







Dans cet article, nous allons apprendre le concept des génériques dans TypeScript et examiner comment les génériques peuvent être utilisés pour écrire de manière modulaire, découplée et réutilisable code. En cours de route, nous discuterons brièvement de la manière dont ils s'intègrent dans de meilleurs modèles de test, des approches de gestion des erreurs et une séparation domaine / accès aux données.
Un exemple concret
Je veux entrer dans le monde des génériques non en expliquant ce qu'ils sont, mais plutôt en donnant un exemple intuitif de leur utilité. Supposons que vous ayez été chargé de créer une liste dynamique riche en fonctionnalités. Vous pouvez l'appeler un tableau, une ArrayList une List une std :: vector ou autre, selon votre langue. Peut-être que cette structure de données doit également avoir des systèmes de tampons intégrés ou échangeables (comme une option d'insertion de tampon circulaire). Ce sera un wrapper autour du tableau JavaScript normal afin que nous puissions travailler avec notre structure au lieu de tableaux simples.
Le problème immédiat que vous rencontrerez est celui des contraintes imposées par le système de types. Vous ne pouvez pas, à ce stade, accepter le type de votre choix dans une fonction ou une méthode d'une manière claire et nette (nous reviendrons sur cette déclaration plus tard).
La seule solution évidente est de répliquer notre structure de données pour tous les différents types:
const intList = IntegerList.create ();
intList.add (4);
const stringList = StringList.create ();
stringList.add ('bonjour');
const userList = UserList.create ();
userList.add (new User ('Jamie')); La syntaxe .create () ici pourrait sembler arbitraire, et en effet, new SomethingList () serait plus simple -forward, mais vous verrez pourquoi nous utilisons cette méthode de fabrique statique plus tard. En interne, la méthode create appelle le constructeur.
C'est terrible. Nous avons beaucoup de logique dans cette structure de collection, et nous la dupliquons de manière flagrante pour prendre en charge différents cas d'utilisation, brisant complètement le principe DRY dans le processus. Lorsque nous décidons de modifier notre implémentation, nous devrons propager / refléter manuellement ces modifications dans toutes les structures et tous les types que nous prenons en charge, y compris les types définis par l'utilisateur, comme dans le dernier exemple ci-dessus. Supposons que la structure de la collection elle-même fasse 100 lignes – ce serait un cauchemar de maintenir plusieurs implémentations différentes où la seule différence entre elles est les types.
Une solution immédiate qui pourrait vous venir à l'esprit, surtout si vous avez un état d'esprit POO, est d'envisager un «supertype» racine si vous voulez. En C #, par exemple, il s'agit d'un type portant le nom de object et object est un alias pour la classe System.Object . Dans le système de types de C #, tous les types, qu’ils soient prédéfinis ou définis par l’utilisateur, qu’il s’agisse de types de référence ou de types de valeur, héritent directement ou indirectement de System.Object . Cela signifie que n'importe quelle valeur peut être assignée à une variable de type object (sans entrer dans la sémantique stack / heap et boxing / unboxing).
Dans ce cas, notre problème semble résolu. Nous pouvons simplement utiliser un type comme any et cela nous permettra de stocker tout ce que nous voulons dans notre collection sans avoir à dupliquer la structure, et en effet, c'est très vrai:
const intList = AnyList.create ();
intList.add (4);
const stringList = AnyList.create ();
stringList.add ('bonjour');
const userList = AnyList.create ();
userList.add (new User ('Jamie')); Regardons l'implémentation réelle de notre liste en utilisant any :
class AnyList {
valeurs privées: toutes [] = [];
constructeur privé (valeurs: any []) {
this.values = valeurs;
// Encore des travaux de construction.
}
public add (value: any): void {
this.values.push (valeur);
}
public where (predicate: (value: any) => boolean): AnyList {
return AnyList.from (this.values.filter (prédicat));
}
public select (selector: (value: any) => any): AnyList {
return AnyList.from (this.values.map (sélecteur));
}
public toArray (): any [] {
renvoyer this.values;
}
public static from (values: any []): AnyList {
// Peut-être que nous exécutons une logique ici.
// ...
return new AnyList (valeurs);
}
public static create (values?: any []): AnyList {
return new AnyList (valeurs ?? []);
}
// Autres fonctions de collecte.
// ...
} Toutes les méthodes sont relativement simples, mais nous allons commencer par le constructeur. Sa visibilité est privée, car nous supposerons que notre liste est complexe et nous souhaitons interdire la construction arbitraire. Nous pouvons aussi vouloir exécuter la logique avant la construction, donc pour ces raisons, et pour garder le constructeur pur, nous déléguons ces préoccupations aux méthodes statiques d'usine / auxiliaires, ce qui est considéré comme une bonne pratique.
The static methods de et create sont fournis. La méthode de accepte un tableau de valeurs, exécute une logique personnalisée, puis les utilise pour construire la liste. La méthode statique create prend un tableau optionnel de valeurs pour dans le cas où nous voulons amorcer notre liste avec les données initiales. L '«opérateur de fusion nul» ( ?? ) est utilisé pour construire la liste avec un tableau vide dans le cas où il n'en est pas fourni. Si le côté gauche de l'opérande est nul ou undefined nous retomberons sur le côté droit, car dans ce cas, valeurs est facultative, et ainsi peut être indéfini . Pour en savoir plus sur la fusion nullish, consultez la page de documentation TypeScript appropriée .
J'ai également ajouté une méthode select et une where méthode. Ces méthodes ne font qu’envelopper la carte de JavaScript et le filtre respectivement. select nous permet de projeter un tableau d'éléments dans une nouvelle forme basée sur la fonction de sélection fournie, et où nous permet de filtrer certains éléments en fonction de la fonction de prédicat fournie. La méthode toArray convertit simplement la liste en tableau en renvoyant la référence de tableau que nous détenons en interne.
Enfin, supposons que la classe User contienne un getName qui renvoie un nom et accepte également un nom comme premier et unique argument de constructeur.
Remarque: Certains lecteurs reconnaîtront
OùetSélectionnezdans LINQ de C #, mais gardez à l'esprit que j'essaie de garder cela simple, donc je ne suis pas inquiet de la paresse ou du report d'exécution. Ce sont des optimisations qui pourraient et devraient être faites dans la vie réelle.De plus, à titre intéressant, je veux discuter de la signification de «prédicat». En Mathématiques Discrètes et Logique Propositionnelle, nous avons le concept de «proposition». Une proposition est une déclaration qui peut être considérée comme vraie ou fausse, telle que «quatre est divisible par deux». Un «prédicat» est une proposition qui contient une ou plusieurs variables, ainsi la véracité de la proposition dépend de celle de ces variables. Vous pouvez y penser comme une fonction, telle que
P (x) = x est divisible par deuxcar nous avons besoin de connaître la valeur dexpour déterminer si l'énoncé est vrai ou fausses. Vous pouvez en savoir plus sur la logique des prédicats ici .
Il y a quelques problèmes qui vont surgir de l'utilisation de any . Le compilateur TypeScript ne sait rien des éléments à l'intérieur de la liste / tableau interne, il ne fournira donc aucune aide à l'intérieur de où ou sélectionnez ou lors de l'ajout d'éléments:
// Fournir des données de départ.
const userList = AnyList.create ([new User('Jamie')]);
// C'est bien et attendu.
userList.add (nouvel utilisateur ('Tom'));
userList.add (nouvel utilisateur ('Alice'));
// Ceci est une entrée acceptable pour le compilateur TS,
// mais ce n'est pas ce que nous voulons. Nous allons certainement
// être surpris plus tard de trouver des chaînes dans une liste
// des utilisateurs.
userList.add ('Bonjour le monde!');
// Aussi acceptable. Nous avons un grand tuple
// à ce stade plutôt qu'un tableau homogène.
userList.add (0);
// Cela compile très bien malgré l'erreur d'orthographe (extra 's'):
// Le type d '«utilisateurs» est any.
const users = userList.where (utilisateur => user.getNames () === 'Jamie');
// La propriété `ssn` n'existe même pas sur un` utilisateur`, mais elle se compile.
users.toArray () [0] .ssn = '000000000';
// `usersWithId` est, encore une fois, juste` any`.
const usersWithId = userList.select (utilisateur => ({
id: newUuid (),
nom: user.getName ()
}));
// Oups, c'est "id" et non "ID", mais TS ne nous aide pas.
// Nous compilons très bien.
console.log (usersWithId.toArray () [0] .ID); Puisque TypeScript sait seulement que le type de tous les éléments du tableau est any il ne peut pas nous aider au moment de la compilation avec le propriétés inexistantes ou la fonction getNames qui n'existe même pas, donc ce code entraînera de multiples erreurs d'exécution inattendues.
Pour être honnête, les choses commencent à paraître assez lamentables. Nous avons essayé d'implémenter notre structure de données pour chaque type de béton que nous souhaitions prendre en charge, mais nous nous sommes rapidement rendu compte que ce n'était en aucun cas maintenable. Ensuite, nous avons pensé que nous allions quelque part en utilisant any ce qui revient à dépendre d'un supertype racine dans une chaîne d'héritage dont tous les types dérivent, mais nous avons conclu que nous perdons la sécurité de type avec cette méthode. Quelle est la solution alors?
Il s'avère qu'au début de l'article, j'ai menti (en quelque sorte):
«Vous ne pouvez pas, à ce stade, accepter le type que vous voulez dans une fonction ou »
Vous pouvez réellement, et c'est là que les génériques entrent en jeu. Remarquez que j'ai dit« à ce stade », car je supposais que nous ne connaissions pas les génériques à ce stade de l'article. [19659008] Je commencerai par montrer l'implémentation complète de notre structure List avec Generics, puis nous prendrons du recul, discuterons de ce qu'ils sont réellement et déterminerons leur syntaxe de manière plus formelle. Je l'ai nommé TypedList pour le différencier de notre ancien AnyList :
class TypedList {
valeurs privées: T [] = [];
constructeur privé (valeurs: T []) {
this.values = valeurs;
}
public add (valeur: T): void {
this.values.push (valeur);
}
public où (prédicat: (valeur: T) => booléen): TypedList {
return TypedList.from (this.values.filter (prédicat));
}
public select (sélecteur: (valeur: T) => U): TypedList {
return TypedList.from (this.values.map (sélecteur));
}
public toArray (): T [] {
renvoyer this.values;
}
public static from (valeurs: U []): TypedList {
// Peut-être que nous exécutons une logique ici.
// ...
return new TypedList (valeurs);
}
public static create (valeurs?: U []): TypedList {
return new TypedList (valeurs ?? []);
}
// Autres fonctions de collecte.
// ..
} Essayons de refaire les mêmes erreurs que précédemment:
// Voici la magie. `TypedList` fonctionnera sur les objets
// de type ʻUser` en raison de la syntaxe ``.
const userList = TypedList.create ([new User('Jamie')]);
// Le compilateur s'y attend.
userList.add (nouvel utilisateur ('Tom'));
userList.add (nouvel utilisateur ('Alice'));
// L'argument de type '0' n'est pas assignable au paramètre
// de type 'Utilisateur'. ts (2345)
userList.add (0);
// La propriété 'getNames' n'existe pas sur le type 'User'.
// Vouliez-vous dire 'getName'? ts (2551)
// Remarque: TypeScript déduit le type de `utilisateurs` à être
// `TypedList `
const users = userList.where (utilisateur => user.getNames () === 'Jamie');
// La propriété 'ssn' n'existe pas sur le type 'User'. ts (2339)
users.toArray () [0] .ssn = '000000000';
// TypeScript déduit que `usersWithId` est de type
// `TypedList
const usersWithId = userList.select (utilisateur => ({
id: newUuid (),
nom: user.getName ()
}));
// La propriété 'ID' n'existe pas sur le type '{id: string; nom: chaîne; } '.
// Vouliez-vous dire "id"? ts (2551)
console.log (usersWithId.toArray () [0] .ID) Comme vous pouvez le voir, le compilateur TypeScript nous aide activement avec la sécurité de type. Tous ces commentaires sont des erreurs que je reçois du compilateur lors de la tentative de compilation de ce code. Les génériques nous ont permis de spécifier un type sur lequel nous souhaitons permettre à notre liste de fonctionner, et à partir de là, TypeScript peut dire les types de tout, jusqu'aux propriétés des objets individuels dans le tableau.
Les types que nous fournissons peut être aussi simple ou complexe que nous le souhaitons. Ici, vous pouvez voir que nous pouvons passer à la fois des primitives et des interfaces complexes. Nous pourrions également passer d'autres tableaux, classes, ou quoi que ce soit:
const numberList = TypedList.create ();
numberList.add (4);
const stringList = TypedList.create ();
stringList.add ('Bonjour, Monde');
// Exemple de type complexe
interface IAircraft {
apuStatus: ApuStatus;
inboardOneRPM: nombre;
altimètre: nombre;
tcasAlert: booléen;
pushBackAndStart (): Promise ;
ilsCaptureGlidescope (): booléen;
getFuelStats (): IFuelStats;
getTCASHistory (): ITCASHistory;
}
const AircraftList = TypedList.create ();
AircraftList.add (/ * ... * /);
// Agréger et générer un rapport:
const stats = AircraftList.select (a => ({
... a.getFuelStats (),
... a.getTCASHistory ()
})); Les utilisations particulières de T et U et et dans l'implémentation TypedList sont des exemples de génériques en action . Après avoir rempli notre directive de construction d'une structure de collection de type sécurisé, nous laisserons cet exemple derrière nous pour l'instant, et nous y reviendrons une fois que nous aurons compris ce que sont réellement les génériques, comment ils fonctionnent et leur syntaxe. Lorsque j'apprends un nouveau concept, j'aime toujours commencer par voir un exemple complexe du concept utilisé, de sorte que lorsque je commence à apprendre les bases, je puisse faire des liens entre les sujets de base et l'exemple existant que j'ai dans mon head.
Que sont les génériques?
Une manière simple de comprendre les génériques est de les considérer comme relativement analogues aux espaces réservés ou aux variables mais pour les types. Cela ne veut pas dire que vous pouvez effectuer les mêmes opérations sur un espace réservé de type générique que sur une variable, mais une variable de type générique peut être considérée comme un espace réservé qui représente un type concret qui sera utilisé à l'avenir. Autrement dit, l'utilisation de Generics est une méthode d'écriture de programmes en termes de types qui doivent être spécifiés ultérieurement. La raison pour laquelle cela est utile est parce que cela nous permet de construire des structures de données qui sont réutilisables dans les différents types sur lesquels elles opèrent (ou indépendamment du type).
Ce n'est pas particulièrement la meilleure des explications, donc pour le dire plus simplement termes, comme nous l'avons vu, il est courant en programmation que nous puissions avoir besoin de construire une structure de fonction / classe / données qui fonctionnera sur un certain type, mais il est également courant qu'une telle structure de données doit fonctionner sur une variété de différents types également. Si nous étions coincés dans une position où nous devions déclarer statiquement le type concret sur lequel une structure de données fonctionnerait au moment où nous concevons la structure de données (au moment de la compilation), nous trouverions très rapidement que nous devons reconstruire ceux-ci structures de la même manière pour chaque type que nous souhaitons prendre en charge, comme nous l'avons vu dans les exemples ci-dessus.
Les génériques nous aident à résoudre ce problème en nous permettant de reporter l'exigence d'un type concret jusqu'à il est en fait connu.
Génériques dans TypeScript
Nous avons maintenant une idée assez naturelle de l'utilité des génériques et nous en avons vu un exemple un peu compliqué en pratique. Pour la plupart, l'implémentation TypedList a probablement déjà beaucoup de sens, surtout si vous venez d'un contexte linguistique typé statiquement, mais je me souviens avoir eu du mal à comprendre le concept lorsque j'ai commencé à apprendre, donc Je veux construire cet exemple en commençant par des fonctions simples. Les concepts liés à l'abstraction dans les logiciels peuvent être notoirement difficiles à internaliser, donc si la notion de génériques n'a pas encore tout à fait cliqué, c'est tout à fait correct, et j'espère qu'à la fin de cet article, l'idée sera au moins quelque peu intuitive.
To pour pouvoir comprendre cet exemple, travaillons à partir de fonctions simples. Nous commencerons par la «fonction d'identité», qui est ce que la plupart des articles, y compris la documentation TypeScript elle-même, aiment utiliser.
Une «fonction d'identité», en mathématiques, est une fonction qui mappe son entrée directement sur sa sortie , comme f (x) = x . Ce que vous mettez est ce que vous sortez. Nous pouvons représenter cela, en JavaScript, par:
function identity (input) {
entrée de retour;
} Ou, plus simplement:
const identity = input => input; Essayer de porter ceci sur TypeScript ramène les mêmes problèmes de système de type que nous avons vus auparavant. Les solutions sont de taper avec any ce qui, nous le savons, est rarement une bonne idée, de dupliquer / surcharger la fonction pour chaque type (casse DRY), ou d'utiliser Generics.
Avec cette dernière option, nous pouvons représenter la fonction comme suit:
// Fonction ES5
identité de fonction (entrée: T): T {
entrée de retour;
}
// Fonction Flèche
identité const = (entrée: T): T => entrée;
console.log (identité (5)); // 5
console.log (identité ('bonjour')); // bonjour La syntaxe déclare ici cette fonction comme générique. Tout comme une fonction nous permet de passer un paramètre d'entrée arbitraire dans sa liste d'arguments, avec une fonction générique, nous pouvons également passer un paramètre de type arbitraire.
La partie de la signature de identité ] (entrée: T): T et (entrée: T): T dans les deux cas déclare que la fonction en question acceptera un paramètre de type générique nommé T . Tout comme les variables peuvent avoir n'importe quel nom, nos espaces réservés génériques peuvent l'être aussi, mais c'est une convention d'utiliser une lettre majuscule «T» («T» pour «Type») et de descendre dans l'alphabet si nécessaire. Souvenez-vous que T est un type, donc nous déclarons également que nous accepterons un argument de fonction de nom input avec un type de T et que notre fonction retournera un type de T . C’est tout ce que dit la signature. Essayez de laisser T = string dans votre tête – remplacez tous les T s par string dans ces signatures. Vous voyez comment il ne se passe rien de magique? Voyez à quel point il est similaire à la façon non générique dont vous utilisez les fonctions tous les jours?
Gardez à l'esprit ce que vous savez déjà sur TypeScript et les signatures de fonctions. Tout ce que nous disons, c'est que T est un type arbitraire que l'utilisateur fournira lors de l'appel de la fonction, tout comme input est une valeur arbitraire que l'utilisateur fournira lors de l'appel de la fonction . Dans ce cas, input doit être quel que soit le type T lorsque la fonction est appelée dans le futur .
Ensuite, dans le «futur», dans les deux instructions log, nous «passons» le type concret que nous souhaitons utiliser, tout comme nous faisons une variable. Remarquez le changement de verbiage ici – sous la forme initiale de signature lors de la déclaration de notre fonction, elle est générique – c'est-à-dire qu'elle fonctionne sur des types génériques, ou des types à spécifier plus tard. C’est parce que nous ne savons pas quel type l’appelant souhaite utiliser lorsque nous écrivons réellement la fonction. Mais, lorsque l'appelant appelle la fonction, il sait exactement avec quel (s) type (s) il veut travailler, à savoir string et number dans ce cas.
Vous peut imaginer l'idée d'avoir une fonction de journalisation déclarée de cette façon dans une bibliothèque tierce – l'auteur de la bibliothèque n'a aucune idée des types que les développeurs qui utilisent la lib voudront utiliser, donc ils rendent la fonction générique, essentiellement différant le besoin de types concrets jusqu'à ce qu'ils soient réellement connus.
Je tiens à souligner que vous devriez penser à ce processus de la même manière que vous faites la notion de passer une variable à une fonction dans le but d'acquérir une compréhension plus intuitive. Tout ce que nous faisons maintenant, c'est aussi passer un type.
Au moment où nous avons appelé la fonction avec le paramètre number la signature originale, à toutes fins utiles, pourrait être considérée comme identité (entrée: numéro): numéro . Et, au moment où nous avons appelé la fonction avec le paramètre string encore une fois, la signature originale aurait tout aussi bien pu être identity (input: string): string . Vous pouvez imaginer que, lors de l'appel, chaque T générique est remplacé par le type concret que vous fournissez à ce moment-là.
Exploration de la syntaxe générique
Il existe différentes syntaxes et sémantiques pour spécifier des génériques dans le contexte des fonctions ES5, des fonctions fléchées, des alias de type, des interfaces et des classes. Nous allons explorer ces différences dans cette section.
Exploration de la syntaxe générique – Fonctions
Vous avez déjà vu quelques exemples de fonctions génériques, mais il est important de noter qu'une fonction générique peut accepter plus d'un type générique paramètre, tout comme il peut les variables. Vous pouvez choisir d'en demander un, deux ou trois, ou autant de types que vous voulez, tous séparés par des virgules (encore une fois, tout comme les arguments d'entrée).
Cette fonction accepte trois types d'entrée et renvoie l'un d'entre eux au hasard:
fonction randomValue (
un: T,
deux: U,
trois: V
): T | U | V {
// Ceci est un tuple si vous n'êtes pas familier.
Options const: [T, U, V] = [
one,
two,
three
];
const rndNum = getRndNumInInclusiveRange (0, 2);
options de retour [rndNum];
}
// Appel de la fonction.
// `valeur` a le type` chaîne | nombre | IAircraft »
const value = randomValue (
myString,
mon numéro,
monAéronef
); Vous pouvez également voir que la syntaxe est légèrement différente selon que nous utilisons une fonction ES5 ou une fonction flèche, mais les deux déclarent les paramètres de type dans la signature:
const randomValue = (
un: T,
deux: U,
trois: V
): T | U | V => {
// Ceci est un tuple si vous n'êtes pas familier.
Options const: [T, U, V] = [
one,
two,
three
];
const rndNum = getRndNumInInclusiveRange (0, 2);
options de retour [rndNum];
} Gardez à l'esprit qu'aucune «contrainte d'unicité» n'est imposée aux types – vous pouvez passer la combinaison de votre choix, par exemple deux chaînes et un nombre par exemple. De plus, tout comme les arguments d'entrée sont «dans la portée» du corps de la fonction, les paramètres de type générique le sont également. Le premier exemple montre que nous avons un accès complet à T U et V à partir du corps de la fonction, et nous les avons utilisés pour déclarer un local
Vous pouvez imaginer que ces génériques opèrent dans un certain «contexte» ou dans une certaine «durée de vie», et cela dépend de l'endroit où ils sont déclarés. Les génériques sur les fonctions sont dans la portée de la signature et du corps de la fonction (et les fermetures créées par les fonctions imbriquées), tandis que les génériques déclarés sur une classe ou une interface ou un alias de type sont dans la portée de tous les membres de la classe ou de l'interface ou de l'alias de type.
La notion de génériques sur les fonctions ne se limite pas aux «fonctions libres» ou aux «fonctions flottantes» (fonctions non attachées à un objet ou à une classe, un terme C ++), mais elles peuvent également être utilisées sur des fonctions attachées à d'autres structures. [19659008] Nous pouvons placer cette randomValue dans une classe et nous pouvons l'appeler de la même manière:
class Utils {
public randomValue (
un: T,
deux: U,
trois: V
): T | U | V {
// ...
}
// Ou, comme fonction de flèche:
public randomValue = (
un: T,
deux: U,
trois: V
): T | U | V => {
// ...
}
} On pourrait aussi placer une définition dans une interface:
interface IUtils {
randomValue (
un: T,
deux: U,
trois: V
): T | U | V;
} Ou dans un alias de type:
type Utils = {
randomValue (
un: T,
deux: U,
trois: V
): T | U | V;
} Tout comme avant, ces paramètres de type générique sont «dans la portée» de cette fonction particulière – ils ne sont pas de classe, ni d'interface, ni de type à l'échelle de l'alias. Ils ne vivent que dans le cadre de la fonction particulière sur laquelle ils sont spécifiés. Pour partager un type générique entre tous les membres d'une structure, vous devez annoter le nom de la structure lui-même, comme nous le verrons ci-dessous.
Exploration de la syntaxe générique – Alias de type
Avec les alias de type, la syntaxe générique est utilisée sur le
Par exemple, une fonction «action» qui accepte une valeur peut éventuellement muter cette valeur, mais renvoie void pourrait s'écrire comme suit:
type Action = (val: T) => void; Remarque : Cela devrait être familier aux développeurs C # qui comprennent le délégué Action .
Ou, une fonction de rappel qui accepte à la fois une erreur et une valeur pourrait être déclaré comme tel:
type CallbackFunction = (err: Error, data: T) => void;
const usersApi = {
get (uri: string, cb: CallbackFunction ) {
/// ...
}
} Grâce à notre connaissance des génériques de fonction, nous pourrions aller plus loin et rendre la fonction sur l'objet API générique également:
type CallbackFunction = (err: Error, data: T) => void;
const api = {
// `T` est disponible pour une utilisation dans cette fonction.
get (uri: string, cb: CallbackFunction ) {
/// ...
}
} Maintenant, nous disons que la fonction get accepte un paramètre de type générique, et quoi que ce soit, CallbackFunction le reçoit. Nous avons essentiellement «adopté» le T qui entre dans get comme T pour CallbackFunction . Cela aurait peut-être plus de sens si nous changeons les noms:
type CallbackFunction = (err: Error, data: TData) => void;
const api = {
get (uri: string, cb: CallbackFunction ) {
// ...
}
} Le préfixe des paramètres de type avec T est simplement une convention, tout comme le préfixage des interfaces avec I ou des variables membres avec _ . Ce que vous pouvez voir ici, c'est que CallbackFunction accepte un type ( TData ) qui représente la charge de données disponible pour la fonction, tandis que get accepte un paramètre de type qui représente le type / forme de données de réponse HTTP ( TResponse ). Le client HTTP ( api ), similaire à Axios, utilise tout ce que TResponse est comme TData pour CallbackFunction . Cela permet à l'appelant de l'API de sélectionner le type de données qu'il recevra de l'API (supposons que quelque part ailleurs dans le pipeline, nous ayons un middleware qui analyse le JSON en un DTO).
Si nous voulions aller un peu plus loin , nous pourrions modifier les paramètres de type générique sur CallbackFunction pour accepter également un type d'erreur personnalisé:
type CallbackFunction = (err: TError, data: TData) => void; Et, tout comme vous pouvez rendre les arguments de fonction facultatifs, vous pouvez également utiliser des paramètres de type. Dans le cas où l'utilisateur ne fournit pas de type d'erreur, nous le définirons sur le constructeur d'erreur par défaut:
type CallbackFunction = (err: TError, data: TData) => void; Avec cela, nous pouvons maintenant spécifier un type de fonction de rappel de plusieurs manières:
const apiOne = {
// `Error` est utilisé par défaut pour` CallbackFunction`.
get (uri: string, cb: CallbackFunction ) {
// ...
}
};
apiOne.get ('uri', (err: Erreur, données: chaîne) => {
// ...
});
const apiTwo = {
// Remplacez la valeur par défaut et utilisez `HttpError` à la place.
get (uri: string, cb: CallbackFunction ) {
// ...
}
};
apiTwo.get ('uri', (err: HttpError, data: string) => {
// ...
}); Cette idée de paramètres par défaut est acceptable dans toutes les fonctions, classes, interfaces, etc. – elle n’est pas seulement limitée aux alias de type. Dans tous les exemples que nous avons vus jusqu'à présent, nous aurions pu attribuer n'importe quel paramètre de type à une valeur par défaut. Les alias de type, tout comme les fonctions, peuvent prendre autant de paramètres de type générique que vous le souhaitez.
Exploration de la syntaxe générique – Interfaces
Comme vous l'avez vu, un paramètre de type générique peut être fourni à une fonction sur une interface: [19659010] interface IUselessFunctions {
// Pas générique
printHelloWorld ();
// Générique
identité (t: T): T;
}
Dans ce cas, T ne vit que pour la fonction identity comme son entrée et son type de retour.
Nous pouvons également rendre un paramètre de type disponible à tous les membres d'un interface, tout comme avec les classes et les alias de type, en spécifiant que l'interface elle-même accepte un générique. Nous parlerons du Repository Pattern un peu plus tard lorsque nous aborderons des cas d'utilisation plus complexes pour les génériques, donc ce n'est pas grave si vous n'en avez jamais entendu parler. Le modèle de référentiel nous permet d'abstraire notre stockage de données afin de rendre la logique métier indépendante de la persistance. Si vous souhaitez créer une interface de référentiel générique fonctionnant sur des types d'entités inconnus, nous pourrions la taper comme suit:
interface IRepository {
ajouter (entité: T): Promise ;
findById (id: chaîne): Promise ;
updateById (id: string, mis à jour: T): Promise ;
removeById (id: chaîne): Promise ;
} Note : Il existe de nombreuses idées différentes autour des référentiels, de la définition de Martin Fowler à la définition de DDD Aggregate. J'essaie simplement de montrer un cas d'utilisation des génériques, donc je ne suis pas trop soucieux d'être totalement correct en ce qui concerne la mise en œuvre. There’s definitely something to be said for not using generic repositories, but we’ll talk about that later.
As you can see here, IRepository is an interface that contains methods for storing and retrieving data. It operates on some generic type parameter named Tand T is used as input to add and updateByIdas well as the promise resolution result of findById.
Keep in mind that there’s a very big difference between accepting a generic type parameter on the interface name as opposed to allowing each function itself to accept a generic type parameter. The former, as we’ve done here, ensures that each function within the interface operates on the same type T. That is, for an IRepositoryevery method that uses T in the interface is now working on User objects. With the latter method, each function would be allowed to work with whatever type it wants. It would be very peculiar to only be able to add Users to the Repository but be able to receive Policies or Orders back, for instance, which is the potential situation we’d find ourselves in if we couldn’t enforce that the type is uniform across all methods.
A given interface can contain not only a shared type, but also types unique to its members. For instance, if we wanted to mimic an array, we could type an interface like this:
interface IArray {
forEach(func: (elem: T, index: number) => void): this;
map(func: (elem: T, index: number) => U): IArray;
}In this case, both forEach and map have access to T from the interface name. As stated, you can imagine that T is in scope for all members of the interface. Despite that, nothing stops individual functions within from accepting their own type parameters as well. The map function does, with U. Now, map has access to both T and U. We had to name the parameter a different letter, like Ubecause T is already taken and we don’t want a naming collision. Quite like its name, map will “map” elements of type T within the array to new elements of type U. It maps Ts to Us. The return value of this function is the interface itself, now operating on the new type Uso that we can somewhat mimic JavaScript’s fluent chainable syntax for arrays.
We’ll see an example of the power of Generics and Interfaces shortly when we implement the Repository Pattern and discuss Dependency Injection. Once again, we can accept as many generic parameters as well as select one or more default parameters stacked at the end of an interface.
Exploring Generic Syntax — Classes
Much the same as we can pass a generic type parameter to a type alias, function, or interface, we can pass one or more to a class as well. Upon doing so, that type parameter will be accessible to all members of that class as well as extended base classes or implemented interfaces.
Let’s build another collection class, but a little simpler than TypedList above, so that we can see the interop between generic types, interfaces, and members. We’ll see an example of passing a type to a base class and interface inheritance a little later.
Our collection will merely support basic CRUD functions in addition to a map and forEach method.
class Collection {
private elements: T[] = [];
constructor (elements: T[] = []) {
this.elements = elements;
}
add(elem: T): void {
this.elements.push(elem);
}
contains(elem: T): boolean {
return this.elements.includes(elem);
}
remove(elem: T): void {
this.elements = this.elements.filter(existing => existing !== elem);
}
forEach(func: (elem: T, index: number) => void): void {
return this.elements.forEach(func);
}
map(func: (elem: T, index: number) => U): Collection {
return new Collection(this.elements.map(func));
}
}
const stringCollection = new Collection();
stringCollection.add('Hello, World!');
const numberCollection = new Collection();
numberCollection.add(3.14159);
const aircraftCollection = new Collection();
aircraftCollection.add(myAircraft);Let’s discuss what’s going on here. The Collection class accepts one generic type parameter named T. That type becomes accessible to all members of the class. We use it to define a private array of type T[]which we could also have denoted in the form Array (See? Generics again for normal TS array typing). Further, most member functions utilize that T in some way, such as by controlling the types that are added and removed or checking if the collection contains an element.
Finally, as we’ve seen before, the map method requires its own generic type parameter. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U. That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named Uand that’d be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can’t do is have another function that accepts a generic parameter named Tfor that’d conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with strings, numbers, and IAircrafts.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we’ll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let’s define it:
interface ICollection {
add(t: T): void;
contains(t: T): boolean;
remove(t: T): void;
forEach(func: (elem: T, index: number) => void): void;
map(func: (elem: T, index: number) => U): ICollection;
}Now, let’s suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection implements ICollection {
private elements: T[] = [];
constructor (elements: T[] = []) {
this.elements = elements;
}
add(elem: T): void {
this.elements.push(elem);
}
contains(elem: T): boolean {
return this.elements.includes(elem);
}
remove(elem: T): void {
this.elements = this.elements.filter(existing => existing !== elem);
}
forEach(func: (elem: T, index: number) => void): void {
return this.elements.forEach(func);
}
map(func: (elem: T, index: number) => U): ICollection {
return new InMemoryCollection(this.elements.map(func));
}
}The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don’t know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type Tand whatever it is, it’s immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the
// tutorial.
const userCollection: ICollection = new InMemoryCollection();
function manageUsers(userCollection: ICollection) {
userCollection.add(new User());
}With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection (for example) with InMemoryCollection instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
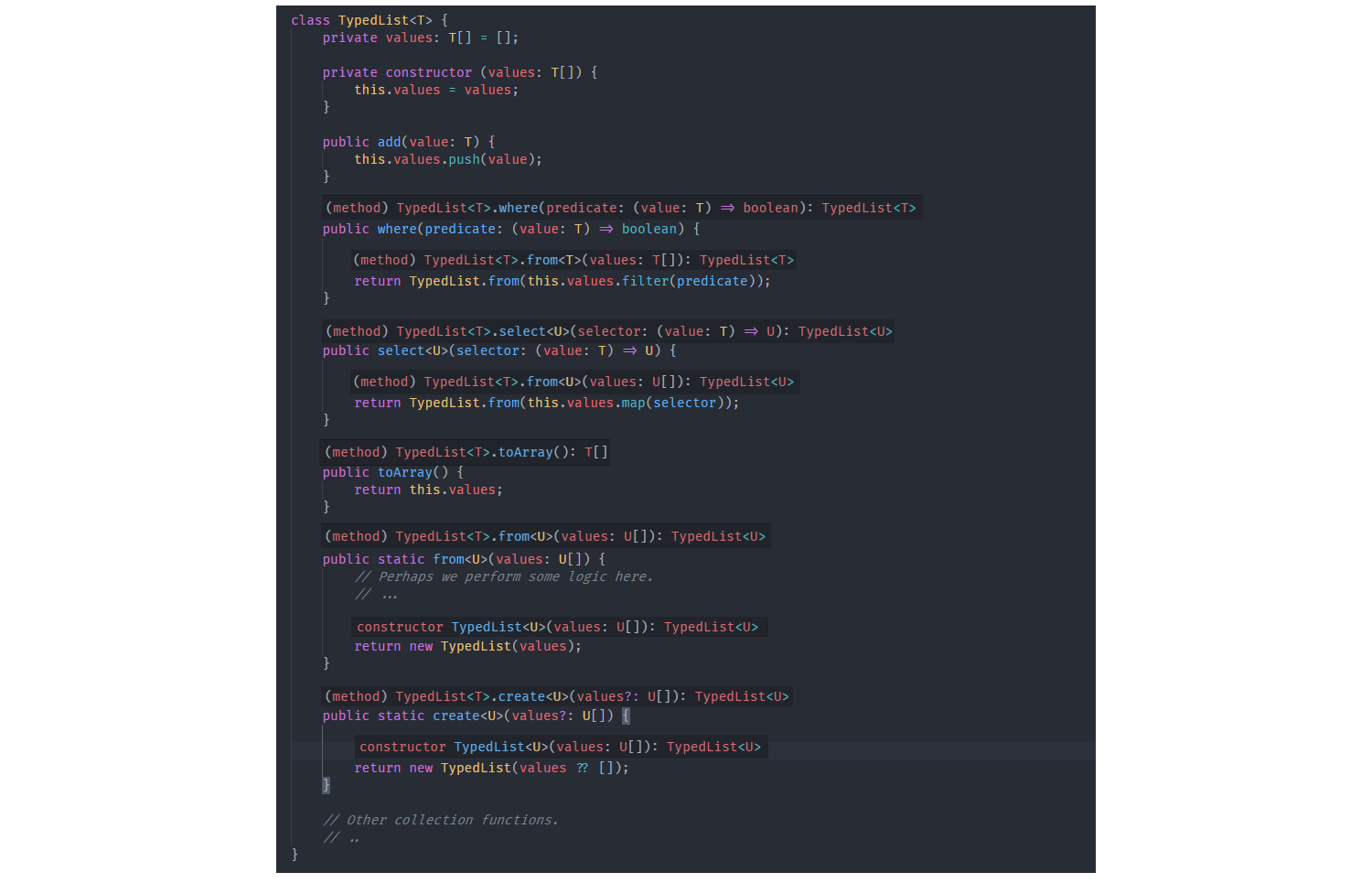
At this point, we should have worked up to the point where we can understand that first TypedList example. Here it is again:
class TypedList {
private values: T[] = [];
private constructor (values: T[]) {
this.values = values;
}
public add(value: T): void {
this.values.push(value);
}
public where(predicate: (value: T) => boolean): TypedList {
return TypedList.from(this.values.filter(predicate));
}
public select(selector: (value: T) => U): TypedList {
return TypedList.from(this.values.map(selector));
}
public toArray(): T[] {
return this.values;
}
public static from(values: U[]): TypedList {
// Perhaps we perform some logic here.
// ...
return new TypedList(values);
}
public static create(values?: U[]): TypedList {
return new TypedList(values ?? []);
}
// Other collection functions.
// ..
}The class itself accepts a generic type parameter named Tand all members of the class are provided access to it. The instance method select and the two static methods from and createwhich are factories, accept their own generic type parameter named U.
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[]. When it calls the list’s constructor with newit passes that type U as the generic parameter to TypedList. This creates a new list where the type of every element is U. It is exactly the same as how we could call the constructor of our collection class earlier with new Collection(). The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I’ve stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass {
private constructor (t: number) {}
public static create(u: number) {
return new MyClass(u);
}
}
const myClass = MyClass.create(2.17);This is very similar to what is happening with the more-involved example, the difference being that we’re working on generic type parameters, not variables. Here, 2.17 becomes the u in createwhich ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass {
private constructor () {}
public static create() {
return new MyClass();
}
}
const myClass = MyClass.create();The U passed to create is ultimately passed in as the T for MyClass. When calling createwe provided number as Uthus now U = number. We put that U (which, again, is just number) into the T for MyClassso that MyClass effectively becomes MyClass. The benefit of generics is that we’re opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U. It uses that type Ujust like createto construct a new instance of the TypedList class, now passing in that type U for T.
The where instance method performs a filtering operation based upon a predicate function. There’s no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript’s array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don’t satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type Twhich is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T. The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we’ll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we’ve used generics, we’ve explicitly defined the type we’re operating on. It’s important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number:
// `value` is inferred as type `number`.
const value = identity(getRandomNumber());To demonstrate type inference, I’ve removed all the technically extraneous type annotations from our TypedList structure earlier, and you can see, from the pictures below, that TSC still infers all types correctly:
TypedList without extraneous type declarations:
class TypedList {
private values: T[] = [];
private constructor (values: T[]) {
this.values = values;
}
public add(value: T) {
this.values.push(value);
}
public where(predicate: (value: T) => boolean) {
return TypedList.from(this.values.filter(predicate));
}
public select(selector: (value: T) => U) {
return TypedList.from(this.values.map(selector));
}
public toArray() {
return this.values;
}
public static from(values: U[]) {
// Perhaps we perform some logic here.
// ...
return new TypedList(values);
}
public static create(values?: U[]) {
return new TypedList(values ?? []);
}
// Other collection functions.
// ..
}Based on function return values and based on the input types passed into from and the constructor, TSC understands all type information. On the image below, I’ve stitched multiple images together which shows Visual Studio’s Code TypeScript’s Language Extension (and thus the compiler) inferring all the types:

Generic Constraints
Sometimes, we want to put a constraint around a generic type. Perhaps we can’t support every type in existence, but we can support a subset of them. Let’s say we want to build a function that returns the length of some collection. As seen above, we could have many different types of arrays/collections, from the default JavaScript Array to our custom ones. How do we let our function know that some generic type has a length property attached to it? Similarly, how do restrict the concrete types we pass into the function to those that contain the data we need? An example such as this one, for instance, would not work:
function getLength(collection: T): number {
// Error. TS does not know that a type T contains a `length` property.
return collection.length;
}The answer is to utilize Generic Constraints. We can define an interface that describes the properties we need:
interface IHasLength {
length: number;
}Now, when defining our generic function, we can constrain the generic type to be one that extends that interface:
function getLength(collection: T): number {
// Restricting `collection` to be a type that contains
// everything within the `IHasLength` interface.
return collection.length;
}Real-World Examples
In the next couple of sections, we’ll discuss some real-world examples of generics that create more elegant and easy-to-reason-about code. We’ve seen a lot of trivial examples, but I want to discuss some approaches to error handling, data access patterns, and front-end React state/props.
Real-World Examples — Approaches To Error Handling
JavaScript contains a first-class mechanism for handling errors, as do most programming languages — try/catch. Despite that, I’m not a very big fan of how it looks when used. That’s not to say I don’t use the mechanism, I do, but I tend to try and hide it as much as I can. By abstracting try/catch away, I can also reuse error handling logic across likely-to-fail operations.
Suppose we’re building some Data Access Layer. This is a layer of the application that wraps the persistence logic for dealing with the data storage method. If we’re performing database operations, and if that database is used across a network, particular DB-specific errors and transient exceptions are likely to occur. Part of the reason for having a dedicated Data Access Layer is to abstract away the database from the business logic. Due to that, we can’t be having such DB-specific errors being thrown up the stack and out of this layer. We need to wrap them first.
Let’s look at a typical implementation that would use try/catch:
async function queryUser(userID: string): Promise {
try {
const dbUser = await db.raw(`
SELECT * FROM users WHERE user_id = ?
`, [userID]);
return mapper.toDomain(dbUser);
} catch (e) {
switch (true) {
case e instanceof DbErrorOne:
return Promise.reject(new WrapperErrorOne());
case e instanceof DbErrorTwo:
return Promise.reject(new WrapperErrorTwo());
case e instanceof NetworkError:
return Promise.reject(new TransientException());
default:
return Promise.reject(new UnknownError());
}
}
}Switching over true is merely a method to be able to use the switch case statements for my error checking logic as opposed to having to declare a chain of if/else if — a trick I first heard from @Jeffijoe.
If we have multiple such functions, we have to replicate this error-wrapping logic, which is a very bad practice. It looks quite good for one function, but it’ll be a nightmare with many. To abstract away this logic, we can wrap it in a custom error handling function that will pass through the result, but catch and wrap any errors should they be thrown:
async function withErrorHandling(
dalOperation: () => Promise
): Promise {
try {
// This unwraps the promise and returns the type `T`.
return await dalOperation();
} catch (e) {
switch (true) {
case e instanceof DbErrorOne:
return Promise.reject(new WrapperErrorOne());
case e instanceof DbErrorTwo:
return Promise.reject(new WrapperErrorTwo());
case e instanceof NetworkError:
return Promise.reject(new TransientException());
default:
return Promise.reject(new UnknownError());
}
}
}To ensure this makes sense, we have a function entitled withErrorHandling that accepts some generic type parameter T. This T represents the type of the successful resolution value of the promise we expect returned from the dalOperation callback function. Usually, since we’re just returning the return result of the async dalOperation function, we wouldn’t need to await it for that would wrap the function in a second extraneous promise, and we could leave the awaiting to the calling code. In this case, we need to catch any errors, thus await is required.
We can now use this function to wrap our DAL operations from earlier:
async function queryUser(userID: string) {
return withErrorHandling(async () => {
const dbUser = await db.raw(`
SELECT * FROM users WHERE user_id = ?
`, [userID]);
return mapper.toDomain(dbUser);
});
}And there we go. We have a type-safe and error-safe function user query function.
Additionally, as you saw earlier, if the TypeScript Compiler has enough information to infer the types implicitly, you don’t have to explicitly pass them. In this case, TSC knows that the return result of the function is what the generic type is. Thus, if mapper.toDomain(user) returned a type of Useryou wouldn’t need to pass the type in at all:
async function queryUser(userID: string) {
return withErrorHandling(async () => {
const dbUser = await db.raw(`
SELECT * FROM users WHERE user_id = ?
`, [userID]);
return mapper.toDomain(user);
});
}Another approach to error handling that I tend to like is that of Monadic Types. The Either Monad is an algebraic data type of the form Eitherwhere T can represent an error type, and U can represent a failure type. Using Monadic Types hearkens to functional programming, and a major benefit is that errors become type-safe — a normal function signature doesn’t tell the API caller anything about what errors that function might throw. Suppose we throw a NotFound error from inside queryUser. A signature of queryUser(userID: string): Promise doesn’t tell us anything about that. But, a signature like queryUser(userID: string): Promise<Either> absolutely does. I won’t explain how monads like the Either Monad work in this article because they can be quite complex, and there are a variety of methods they must have to be considered monadic, such as mapping/binding. If you’d like to learn more about them, I’d recommend two of Scott Wlaschin’s NDC talks, here and hereas well as Daniel Chamber’s talk here. This site as well these blog posts may be useful too.
Real-World Examples — Repository Pattern
Let’s take a look at another use case where Generics might be helpful. Most back-end systems are required to interface with a database in some manner — this could be a relational database like PostgreSQL, a document database like MongoDB, or perhaps even a graph database, such as Neo4j.
Since, as developers, we should aim for lowly coupled and highly cohesive designs, it would be a fair argument to consider what the ramifications of migrating database systems might be. It would also be fair to consider that different data access needs might prefer different data access approaches (this starts to get into CQRS a little bit, which is a pattern for separating reads and writes. See Martin Fowler’s post and the MSDN listing if you wish to learn more. The books “Implementing Domain Driven Design” by Vaughn Vernon and “Patterns, Principles, and Practices of Domain-Driven Design” by Scott Millet are good reads as well). We should also consider automated testing. The majority of tutorials that explain the building of back-end systems with Node.js intermingle data access code with business logic with routing. That is, they tend to use MongoDB with the Mongoose ODM, taking an Active Record approach, and not having a clean separation of concerns. Such techniques are frowned upon in large applications; the moment you decide you’d like to migrate one database system for another, or the moment you realize that you’d prefer a different approach to data access, you have to rip out that old data access code, replace it with new code, and hope you didn’t introduce any bugs to routing and business logic along the way.
Sure, you might argue that unit and integration tests will prevent regressions, but if those tests find themselves coupled and dependent upon implementation details to which they should be agnostic, they too will likely break in the process.
A common approach to solve this issue is the Repository Pattern. It says that to calling code, we should allow our data access layer to mimic a mere in-memory collection of objects or domain entities. In this way, we can let the business drive the design rather than the database (data model). For large applications, an architectural pattern called Domain-Driven Design becomes useful. Repositories, in the Repository Pattern, are components, most commonly classes, that encapsulate and hold internal all the logic to access data sources. With this, we can centralize data access code to one layer, making it easily testable and easily reusable. Further, we can place a mapping layer in between, permitting us to map database-agnostic domain models to a series of one-to-one table mappings. Each function available on the Repository could optionally use a different data access method if you so choose.
There are many different approaches and semantics to Repositories, Units of Work, database transactions across tables, and so on. Since this is an article about Generics, I don’t want to get into the weeds too much, thus I’ll illustrate a simple example here, but it’s important to note that different applications have different needs. A Repository for DDD Aggregates would be quite different than what we’re doing here, for instance. How I portray the Repository implementations here is not how I implement them in real projects, for there is a lot of missing functionality and less-than-desired architectural practices in use.
Let’s suppose we have Users and Tasks as domain models. These could just be POTOs — Plain-Old TypeScript Objects. There is no notion of a database baked into them, thus, you wouldn’t call User.save()for instance, as you would using Mongoose. Using the Repository Pattern, we might persist a user or delete a task from our business logic as follows:
// Querying the DB for a User by their ID.
const user: User = await userRepository.findById(userID);
// Deleting a Task by its ID.
await taskRepository.deleteById(taskID);
// Deleting a Task by its owner’s ID.
await taskRepository.deleteByUserId(userID);Clearly, you can see how all the messy and transient data access logic is hidden behind this repository facade/abstraction, making business logic agnostic to persistence concerns.
Let’s start by building a few simple domain models. These are the models that the application code will interact with. They are anemic here but would hold their own logic to satisfy business invariants in the real-world, that is, they wouldn’t be mere data bags.
interface IHasIdentity {
id: string;
}
class User implements IHasIdentity {
public constructor (
private readonly _id: string,
private readonly _username: string
) {}
public get id() { return this._id; }
public get username() { return this._username; }
}
class Task implements IHasIdentity {
public constructor (
private readonly _id: string,
private readonly _title: string
) {}
public get id() { return this._id; }
public get title() { return this._title; }
}You’ll see in a moment why we extract identity typing information to an interface. This method of defining domain models and passing everything through the constructor is not how I’d do it in the real world. Additionally, relying on an abstract domain model class would have been more preferable than the interface to get the id implementation for free.
For the Repository, since, in this case, we expect that many of the same persistence mechanisms will be shared across different domain models, we can abstract our Repository methods to a generic interface:
interface IRepository {
add(entity: T): Promise;
findById(id: string): Promise;
updateById(id: string, updated: T): Promise;
deleteById(id: string): Promise;
existsById(id: string): Promise;
}We could go further and create a Generic Repository too to reduce duplication. For brevity, I won’t do that here, and I should note that Generic Repository interfaces such as this one and Generic Repositories, in general, tend to be frowned upon, for you might have certain entities which are read-only, or write-only, or which can’t be deleted, or similar. It depends on the application. Also, we don’t have a notion of a “unit of work” in order to share a transaction across tables, a feature I would implement in the real world, but, again, since this is a small demo, I don’t want to get too technical.
Let’s start by implementing our UserRepository. I’ll define an IUserRepository interface which holds methods specific to users, thus permitting calling code to depend on that abstraction when we dependency inject the concrete implementations:
interface IUserRepository extends IRepository {
existsByUsername(username: string): Promise;
}
class UserRepository implements IUserRepository {
// There are 6 methods to implement here all using the
// concrete type of `User` - Five from IRepository
// and the one above.
}The Task Repository would be similar but would contain different methods as the application sees fit.
Here, we’re defining an interface that extends a generic one, thus we have to pass the concrete type we’re working on. As you can see from both interfaces, we have the notion that we send these POTO domain models in and we get them out. The calling code has no idea what the underlying persistence mechanism is, and that’s the point.
The next consideration to make is that depending on the data access method we choose, we’ll have to handle database-specific errors. We could place Mongoose or the Knex Query Builder behind this Repository, for example, and in that case, we’ll have to handle those specific errors — we don’t want them to bubble up to business logic for that would break separation of concerns and introduce a larger degree of coupling.
Let’s define a Base Repository for the data access methods we wish to use that can handle errors for us:
class BaseKnexRepository {
// A constructor.
/**
* Wraps a likely to fail database operation within a function that handles errors by catching
* them and wrapping them in a domain-safe error.
*
* @param dalOp The operation to perform upon the database.
*/
public async withErrorHandling(dalOp: () => Promise) {
try {
return await dalOp();
} catch (e) {
// Use a proper logger:
console.error(e);
// Handle errors properly here.
}
}
}Now, we can extend this Base Class in the Repository and access that Generic method:
interface IUserRepository extends IRepository {
existsByUsername(username: string): Promise;
}
class UserRepository extends BaseKnexRepository implements IUserRepository {
private readonly dbContext: Knex | Knex.Transaction;
public constructor (private knexInstance: Knex | Knex.Transaction) {
super();
this.dbContext = knexInstance;
}
// Example `findById` implementation:
public async findById(id: string): Promise {
return this.withErrorHandling(async () => {
const dbUser = await this.dbContext()
.select()
.where({ user_id: id })
.first();
// Maps type DbUser to User
return mapper.toDomain(dbUser);
});
}
// There are 5 methods to implement here all using the
// concrete type of `User`.
}Notice that our function retrieves a DbUser from the database and maps it to a User domain model before returning it. This is the Data Mapper pattern and it’s crucial to maintaining separation of concerns. DbUser is a one-to-one mapping to the database table — it’s the data model that the Repository operates upon — and is thus highly dependent on the data storage technology used. For this reason, DbUsers will never leave the Repository and will be mapped to a User domain model before being returned. I didn’t show the DbUser implementation, but it could just be a simple class or interface.
Thus far, using the Repository Pattern, powered by Generics, we’ve managed to abstract away data access concerns into small units as well as maintain type-safety and re-usability.
Finally, for the purposes of Unit and Integration Testing, let’s say that we’ll keep an in-memory repository implementation so that in a test environment, we can inject that repository, and perform state-based assertions on disk rather than mocking with a mocking framework. This method forces everything to rely on the public-facing interfaces rather than permitting tests to be coupled to implementation details. Since the only differences between each repository are the methods they choose to add under the ISomethingRepository interface, we can build a generic in-memory repository and extend that within type-specific implementations:
class InMemoryRepository implements IRepository {
protected entities: T[] = [];
public findById(id: string): Promise {
const entityOrNone = this.entities.find(entity => entity.id === id);
return entityOrNone
? Promise.resolve(entityOrNone)
: Promise.reject(new NotFound());
}
// Implement the rest of the IRepository methods here.
}The purpose of this base class is to perform all the logic for handling in-memory storage so that we don’t have to duplicate it within in-memory test repositories. Due to methods like findByIdthis repository has to have an understanding that entities contain an id field, which is why the generic constraint on the IHasIdentity interface is necessary. We saw this interface before — it’s what our domain models implemented.
With this, when it comes to building the in-memory user or task repository, we can just extend this class and get most of the methods implemented automatically:
class InMemoryUserRepository extends InMemoryRepository {
public async existsByUsername(username: string): Promise {
const userOrNone = this.entities.find(entity => entity.username === username);
return Boolean(userOrNone);
// or, return !!userOrNone;
}
// And that’s it here. InMemoryRepository implements the rest.
}Here, our InMemoryRepository needs to know that entities have fields such as id and usernamethus we pass User as the generic parameter. User already implements IHasIdentityso the generic constraint is satisfied, and we also state that we have a username property too.
Now, when we wish to use these repositories from the Business Logic Layer, it’s quite simple:
class UserService {
public constructor (
private readonly userRepository: IUserRepository,
private readonly emailService: IEmailService
) {}
public async createUser(dto: ICreateUserDTO) {
// Validate the DTO:
// ...
// Create a User Domain Model from the DTO
const user = userFactory(dto);
// Persist the Entity
await this.userRepository.add(user);
// Send a welcome email
await this.emailService.sendWelcomeEmail(user);
}
}(Note that in a real application, we’d probably move the call to emailService to a job queue as to not add latency to the request and in the hopes of being able to perform idempotent retries on failures (— not that email sending is particularly idempotent in the first place). Further, passing the whole user object to the service is questionable too. The other issue to note is that we could find ourselves in a position here where the server crashes after the user is persisted but before the email is sent. There are mitigation patterns to prevent this, but for the purposes of pragmatism, human intervention with proper logging will probably work just fine).
And there we go — using the Repository Pattern with the power of Generics, we’ve completely decoupled our DAL from our BLL and have managed to interface with our repository in a type-safe manner. We’ve also developed a way to rapidly construct equally type-safe in-memory repositories for the purposes of unit and integration testing, permitting true black-box and implementation-agnostic tests. None of this would have been possible without Generic types.
As a disclaimer, I want to once again note that this Repository implementation is lacking in a lot. I wanted to keep the example simple since the focus is the utilization of generics, which is why I didn’t handle the duplication or worry about transactions. Decent repository implementations would take an article all by themselves to explain fully and correctly, and the implementation details change depending on whether you’re doing N-Tier Architecture or DDD. That means that if you wish to use the Repository Pattern, you should not look at my implementation here as in any way a best practice.
Real-World Examples — React State & Props
The state, ref, and the rest of the hooks for React Functional Components are Generic too. If I have an interface containing properties for Tasks, and I want to hold a collection of them in a React Component, I could do so as follows:
import React, { useState } from 'react';
export const MyComponent: React.FC = () => {
// An empty array of tasks as the initial state:
const [tasks, setTasks] = useState([]);
// A counter:
// Notice, type of `number` is inferred automatically.
const [counter, setCounter] = useState(0);
return (
Counter Value: {counter}
{
tasks.map(task => (
-
))
}
);
};Additionally, if we want to pass a series of props into our function, we can use the generic React.FC type and get access to props:
import React from 'react';
interface IProps {
id: string;
title: string;
description: string;
}
export const TaskItem: React.FC = (props) => {
return (
{props.title}
{props.description}
);
};The type of props is inferred automatically to be IProps by the TS Compiler.
Conclusion
In this article, we’ve seen many different examples of Generics and their use cases, from simple collections, to error handling approaches, to data access layer isolation, and so on. In the simplest of terms, Generics permit us to build data structures without needing to know the concrete time upon which they will operate at compile-time. Hopefully, this helps to open up the subject a little more, make the notion of Generics a little bit more intuitive, and bring across their true power.

{kind=link}
Source link