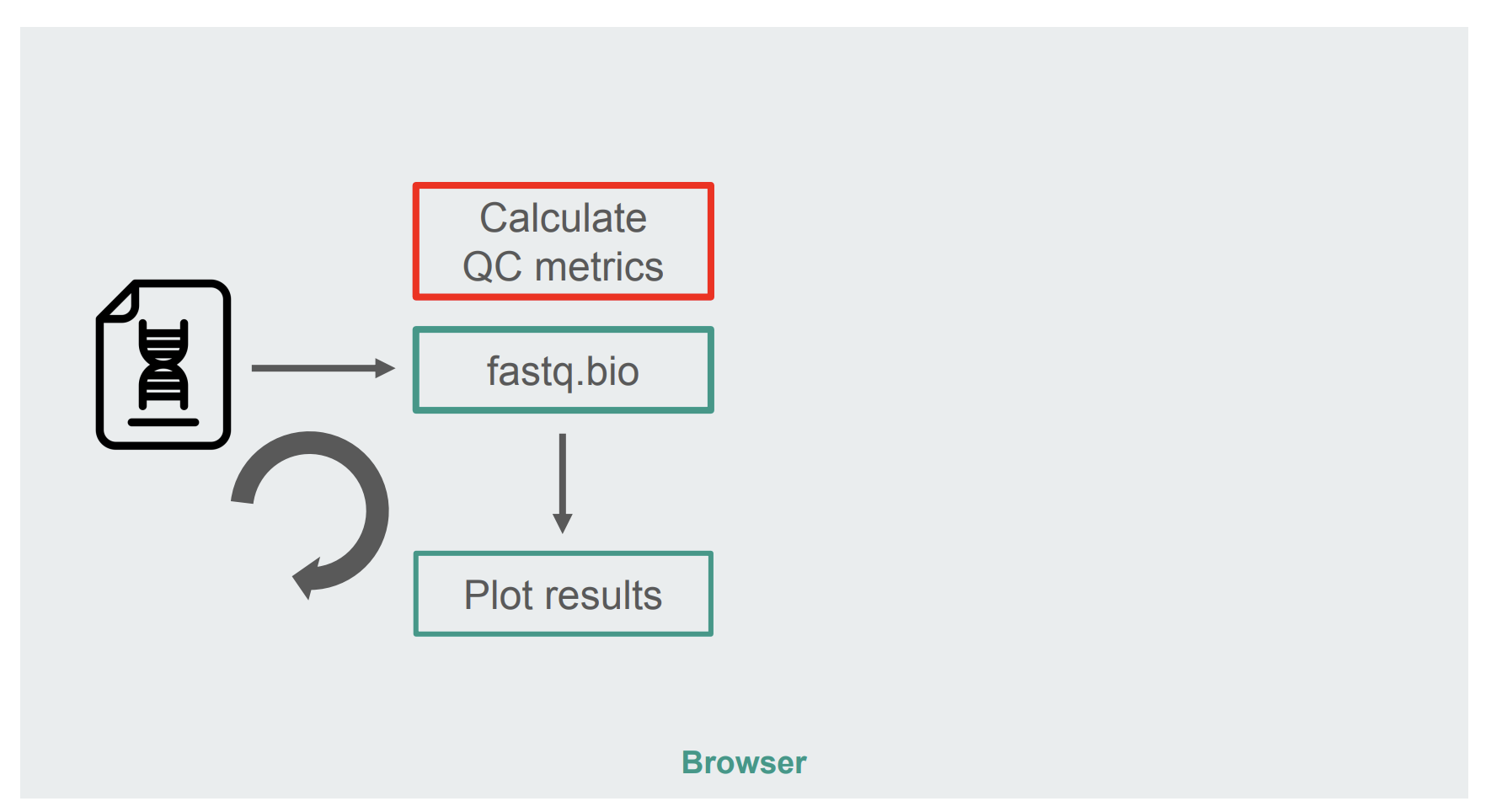
L'architecture de notre implémentation JavaScript originale était assez simple:

La boîte en rouge est l'endroit où nous faisons les manipulations de chaîne pour générer les métriques. Cette boîte est la partie de l'application la plus intensive en calcul, ce qui en faisait naturellement un bon candidat pour l'optimisation de l'exécution avec WebAssembly.
fastq.bio: L'implémentation de WebAssembly
Pour explorer si nous pouvions utiliser WebAssembly pour accélérer notre application Web, nous avons recherché un outil prêt à l'emploi permettant de calculer les paramètres de contrôle de la qualité sur les fichiers FASTQ. Plus précisément, nous recherchions un outil écrit en C / C ++ / Rust pour pouvoir le porter sur WebAssembly, un outil déjà validé et approuvé par la communauté scientifique.
Après quelques recherches, nous avons décidé de choisir . ] seqtk un outil open source couramment utilisé écrit en C qui peut nous aider à évaluer la qualité des données de séquençage (et est plus généralement utilisé pour manipuler ces fichiers de données).
Avant de compiler dans WebAssembly, Voyons d'abord comment nous compilerions normalement seqtk en binaire pour l'exécuter sur la ligne de commande. Selon le Makefile, il s’agit de l’incantation gcc dont vous avez besoin:
# Compile to binary
$ gcc seqtk.c
-o seqtk
-O2
-lm
-lz
D'autre part, pour compiler seqtk dans WebAssembly, nous pouvons utiliser la Emscripten toolchain qui permet de remplacer directement les outils de génération existants pour faciliter l'utilisation de WebAssembly. Si vous n'avez pas installé Emscripten, vous pouvez télécharger une image de menu fixe que nous avons préparée sur Dockerhub et qui contient les outils nécessaires (vous pouvez également l'installer à partir de zéro mais prend habituellement un certain temps):
$ docker pull robertaboukhalil / emsdk: 1.38.26
$ docker run -dt --name wasm-seqtk robertaboukhalil / emsdk: 1.38.26
Dans le conteneur, nous pouvons utiliser le compilateur emcc en remplacement de gcc :
# Compile to WebAssembly.
$ emcc seqtk.c
-o seqtk.js
-O2
-lm
-s USE_ZLIB = 1
-s FORCE_FILESYSTEM = 1
Comme vous pouvez le constater, les différences entre la compilation au format binaire et WebAssembly sont minimes:
- Au lieu du fichier binaire généré en sortie
seqtknous demandons à Emscripten de générer un.et un.jsqui gère l'instanciation de notre module WebAssembly - Pour prendre en charge la bibliothèque zlib, nous utilisons le drapeau
USE_ZLIB; zlib est si commun qu'il a déjà été porté sur WebAssembly et Emscripten l'inclura pour nous dans notre projet - . Nous activons le système de fichiers virtuel d'Emscripten, qui est un système de fichiers de type POSIX (ici le code source ici ), sauf qu'il fonctionne dans la mémoire vive du navigateur et disparaît lorsque vous actualisez la page (sauf si vous enregistrez son état dans le navigateur à l'aide de IndexedDB, mais c'est pour un autre article).
Pourquoi un système de fichiers virtuel? Pour répondre à cette question, comparons la façon dont nous appellerions seqtk sur la ligne de commande et l’utilisation de JavaScript pour appeler le module WebAssembly compilé:
# Sur la ligne de commande
$ ./seqtk fqchk data.fastq
# Dans la console du navigateur
> Module.callMain (["fqchk", "data.fastq"])
Avoir accès à un système de fichiers virtuel est puissant car cela signifie que nous n’avons pas à réécrire seqtk pour gérer les entrées de chaîne au lieu des chemins de fichiers. Nous pouvons monter un bloc de données sous la forme du fichier data.fastq sur le système de fichiers virtuel et simplement appeler la fonction main () de seqtk.
Avec seqtk compilé dans WebAssembly, voici la nouvelle architecture fastq.bio:

Comme indiqué dans le diagramme, au lieu d'exécuter les calculs dans le fil principal du navigateur, nous utilisons WebWorkers ce qui nous permet d'exécuter nos calculs dans un fil de fond. et évitez d’affecter négativement la réactivité du navigateur. Plus précisément, le contrôleur WebWorker lance le programme de travail et gère la communication avec le thread principal. Du côté du travailleur, une API exécute les demandes qu’elle reçoit.
Nous pouvons ensuite demander au travailleur d’exécuter une commande seqtk sur le fichier que nous venons de monter. Lorsque seqtk a terminé son exécution, le travailleur renvoie le résultat au thread principal via une promesse. Une fois le message reçu, le thread principal utilise la sortie obtenue pour mettre à jour les graphiques. Semblable à la version JavaScript, nous traitons les fichiers en morceaux et mettons à jour les visualisations à chaque itération.
Optimisation des performances
Pour évaluer si l'utilisation de WebAssembly a été bénéfique, nous comparons les implémentations de JavaScript et de WebAssembly à l'aide de la métrique lit nous pouvons traiter par seconde. Nous ignorons le temps nécessaire pour générer des graphiques interactifs, car les deux implémentations utilisent JavaScript à cette fin.
Dès l'installation, nous voyons déjà un accélération de ~ 9 fois:

C'est déjà très bien, vu que c'était relativement facile à réaliser (c'est une fois que vous comprenez WebAssembly!).
Ensuite, nous avons remarqué que seqtk génère beaucoup des mesures de CQ généralement utiles, beaucoup de ces mesures ne sont pas réellement utilisées ni représentées par notre application. En supprimant une partie de la sortie des métriques dont nous n'avions pas besoin, nous avons pu voir une accélération encore plus rapide de 13X:

Il s'agit là encore d'une grande amélioration, compte tenu de la facilité avec laquelle il a été réalisé – en commentant littéralement les déclarations printf qui n'étaient pas nécessaires.
Enfin, nous avons examiné une autre amélioration. dans. Jusqu'à présent, fastq.bio obtient les métriques d'intérêt en appelant deux fonctions C différentes, chacune d'entre elles permettant de calculer un ensemble de métriques différent. Plus précisément, une fonction renvoie des informations sous la forme d’un histogramme (c’est-à-dire une liste de valeurs que nous classons dans des plages), tandis que l’autre fonction renvoie des informations en fonction de la position de la séquence de l’ADN. Malheureusement, cela signifie que le même bloc de fichier est lu deux fois, ce qui est inutile.
Nous avons donc fusionné le code des deux fonctions en une seule fonction, même si elle était désordonnée (sans même avoir à rafraîchir mon C!). Comme les deux sorties ont un nombre de colonnes différent, nous avons procédé à des discussions sur le côté JavaScript pour les démêler. Mais cela en valait la peine: cela nous a permis d'obtenir une accélération> 20X!

Un mot de prudence
Ce serait le bon moment pour faire une mise en garde. Ne vous attendez pas à toujours obtenir une accélération 20X lorsque vous utilisez WebAssembly. Vous pourriez obtenir seulement une accélération 2X ou 20%. Vous pouvez également ralentir si vous chargez de très gros fichiers en mémoire ou si vous avez besoin de beaucoup de communication entre WebAssembly et JavaScript.
Conclusion
En résumé, nous avons constaté que le remplacement des calculs JavaScript lents par des appels WebAssembly compilé peut conduire à des accélérations significatives. Comme le code nécessaire pour ces calculs existait déjà en C, nous avons eu l'avantage supplémentaire de réutiliser un outil de confiance. Comme nous en avons déjà parlé, WebAssembly ne sera pas toujours le bon outil pour le travail ( halètement! ), utilisez-le donc à bon escient.
Pour en savoir plus
 (rb, ra, il)
(rb, ra, il) Source link