

À propos de l'auteur
Doctorat en intelligence artificielle à l'Université de Californie à Berkeley, axé sur les petits réseaux neuronaux dans la perception, pour les véhicules autonomes. Grand fan de cheesecake, corgis et…
Pour en savoir plus sur Alvin …
Quels sont les principes fondamentaux de l'apprentissage automatique et quels sont les outils nécessaires pour évaluer les risques et autres problèmes dans une application d'apprentissage automatique? Cet article couvre tout ce dont vous avez besoin pour commencer.



Le but de l'apprentissage automatique est de trouver des modèles dans les données et d'utiliser ces modèles pour faire des prédictions. Il peut également nous fournir un cadre pour discuter des problèmes et des solutions d’apprentissage automatique, comme vous le verrez dans cet article.
Tout d’abord, nous commencerons par les définitions et les applications pour l’apprentissage automatique. Nous discuterons ensuite des abstractions dans l’apprentissage automatique et nous les utiliserons pour encadrer notre discussion: données, modèles, modèles d’optimisation et algorithmes d’optimisation. Dans la suite de l'article, nous aborderons des sujets fondamentaux qui sous-tendent toutes les méthodes d'apprentissage automatique et nous conclurons par des conseils pratiques pour commencer à utiliser l'apprentissage automatique. À la fin, vous devez comprendre comment faire progresser votre pratique et étudier l'apprentissage automatique.
Commençons.
Alors, qu'est-ce que l'apprentissage automatique?
L'apprentissage automatique est un ensemble de techniques pour trouver des modèles dans les données. Les applications vont des voitures autonomes aux assistants personnels d'IA, de la traduction entre français et taïwanais à la traduction entre voix et texte. Il existe quelques applications courantes de l'apprentissage automatique qui imprègnent ou pourraient affecter votre quotidien.
- Détecter les anomalies
Reconnaître les pics de trafic sur le site Web ou mettre en évidence une activité bancaire anormale. - Recommander un contenu similaire
Trouvez des produits que vous recherchez ou même des articles de Smashing Magazine pertinents. - Prédisez l'avenir
Planifiez le chemin des véhicules voisins ou identifiez et extrapolez les tendances du marché pour les stocks.
de l'apprentissage automatique, mais la plupart des applications renvoient à l'apprentissage de la distribution sous-jacente des données. Une distribution spécifie les événements et les probabilités de chaque événement. Par exemple:
- Avec une probabilité de 50%, vous achetez un article de 5 $ ou moins.
- Avec une probabilité de 25%, vous achetez un article de 5 $ à 10 $.
- Avec une probabilité de 24%, vous achetez un article de 10-100 $
- Avec une probabilité de 1%, vous achetez un article> 100 $.
En utilisant cette distribution, nous pouvons accomplir toutes nos tâches ci-dessus:
- Détecter les anomalies
Avec un achat de 100 $, nous pouvons appeler cela une anomalie - Recommander un contenu similaire
Un achat de 3 $ - Prédire l'avenir
Sans aucune information préalable, nous pouvons prédire que le prochain achat sera de 5 $ ou moins.
Avec une distribution de données, nous pouvons accomplir un une multitude de tâches. En résumé, l'un des objectifs de l'apprentissage automatique est d'apprendre cette distribution.
Encore plus génériquement, notre objectif est d'apprendre une fonction spécifique avec des entrées et des sorties particulières. Nous appelons cette fonction notre modèle . Notre contribution est notée x . Supposons que notre modèle, qui accepte l’entrée x est
f (x) = ax
Ici, a est un paramètre de notre modèle. Chaque paramètre correspond à une instance différente de notre modèle. En d'autres termes, le modèle où a = 2 est différent du modèle où a = 3 . Dans l'apprentissage automatique, notre objectif est d'apprendre ce paramètre, en le modifiant jusqu'à ce que nous fassions «bien». Comment déterminer quelles valeurs de a font «bien»?
évaluer notre modèle, pour chaque paramètre a . Pour commencer, le résultat de f (x) est notre prédiction . Nous nous référerons à et sous notre étiquette ce qui signifie la sortie réelle et souhaitée. Avec nos prédictions et nos étiquettes, nous pouvons définir une fonction de perte . Une telle fonction de perte est simplement la différence entre notre prédiction et notre étiquette, | f (x) - y | . En utilisant cette fonction de perte, nous pouvons alors évaluer différents paramètres pour notre modèle. Choisir le meilleur paramètre pour notre modèle est connu sous le nom de training . Si nous avons quelques paramètres possibles, nous pouvons simplement essayer chaque paramètre et choisir celui qui présente le moins de pertes!
Cependant, la plupart des problèmes ne sont pas aussi simples. Que se passe-t-il s'il existe un nombre infini de paramètres différents? Disons toutes les valeurs décimales comprises entre 0 et 1? Entre 0 et l'infini? Cela nous amène à notre prochain sujet: les abstractions dans l'apprentissage automatique. Nous discuterons des différentes facettes de l’apprentissage automatique afin de compartimenter vos connaissances en données, modèles, objectifs et méthodes de résolution des objectifs. Au-delà de l'apprentissage du bon paramètre, il existe de nombreux autres défis: comment résoudre un problème aussi complexe que le contrôle d'un robot? Comment contrôlons-nous une voiture autonome? Que signifie former un modèle qui identifie les visages? La section ci-dessous vous aidera à organiser les réponses à ces questions.
Abstractions
Il existe d'innombrables sujets dans l'apprentissage automatique – à différents niveaux de spécificité. Pour mieux comprendre où chaque pièce s’inscrit dans une image plus large, considérez les abstractions suivantes pour l’apprentissage automatique. Ces abstractions cloisonnent notre discussion sur les sujets d’apprentissage automatique, et leur connaissance facilitera l’élaboration de sujets. Les classifications suivantes sont tirées du Professeur Jonathan Shewchuck à UC Berkeley:
- Application and Data
Examinez les entrées possibles et le résultat souhaité pour le problème.
Questions : Quel est votre objectif? Comment sont structurées vos données? Y a-t-il des étiquettes? Est-il raisonnable pour nous d'extraire la sortie des entrées fournies?
Exemple : Le but est de classer des images de chiffres manuscrits. L'entrée est une image d'un numéro manuscrit. La sortie est un nombre.
- Modèle
Déterminer la classe de fonctions considérée.
Questions : Les fonctions linéaires sont-elles suffisantes? Fonctions quadratiques? Polynômes? Quels types de motifs nous intéressent? Les réseaux de neurones sont-ils appropriés? Régression logistique?
Exemple : Régression linéaire
- Problème d'optimisation
Formuler un objectif concret en mathématiques.
Questions : Comment définit-on la perte? Comment définit-on le succès? Devrions-nous appliquer des pénalités supplémentaires pour biaiser notre algorithme? Existe-t-il des déséquilibres dans les données que notre objectif doit prendre en compte?
Exemple : Trouver `x` qui minimise
| Ax-b | ^ 2 - Algorithme d'optimisation
Déterminez comment va résoudre le problème de l'optimisation.
Questions : Peut-on calculer une solution à la main? Avons-nous besoin d’un algorithme itératif? Pouvons-nous convertir ce problème en un objectif équivalent mais plus facile à résoudre et résoudre celui-ci?
Exemple : Prenez la dérivée de la fonction. Réglez-le à zéro. Résolvez pour notre paramètre optimal.
Abstraction 1: Data
En pratique, la collecte, la gestion et le conditionnement des données représentent 90% de la bataille. Les données contiennent des échantillons dans lesquels chaque échantillon est une réalisation spécifique de notre entrée. Par exemple, notre entrée peut être de manière générale des images de chiens. Le premier échantillon est spécifiquement une photo de Maxie, mon mélange de chien-chow chow bernois à la maison. Le deuxième exemple est spécifiquement une photo de Charlie, un jeune corgi.
Lors de la formation de votre modèle, il est important de gérer vos données correctement. Cela signifie qu'il faut séparer nos données en conséquence et ne pas consulter prématurément un ensemble de données. En général, nos données sont divisées en trois parties:
- Ensemble de formation
Il s’agit du jeu de données sur lequel vous formez votre modèle. Le modèle peut voir cet ensemble des centaines de fois. - Ensemble de validation
C'est le jeu de données sur lequel vous évaluez votre modèle, pour évaluer la précision et ajuster votre modèle ou méthode en conséquence. - Test set
ensemble de données sur lequel vous évaluez pour évaluer la précision, une fois à la toute fin. Exécuter le test prématurément peut signifier que votre modèle est trop adapté à l'ensemble de test, donc ne courez qu'une seule fois. Nous aborderons plus en détail la notion de «suréquipement» ci-dessous.
Abstraction 2: Models
Les méthodes d'apprentissage automatique sont divisées en deux:
Apprentissage supervisé
En apprentissage supervisé, notre algorithme a accès pour étiqueter les données. Cependant, nous explorons les deux classes de problèmes suivantes:
- Classification
Déterminer laquelle deskclasses{C_1, C_2, ... C_k}à laquelle chaque échantillon appartient, par exemple "Quelle race de chien est-ce?" Le chien pourrait être l'un de{"corgi", "chien de montagne bernois", "chow chow" ...} - Régression
Déterminer une sortie à valeur réelle (qui sont souvent des probabilités), par exemple «Quelle est la probabilité que ce patient souffre d'un neuroblastome (cancer de l'œil)?»
Apprentissage non supervisé
Dans l'apprentissage non supervisé, notre algorithme n'a pas accès aux étiquettes et nous explorons les classes de problèmes suivantes:
- ] Regroupement
Échantillons en grappes dans des grappes dek. Nous n'avons pas d'étiquette pour les grappes résultantes. "Quelles séquences d'ADN sont les plus similaires?" - Réduction de dimensionnalité
Réduit le nombre de caractéristiques "uniques" (linéairement indépendantes) que nous considérons. «Quelles sont les caractéristiques communes des faces? Les moindres carrés sont l'exemple canonique. Nous limiterons notre attention à une forme spécifique des moindres carrés: Revenons à notre problème de scolarisation d'une droite en quelques points.Rappelons l'équation d'une ligne:
y = m * x + bSupposons que nous ayons une telle ligne. C'est le véritable modèle sous-jacent.

True model. La ligne qui génère nos données. ( Grand aperçu )
Maintenant, des points d'échantillonnage de cette ligne.

True data. Données échantillonnées à partir du vrai modèle. ( Grand aperçu )
Pour chaque point, secouez-le un peu. En d'autres termes, ajouter bruit ce qui correspond à des perturbations aléatoires. Ce bruit est dû à des processus réels.

Noise. Des perturbations réelles qui affectent nos données. Cela peut être dû à une imprécision des mesures, à une compression avec perte, etc. ( Grand aperçu )
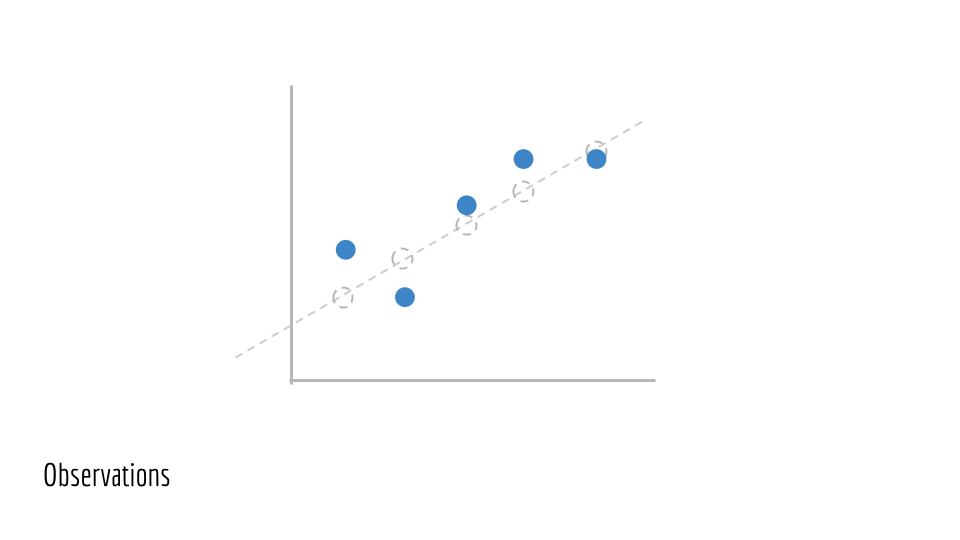
Ceci nous donne nos données observées . Nous appellerons ces points
(x_1, y_1), (x_2, y_2), (x_3, y_3) .... Ce sont les données de formation qui nous sont données pour former un modèle. Nous n'avons pas accès à la ligne sous-jacente qui a généré ces données (la ligne verte d'origine).

Observations. Nos vraies données avec le bruit et finalement ce que nous allons utiliser pour former un modèle. ( Grand aperçu )
Disons que nous avons une estimation pour les paramètres d'une ligne. Dans ce cas, les paramètres sont
metb. Cela nous donne une ligne prédite, dessinée en bleu ci-dessous.

Modèle proposé. Le résultat de l'entraînement d'un modèle sur nos observations. ( Grand aperçu )
Nous souhaitons évaluer notre ligne bleue pour voir si elle est précise. Pour commencer, nous utilisons
metbpour estimeret. Nous calculons un ensemble de valeurs[1945.ŷ_i = m * x_i + bL'erreur pour une seule prédite
ŷ_iet vraiey_iest simplement(ŷ_i − y_i) ^ 2Notre erreur totale est alors la somme des différences au carré, pour tous les échantillons. Cela nous donne notre perte.
∑ (ŷ_i − y_i) ^ 2Présentée visuellement, il s'agit de la distance verticale entre nos points observés et notre ligne prédite.

Erreur observée. La distance entre nos données observées et notre modèle proposé. ( Grand aperçu )
En branchant
ŷ_id'en haut, nous avons alors l'erreur totale en termes demetb.∑ (m * x_i + b - y_i) ^ 2Enfin, nous voulons minimiser cette quantité. Cela donne notre fonction objective abstraction 3 de notre liste d'abstractions ci-dessus.
min_ {m, b} m (m * x_i + b-y_i) ^ 2En mathématiques, il est dit ci-dessus que l'objectif est de minimiser les pertes en changeant les valeurs de
metb. Le but de cette section était de motiver l'ajustement d'une ligne de meilleur ajustement, un cas particulier des moindres carrés . De plus, nous avons montré l'objectif de des moindres carrés . Ensuite, nous devons résoudre cet objectif.Abstraction 4: algorithme d'optimisation
Comment minimiser cela? Nous prenons la dérivée par rapport à
m`, mis à 0 et résolvons. Après résolution, nous obtenons la solution analytique. La solution pour une solution analytique était notre algorithme d'optimisation la quatrième et dernière abstraction de notre liste d'abstractions.Note : La partie importante de cette section est d'informer vous, les moindres carrés, avez une solution de forme fermée, ce qui signifie que la solution optimale pour notre problème peut être calculée, explicitement. Pour comprendre pourquoi cela est important, nous devons examiner un problème sans solution fermée. Par exemple, nous ne pourrions jamais résoudre
x = logxpour un logarithme en base 10 standard. Essayez de représenter graphiquement ces deux lignes, et nous voyons qu'elles ne se croisent jamais. Dans ce cas, nous n'avons pas de solution fermée. Par contre, les moindres carrés ordinaires ont une forme fermée, ce qui est une bonne nouvelle. Pour tout problème réduit aux moindres carrés, nous pouvons alors calculer la solution optimale, compte tenu de nos données et de nos hypothèses.Sujets fondamentaux
Avant d'étudier plus de méthodes, il est nécessaire de comprendre les courants de l'apprentissage automatique. Celles-ci régiront l’étude initiale de l’apprentissage automatique:
Compromis de variance de biais
Un des maux les plus redoutés de l’apprentissage automatique où un modèle est trop étroitement adapté aux données de formation. À la limite, le modèle le plus adapté mémorisera les données. Cela pourrait signifier que si l’on réussit bien à l’examen A, on répète tous les détails de l’examen B – jusqu’à la durée du séjour entre deux examens et si l’urinoir est utilisé ou non.
sous-ajusté où le modèle n'est pas suffisamment expressif pour saisir des informations importantes dans les données. Cela pourrait signifier que l'on ne regarde que les notes de devoirs pour prédire les scores aux examens, en ignorant les effets de la lecture des notes, en passant des examens de pratique, etc. Notre objectif est de construire un modèle généralisant de nouveaux exemples tout en faisant les distinctions appropriées.
Compte tenu de ces deux maux, il existe diverses approches pour lutter contre les deux. On modifie votre objectif d'optimisation pour inclure un terme qui pénalise la complexité du modèle. Un autre est le réglage des hyperparamètres qui régissent soit votre objectif, soit votre algorithme, ce qui peut correspondre à des notions telles que «vitesse d'entraînement» ou «momentum». Le compromis biais-variance
Estimation du maximum de vraisemblance (MLE) + Maximum A Postérieur (MAP)
Disons que nous avons les arômes de crème glacée A, B et C. Nous observons différentes recettes. Notre objectif est de prédire quelle saveur produit chaque recette.
Une façon de prédire les saveurs à partir de recettes consiste à estimer d'abord la probabilité suivante:
P (saveur | recette)Compte tenu de cette probabilité et d'une nouvelle recette, comment pouvons-nous prédire la saveur? Compte tenu d'une recette, considérez simplement la probabilité de chacun des arômes A, B, C.
P (flaveur = A | recette) = 0,4 P (saveur = B | recette) = 0,5 P (saveur = C | recette) = 0,1Ensuite, choisissez la saveur qui a la plus forte probabilité. Au-dessus, la saveur B a la probabilité la plus élevée, compte tenu de notre recette. Ainsi, nous prédisons la saveur B. En reprenant la règle ci-dessus en mathématiques, nous avons:
argmax_ {saveur} P (flavour | recette) # argmax signifie prendre la saveur qui correspond à la valeur maximaleCependant, la seule information à notre disposition est l'inverse: la probabilité qu'une recette donne la saveur.
P (recette | saveur)Pour les estimations de vraisemblance maximale, nous faisons des hypothèses et trouvons que les deux valeurs sont proportionnelles.
P (recette | saveur) ~ P (saveur | recette)Comme nous ne nous intéressons qu'à la classe avec la probabilité maximale
P (flavour | recipe)nous pouvons simplement trouver la classe avec une probabilité maximale, pour une valeur proportionnelleP (recette | saveur ).argmax_ {saveur} P (recette | saveur)MLE offre l'objectif ci-dessus comme moyen de prédire, en utilisant la probabilité de données pour les étiquettes.
Cependant, permettez-moi de vous convaincre qu'il est raisonnable de supposer que nous avons
(x | y). Nous pouvons estimer cela à partir de données réelles observées. Par exemple, disons que nous souhaitons estimer le nombre de billes que chaque élève de votre classe transporte, en fonction du nombre de canards en caoutchouc qu'il porte.Le nombre de canards en caoutchouc de chaque élève est la donnée
xet le nombre de billes qu'elle a est y. Nous utiliserons ces exemples de données ci-dessous.| x | y | | --- | --- | | 1 | 2 | | 1 | 1 | | 1 | 2 | | 2 | 1 | | 2 | 2 | | 1 | 2 |Pour chaque
etnous pouvons calculer le nombre dexP (x | y). Pour le premier,P (x = 1 | y = 1)considérons toutes les lignes oùy = 1. Il y en a 2, et un seul ax = 1. Par conséquent,P (x = 1 | y = 1) = 1 ⁄ 2. Nous pouvons le répéter pour toutes les valeurs dexetet.P (x = 1 | y = 1) = 1/2 P (x = 2 | y = 1) = 1/2 P (x = 1 | y = 2) = 3/4 P (x = 2 | y = 2) = 1/4Featurizations, Regularization
Les moindres carrés dessinent des lignes de meilleur ajustement pour nous. Notez que les moindres carrés peuvent correspondre au modèle chaque fois que le modèle est linéaire dans ses entrées
xet sortieset.Say
m = 1. Nous avons l'équation suivante:y = x + bCependant, si nous disposions de données qui ne suivent généralement pas une ligne? Spécifiquement, considérons un ensemble de données échantillonnées le long d’un cercle. Rappelons que l’équation pour un cercle est:
x ^ 2 + y ^ 2 = r ^ 2Les moindres carrés peuvent-ils convenir? En l'état, non. Le modèle est non linéaire dans ses entrées
xet sortieset. Au lieu de cela, le modèle ci-dessus est quadratique dansxetet. Cependant, il s'avère que nous pouvons utiliser toujours utiliser les moindres carrés, simplement avec une modification. Pour ce faire, nous caractérisons nos échantillons .Considérez ce qui suit: que se passerait-il si
x_ = x ^ety_ = y ^ 2? Ensuite, notre modèle essaie d’apprendre le modèle suivant.x_ + y_ = r ^ 2Est-ce linéaire dans la saisie du modèle
x_et sortiey_? Oui. Notez la subtilité. Le modèle actuel est encore quadratique dansxetmais il est linéaire dansx_et. Cela signifie que les moindres carrés peuvent correspondre aux données si on carréx ^ 2ety ^ 2avant les moindres carrés d'entraînement.Plus généralement, on peut prendre n'importe quelle featurization non linéaire appliquer les moindres carrés aux étiquettes non linéaires dans les entités. Il s'agit d'un outil assez puissant, connu sous le nom de featurization .
Cependant, les fonctionnalités conduisent à des modèles plus complexes. La régularisation nous permet de pénaliser la complexité du modèle, en veillant à ne pas surdimensionner les données de formation. En utilisant les abstractions ci-dessus, vous avez maintenant un cadre pour discuter des problèmes et des solutions d'apprentissage automatique. En utilisant les thèmes fondamentaux ci-dessus, vous avez maintenant des concepts essentiels pour en apprendre davantage, vous donnant les outils nécessaires pour évaluer les risques et autres problèmes dans une application d'apprentissage automatique.
Lectures supplémentaires
la profondeur, à la fois les sous-courants de l'apprentissage automatique et les méthodes spécifiques. Dans l'intervalle, voici des ressources pour approfondir votre étude et votre exploration de l'apprentissage automatique:







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Source link