



Les réseaux de neurones profonds sont devenus célèbres pour leur capacité à traiter des informations visuelles. Et au cours des dernières années, ils sont devenus un élément clé de nombreuses applications de vision par ordinateur.
Parmi les problèmes clés que les réseaux de neurones peuvent résoudre, il y a la détection et la localisation d'objets dans les images. La détection d'objets est utilisée dans de nombreux domaines différents, notamment la conduite autonomela vidéosurveillance et les soins de santé.
Dans cet article, je passerai brièvement en revue les architectures d'apprentissage en profondeur[19659007] qui aident les ordinateurs à détecter des objets.
Réseaux de neurones convolutifs
L'un des composants clés de la plupart des applications de vision par ordinateur basées sur l'apprentissage profond est le réseau de neurones convolutifs (CNN). Inventés dans les années 1980 par le pionnier de l'apprentissage en profondeur Yann LeCunles CNN sont un type de réseau de neurones efficace pour capturer des modèles dans des espaces multidimensionnels. Cela rend les CNN particulièrement adaptés aux images, bien qu'ils soient également utilisés pour traiter d'autres types de données. (Pour nous concentrer sur les données visuelles, nous considérerons nos réseaux de neurones convolutifs comme étant bidimensionnels dans cet article.)
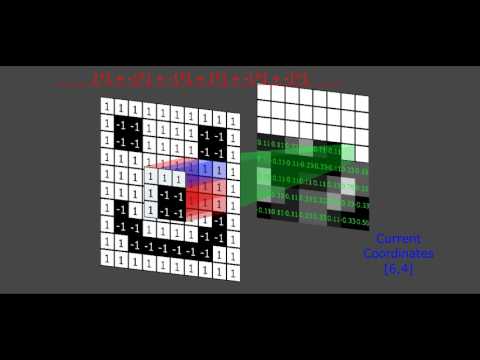
Chaque réseau de neurones convolutifs est composé d'un ou plusieurs couches convolutives un composant logiciel qui extrait des valeurs significatives de l'image d'entrée. Et chaque couche de convolution est composée de plusieurs filtres, des matrices carrées qui glissent sur l'image et enregistrent la somme pondérée des valeurs de pixels à différents emplacements. Chaque filtre a des valeurs différentes et extrait différentes caractéristiques de l'image d'entrée. La sortie d'une couche de convolution est un ensemble de "cartes de caractéristiques".
Lorsqu'elles sont empilées les unes sur les autres, les couches de convolution peuvent détecter une hiérarchie de modèles visuels. Par exemple, les couches inférieures produiront des cartes de caractéristiques pour les bords verticaux et horizontaux, les coins et d'autres motifs simples. Les couches suivantes peuvent détecter des motifs plus complexes tels que des grilles et des cercles. Au fur et à mesure que vous vous enfoncez dans le réseau, les couches détectent des objets complexes tels que des voitures, des maisons, des arbres et des personnes.


La plupart des réseaux de neurones convolutifs utilisent regrouper les couches pour réduire progressivement la taille de leurs cartes de caractéristiques et conserver les parties les plus saillantes. Max-pooling, qui est actuellement le principal type de couche de pooling utilisé dans les CNN, conserve la valeur maximale dans un patch de pixels. Par exemple, si vous utilisez une couche de pooling de taille 2, elle prendra des patchs de 2×2 pixels à partir des cartes de caractéristiques produites par la couche précédente et conservera la valeur la plus élevée. Cette opération divise par deux la taille des cartes et conserve les caractéristiques les plus pertinentes. Les couches de mise en commun permettent aux CNN de généraliser leurs capacités et d'être moins sensibles au déplacement d'objets à travers les images.
Enfin, la sortie des couches de convolution est aplatie en une matrice à dimension unique qui est la représentation numérique des caractéristiques contenues dans l'image. . Cette matrice est ensuite introduite dans une série de couches « entièrement connectées » de neurones artificiels qui mappent les caractéristiques au type de sortie attendu du réseau.




La tâche la plus fondamentale pour les réseaux de neurones convolutifs sont une classification d'images, dans laquelle le réseau prend une image en entrée et renvoie une liste de valeurs qui représentent la probabilité que l'image appartienne à l'une de plusieurs classes.
Par exemple, disons que vous souhaitez entraîner un réseau de neurones. pour détecter les 1 000 classes d'objets contenus dans le populaire jeu de données open source ImageNet. Dans ce cas, votre couche de sortie aura 1 000 sorties numériques, chacune contenant la probabilité que l'image appartienne à l'une de ces classes.
Vous pouvez toujours créer et tester votre propre réseau de neurones convolutifs à partir de zéro. Mais la plupart des chercheurs et développeurs en apprentissage automatique utilisent l'un des nombreux réseaux de neurones convolutifs éprouvés tels que AlexNet, VGG16 et ResNet-50.
Ensembles de données de détection d'objets



Alors qu'un réseau de classification d'images peut dire si une image contient un certain objet ou non, il ne dira pas où dans l'image l'objet se trouve. Les réseaux de détection d'objets fournissent à la fois la classe d'objets contenus dans une image et une boîte englobante qui fournit les coordonnées de cet objet.
Les réseaux de détection d'objets ressemblent beaucoup aux réseaux de classification d'images et utilisent des couches de convolution pour détecter les caractéristiques visuelles. En fait, la plupart des réseaux de détection d'objets utilisent une classification d'images CNN et la réutilisent pour la détection d'objets.
La détection d'objets est un problème d'apprentissage automatique superviséce qui signifie que vous devez entraîner vos modèles sur des exemples étiquetés. . Chaque image de l'ensemble de données d'apprentissage doit être accompagnée d'un fichier qui inclut les limites et les classes des objets qu'elle contient. Il existe plusieurs outils open source qui créent des annotations de détection d'objets.



Le réseau de détection d'objets est entraîné sur les données annotées jusqu'à ce qu'il puisse trouver des régions dans les images qui correspondent à chaque type d'objet.
Regardons maintenant quelques architectures de réseaux neuronaux de détection d'objets.
Le modèle d'apprentissage en profondeur R-CNN



Le Convolutional basé sur la région. Le réseau neuronal (R-CNN) a été proposé par des chercheurs en IA de l'Université de Californie à Berkley, en 2014. Le R-CNN est composé de trois composants clés.
Premièrement, un sélecteur de région utilise la « recherche sélective, ” qui trouve des régions de pixels dans l'image qui pourraient représenter des objets, également appelées « régions d'intérêt » (RoI). Le sélecteur de région génère environ 2 000 régions d'intérêt pour chaque image.
Ensuite, les RoI sont déformées dans une taille prédéfinie et transmises à un réseau de neurones convolutifs. Le CNN traite chaque région séparément et extrait les caractéristiques via une série d'opérations de convolution. Le CNN utilise des couches entièrement connectées pour coder les cartes de caractéristiques dans un vecteur unidimensionnel de valeurs numériques.
Enfin, un modèle d'apprentissage automatique de classificateur mappe les caractéristiques codées obtenues à partir du CNN vers les classes de sortie. Le classificateur a une classe de sortie distincte pour « l'arrière-plan », qui correspond à tout ce qui n'est pas un objet.
R-CNN souffre de quelques problèmes. Tout d'abord, le modèle doit générer et recadrer 2 000 régions distinctes pour chaque image, ce qui peut prendre un certain temps. Deuxièmement, le modèle doit calculer séparément les caractéristiques de chacune des 2 000 régions. Cela représente beaucoup de calculs et ralentit le processus, rendant R-CNN inadapté à la détection d'objets en temps réel. Et enfin, le modèle est composé de trois composants distincts, ce qui rend difficile l'intégration des calculs et l'amélioration de la vitesse.
Fast R-CNN



En 2015, l'auteur principal du L'article de R-CNN a proposé une nouvelle architecture appelée Fast R-CNNqui a résolu certains des problèmes de son prédécesseur. Fast R-CNN apporte l'extraction de caractéristiques et la sélection de régions dans un seul modèle d'apprentissage automatique.
Fast R-CNN reçoit une image et un ensemble de RoI et renvoie une liste de cadres de délimitation et de classes des objets détectés dans l'image.[19659003] L'une des innovations clés de Fast R-CNN était la « couche de mise en commun RoI », une opération qui prend des cartes de caractéristiques CNN et des régions d'intérêt pour une image et fournit les caractéristiques correspondantes pour chaque région. Cela a permis à Fast R-CNN d'extraire les caractéristiques de toutes les régions d'intérêt de l'image en un seul passage, contrairement à R-CNN, qui traitait chaque région séparément. Cela s'est traduit par une augmentation significative de la vitesse.
Cependant, un problème restait sans solution. Fast R-CNN nécessitait toujours que les régions de l'image soient extraites et fournies comme entrée au modèle. Fast R-CNN n'était toujours pas prêt pour la détection d'objets en temps réel.
Faster R-CNN
[faster r-cnn architecture]

Faster R-CNNintroduit en 2016, résout la pièce finale du puzzle de détection d'objets en intégrant le mécanisme d'extraction de région dans le réseau de détection d'objets.
Faster R-CNN prend une image en entrée et renvoie une liste de classes d'objets et leurs cadres de délimitation correspondants.
L'architecture de Faster R-CNN est en grande partie similaire à celui de Fast R-CNN. Sa principale innovation est le « réseau de proposition de région » (RPN), un composant qui prend les cartes de caractéristiques produites par un réseau de neurones convolutifs et propose un ensemble de cadres de délimitation où les objets peuvent être localisés. Les régions proposées sont ensuite transmises à la couche de pooling RoI. Le reste du processus est similaire à Fast R-CNN.
En intégrant la détection de région dans l'architecture principale du réseau neuronal, Faster R-CNN atteint une vitesse de détection d'objets en temps quasi réel.
YOLO

En 2016, des chercheurs de l'Université de Washington, de l'Allen Institute for AI et de Facebook AI Research ont proposé « You Only Look Once » (YOLO), une famille de réseaux de neurones qui a amélioré la vitesse et la précision de détection d'objets avec apprentissage en profondeur.
La principale amélioration de YOLO est l'intégration de l'ensemble du processus de détection et de classification d'objets dans un seul réseau. Au lieu d'extraire les caractéristiques et les régions séparément, YOLO exécute tout en un seul passage via un seul réseau, d'où le nom "You Only Look Once". – inférence temporelle.
Au cours des dernières années, la détection d'objets d'apprentissage en profondeur a parcouru un long chemin, passant d'un patchwork de différents composants à un seul réseau de neurones qui fonctionne efficacement. Aujourd'hui, de nombreuses applications utilisent les réseaux de détection d'objets comme l'un de leurs principaux composants. Il se trouve dans votre téléphone, votre ordinateur, votre voiture, votre appareil photo, etc. Il sera intéressant (et peut-être effrayant) de voir ce qui peut être réalisé avec des réseaux de neurones de plus en plus avancés.
Cet article a été initialement publié par Ben Dickson sur TechTalksune publication qui examine les tendances technologiques, comment ils affectent notre façon de vivre et de faire des affaires, et les problèmes qu'ils résolvent. Mais nous discutons également du côté pervers de la technologie, des implications plus sombres des nouvelles technologies et de ce que nous devons rechercher. Vous pouvez lire l'article original ici.
Source link