



La richesse des données détenues par Amazon peut faire une énorme différence lorsque vous concevez un produit ou recherchez une bonne affaire. Mais comment un développeur peut-il obtenir ces données ? Simple, en utilisant un grattoir Web. Voici comment créer votre bot d'extraction de données avec Node.js.
Avez-vous déjà été dans une position où vous devez connaître intimement le marché d'un produit particulier ? Peut-être que vous lancez un logiciel et que vous avez besoin de savoir comment le tarifer. Ou peut-être avez-vous déjà votre propre produit sur le marché et souhaitez-vous voir quelles fonctionnalités ajouter pour un avantage concurrentiel. Ou peut-être voulez-vous simplement acheter quelque chose pour vous-même et vous assurer d'obtenir le meilleur rapport qualité-prix.
Toutes ces situations ont une chose en commun : vous avez besoin de données précises pour prendre la bonne décision. En fait, il y a autre chose qu'ils partagent. Tous les scénarios peuvent bénéficier de l'utilisation d'un grattoir Web.
Le grattage Web est la pratique consistant à extraire de grandes quantités de données Web à l'aide d'un logiciel. Donc, en substance, c'est un moyen d'automatiser le processus fastidieux consistant à appuyer sur « copier » puis « coller » 200 fois. Bien sûr, un bot peut le faire pendant le temps qu'il vous a fallu pour lire cette phrase, donc ce n'est pas seulement moins ennuyeux, mais aussi beaucoup plus rapide.
Mais la question brûlante est : pourquoi quelqu'un voudrait-il gratter Pages Amazon ?
Vous êtes sur le point de le découvrir ! Mais tout d'abord, j'aimerais clarifier quelque chose dès maintenant : bien que le fait de récupérer des données accessibles au public soit légal, Amazon a mis en place des mesures pour l'empêcher sur ses pages. En tant que tel, je vous exhorte à toujours être attentif au site Web lors du grattage, à ne pas l'endommager et à suivre les directives éthiques.
Lecture recommandée : « Le guide de Scraping éthique de sites Web dynamiques avec Node.js et Puppeteer » par Andreas Altheimer
Étant le plus grand détaillant en ligne de la planète, il est sûr de dire que si vous voulez acheter quelque chose, vous pouvez probablement l'obtenir sur Amazon. Ainsi, il va sans dire à quel point le site Web est un trésor de données.
Lorsque vous explorez le Web, votre principale question devrait être de savoir quoi faire avec toutes ces données. Bien qu'il existe de nombreuses raisons individuelles, cela se résume à deux cas d'utilisation importants : optimiser vos produits et trouver les meilleures offres.
Commençons par le premier scénario. À moins que vous n'ayez conçu un nouveau produit vraiment innovant, il est probable que vous puissiez déjà trouver quelque chose au moins similaire sur Amazon. Le grattage de ces pages de produits peut vous rapporter des données inestimables telles que :
- La stratégie de prix des concurrents
Ainsi, vous pouvez ajuster vos prix pour être compétitif et comprendre comment les autres gèrent les offres promotionnelles ; - Avis des clients
Pour voir ce qui intéresse le plus votre future clientèle et comment améliorer leur expérience ; - Fonctionnalités les plus courantes
Pour voir ce que vos concurrents proposent pour savoir quelles fonctionnalités sont cruciales et lesquelles peuvent être laissées pour plus tard.
Dans essence, Amazon a tout ce dont vous avez besoin pour une analyse approfondie du marché et des produits. Vous serez mieux préparé à concevoir, lancer et étendre votre gamme de produits avec ces données.
Le deuxième scénario peut s'appliquer à la fois aux entreprises et aux particuliers. L'idée est assez similaire à ce que j'ai mentionné plus tôt. Vous pouvez consulter les prix, les caractéristiques et les avis de tous les produits que vous pouvez choisir, et ainsi, vous pourrez choisir celui qui offre le plus d'avantages au prix le plus bas. Après tout, qui n'aime pas les bonnes affaires ?
Tous les produits ne méritent pas ce niveau d'attention aux détails, mais cela peut faire une énorme différence avec des achats coûteux. Malheureusement, bien que les avantages soient clairs, de nombreuses difficultés accompagnent le grattage d'Amazon.
Les défis de la récupération des données de produit Amazon
Tous les sites Web ne sont pas identiques. En règle générale, plus un site Web est complexe et répandu, plus il est difficile de le supprimer. Vous vous souvenez quand j'ai dit qu'Amazon était le site de commerce électronique le plus important ? Eh bien, cela le rend à la fois extrêmement populaire et raisonnablement complexe.
Tout d'abord, Amazon sait comment agissent les robots de grattage, de sorte que le site Web a mis en place des contre-mesures. À savoir, si le scraper suit un modèle prévisible, en envoyant des demandes à intervalles fixes, plus rapidement qu'un humain ou avec des paramètres presque identiques, Amazon remarquera et bloquera l'IP. Les proxys peuvent résoudre ce problème, mais je n'en ai pas eu besoin car nous n'allons pas gratter trop de pages dans l'exemple.
Ensuite, Amazon utilise délibérément des structures de page différentes pour ses produits. C'est-à-dire que si vous inspectez les pages pour différents produits, il y a de fortes chances que vous trouviez des différences significatives dans leur structure et leurs attributs. La raison derrière cela est assez simple. Vous devez adapter le code de votre scraper pour un système spécifiqueet si vous utilisez le même script sur un nouveau type de page, vous devrez en réécrire certaines parties. Donc, ils vous font essentiellement travailler davantage pour les données.
Enfin, Amazon est un vaste site Web. Si vous souhaitez collecter de grandes quantités de données, l'exécution du logiciel de grattage sur votre ordinateur peut s'avérer trop longue pour vos besoins. Ce problème est encore renforcé par le fait qu'aller trop vite bloquera votre grattoir. Donc, si vous voulez des charges de données rapidement, vous aurez besoin d'un grattoir vraiment puissant.
Bon, assez parlé de problèmes, concentrons-nous sur les solutions ! garder les choses simples, nous allons adopter une approche étape par étape pour écrire le code. N'hésitez pas à travailler en parallèle avec le guide.
Recherchez les données dont nous avons besoin
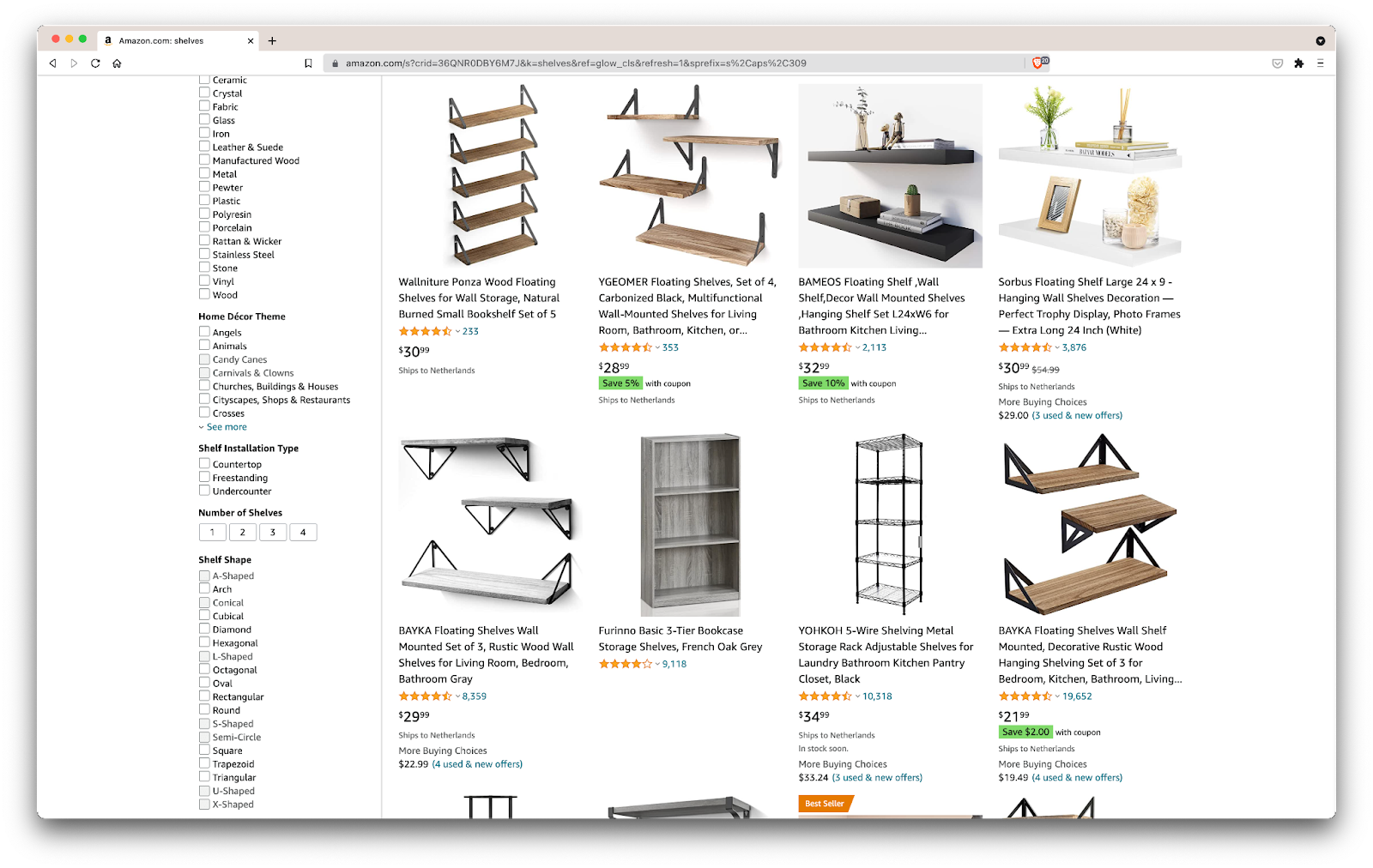
Donc, voici un scénario : je déménage dans quelques mois dans un nouvel endroit, et j'aurai besoin de quelques nouveaux étagères pour contenir des livres et des magazines. Je veux connaître toutes mes options et obtenir le meilleur accord possible. Alors, allons sur le marché Amazon, recherchons « étagères » et voyons ce que nous obtenons.
L'URL pour cette recherche et la page que nous allons gratter est ici.


Ok, faisons le point sur ce que nous avons ici. En regardant simplement la page, nous pouvons avoir une bonne idée de :
- à quoi ressemblent les étagères ;
- ce que le forfait comprend ;
- comment les clients les évaluent ;
- leur prix ;
- le lien au produit ;
- une suggestion pour une alternative moins chère pour certains des articles.
C'est plus que ce que nous pourrions demander !
Obtenez les outils requis
Assurons-nous que tous les outils suivants sont installés et configuré avant de passer à l'étape suivante.
- Chrome
Nous pouvons le télécharger à partir de ici. - VSCode
Suivez les instructions sur cette page pour l'installer sur votre appareil spécifique. - Node.js
Avant de commencer à utiliser Axios ou Cheerio, nous devons installer Node.js et Node Package Manager. Le moyen le plus simple d'installer Node.js et NPM est d'obtenir l'un des programmes d'installation de la source officielle de Node.Js et de l'exécuter.
Maintenant, créons un nouveau projet NPM. Créez un nouveau dossier pour le projet et exécutez la commande suivante :
npm init -yPour créer le grattoir Web, nous devons installer quelques dépendances dans notre projet :
- Cheerio[19659055]Une bibliothèque open source qui nous aide à extraire des informations utiles en analysant le balisage et en fournissant une API pour manipuler les données résultantes. Cheerio nous permet de sélectionner les balises d'un document HTML en utilisant des sélecteurs :
$("div"). Ce sélecteur spécifique nous aide à sélectionner tous leséléments d'une page. Pour installer Cheerio, veuillez exécuter la commande suivante dans le dossier des projets :npm install cheerio- Axios
Une bibliothèque JavaScript utilisée pour effectuer des requêtes HTTP à partir de Node.js.
npm install axiosInspecter la source de la page
Dans les étapes suivantes, nous en apprendrons davantage sur la façon dont les informations sont organisées sur la page. L'idée est de mieux comprendre ce que nous pouvons extraire de notre source.
Les outils de développement nous aident à explorer de manière interactive le modèle d'objet de document (DOM) du site Web. Nous utiliserons les outils de développement de Chrome, mais vous pouvez utiliser n'importe quel navigateur Web avec lequel vous êtes à l'aise.
Ouvons-le en cliquant avec le bouton droit n'importe où sur la page et en sélectionnant l'option « Inspecter » :

Le processus est le même pour macOS et Windows. ( Grand aperçu)
Cela ouvrira une nouvelle fenêtre contenant le code source de la page. Comme nous l'avons déjà dit, nous cherchons à récupérer les informations de chaque étagère.

Cela peut sembler intimidant, mais c'est en fait plus facile qu'il n'y paraît. ( Grand aperçu)
Comme nous pouvons le voir sur la capture d'écran ci-dessus, les conteneurs qui contiennent toutes les données ont les classes suivantes :
sg-col-4-of-12 s-result-item s-asin sg-col-4- of-16 sg-col sg-col-4-of-20Dans l'étape suivante, nous utiliserons Cheerio pour sélectionner tous les éléments contenant les données dont nous avons besoin.
Récupérer les données
Après avoir installé toutes les dépendances présentées ci-dessus, créons un nouveau fichier
index.jset tapons les lignes de code suivantes :const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { essayer { réponse const = wait axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = réponse.data; const $ = cheerio.load(html); étagères const = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20') .each((_idx, el) => { étagère const = $(el) const title = étagère.find('span.a-size-base-plus.a-color-base.a-text-normal').text() étagères.push(titre) }); étagères de retour ; } catch (erreur) { erreur de lancer ; } } ; fetchShelves().then((shelves) => console.log(shelves));Comme nous pouvons le voir, nous importons les dépendances dont nous avons besoin sur les deux premières lignes, puis nous créons un
fetchShelves()fonction qui, à l'aide de Cheerio, récupère tous les éléments contenant les informations de nos produits à partir de la page.Il itère sur chacun d'eux et le pousse vers un tableau vide pour obtenir un résultat mieux formaté.
Le La fonction
fetchShelves()ne renverra que le titre du produit pour le moment, alors obtenons le reste des informations dont nous avons besoin. Veuillez ajouter les lignes de code suivantes après la ligne où nous avons défini la variabletitle.const image = étagère.find('img.s-image').attr('src') const link = étagère.find('a.a-link-normal.a-text-normal').attr('href') const reviews = étagère.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last ().attr('aria-label') const stars = étagère.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') prix const = étagère.find('span.a-price > span.a-offscreen').text() let élément = { Titre, image, lien : `https://amazon.com${link}`, le prix, } si (critiques) { element.reviews = avis } si (étoiles) { élément.stars = étoiles }Et remplacez
shelves.push(title)parshelves.push(element).Nous sélectionnons maintenant toutes les informations dont nous avons besoin et les ajoutons à un nouveau objet appelé
élément. Chaque élément est ensuite poussé vers le tableaushelvespour obtenir une liste d'objets contenant uniquement les données que nous recherchons.Voici à quoi devrait ressembler un objet
shelfavant lui. est ajouté à notre liste :{ title : « Étagères murales SUPERJARE, lot de 2, rebord d'affichage, support de rangement pour pièce/cuisine/bureau - blanc », image : 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', lien : 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating%332Fd2%Fcri%H%FLUPERJARE_Floating%32Fd2Fcri%H 3D36QNR0DBY6M7J%26dchild%3D1%26mots-clés%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26pscd%get3D1&18t&=1627974209 prix : « 32,99 $ », avis : « 6 171 », étoiles : '4,7 étoiles sur 5' }Formater les données
Maintenant que nous avons réussi à récupérer les données dont nous avons besoin, c'est une bonne idée de les enregistrer en tant que fichier
.CSVpour améliorer la lisibilité. Après avoir obtenu toutes les données, nous utiliserons le modulefsfourni par Node.js et enregistrerons un nouveau fichier appelésaved-shelves.csvdans le dossier du projet. Importez le modulefsen haut du fichier et copiez ou écrivez le long des lignes de code suivantes :let csvContent = étagères.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("n") fs.writeFile('saved-shelves.csv', "Titre, Image, Lien, Prix, Avis, Étoiles" + 'n' + csvContent, 'utf8', fonction (err) { si (erreur) { console.log('Une erreur s'est produite - fichier non enregistré ou corrompu.') } autre{ console.log('Le fichier a été enregistré !') } })Comme nous pouvons le voir, sur les trois premières lignes, nous formatons les données que nous avons précédemment recueillies en joignant toutes les valeurs d'un objet de rayon à l'aide d'une virgule. Ensuite, en utilisant le module
fsnous créons un fichier appelésaved-shelves.csvajoutons une nouvelle ligne qui contient les en-têtes de colonnes, ajoutons les données que nous venons de formater et créons un fonction de rappel qui gère les erreurs.Le résultat devrait ressembler à ceci :

Données douces et organisées. ( Grand aperçu)
Astuces bonus !
Scraping Single Page Applications
Le contenu dynamique devient la norme de nos jours, car les sites Web sont plus complexes que jamais. Pour offrir la meilleure expérience utilisateur possible, les développeurs doivent adopter différents mécanismes de chargement pour le contenu dynamiquece qui complique un peu notre travail. Si vous ne savez pas ce que cela signifie, imaginez un navigateur sans interface utilisateur graphique. Heureusement, il existe ✨Puppeteer✨ – la bibliothèque de nœuds magique qui fournit une API de haut niveau pour contrôler une instance Chrome via le protocole DevTools. Pourtant, il offre les mêmes fonctionnalités qu'un navigateur, mais il doit être contrôlé par programme en tapant quelques lignes de code. Voyons comment cela fonctionne.
Dans le projet créé précédemment, installez la bibliothèque Puppeteer en exécutant
npm install puppeteercréez un nouveau fichierpuppeteer.jset copiez ou écrivez avec les lignes de code suivantes :const puppeteer = require('puppeteer') (async () => { essayer { const chrome = wait puppeteer.launch() const page = attend chrome.newPage() attendez page.goto('https://www.reddit.com/r/Kanye/hot/') wait page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout : 2000 }) const body = wait page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(corps) attendre chrome.close() } catch (erreur) { console.log(erreur) } })()Dans l'exemple ci-dessus, nous créons une instance Chrome et ouvrons une nouvelle page de navigateur qui est requise pour accéder à ce lien. Dans la ligne suivante, nous demandons au navigateur sans tête d'attendre que l'élément avec la classe
rpBJOHq2PR60pnwJlUyP0apparaisse sur la page. Nous avons également spécifié combien de temps le navigateur doit attendre le chargement de la page (2000 millisecondes).En utilisant la méthode
evaluatesur la variablepagenous avons demandé à Puppeteer d'exécuter les extraits Javascript dans le contexte de la page juste après le chargement final de l'élément. Cela nous permettra d'accéder au contenu HTML de la page et de renvoyer le corps de la page en tant que sortie. Nous fermons ensuite l'instance Chrome en appelant la méthodeclosesur la variablechrome. Le travail résultant devrait consister en tout le code HTML généré dynamiquement. C'est ainsi que Puppeteer peut nous aider à charger du contenu HTML dynamique.Si vous ne vous sentez pas à l'aise avec Puppeteer, notez qu'il existe quelques alternatives, comme NightwatchJS, NightmareJS ou CasperJS. Ils sont légèrement différents, mais au final, le processus est assez similaire.
user-agentest un en-tête de requête qui informe le site Web que vous visitez sur vous-même, à savoir votre navigateur et votre système d'exploitation. Ceci est utilisé pour optimiser le contenu de votre configuration, mais les sites Web l'utilisent également pour identifier les robots qui envoient des tonnes de requêtes, même si cela change l'IPS.Voici à quoi ressemble un en-tête
user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/93.0.4577.82 Safari/537.36Afin de ne pas être détecté et bloqué, vous devez modifier régulièrement cet en-tête. Faites particulièrement attention à ne pas envoyer un en-tête vide ou obsolète, car cela ne devrait jamais arriver pour un utilisateur courant et vous vous démarquerez. mais il faut éviter d'aller à toute vitesse. Il y a deux raisons à cela :
- Trop de demandes en peu de temps peuvent ralentir le serveur du site Web ou même le faire tomber, causant des problèmes au propriétaire et aux autres visiteurs. Cela peut essentiellement devenir une attaque DoS. La solution consiste à introduire un délai entre vos demandes, une pratique appelée « limitation de débit ». (C'est assez simple à implémenter aussi !)
Dans l'exemple de Puppeteer fourni ci-dessus, avant de créer la variable
bodynous pouvons utiliser la méthodewaitForTimeoutfourni par Puppeteer pour attendre quelques secondes avant de faire une autre demande :wait page.waitForTimeout(3000) ;où
msest le nombre de secondes que vous voudriez attendre.De plus, si nous voulons faire la même chose pour l'exemple axios, nous pouvons créer une promesse qui appelle la méthode
setTimeout()afin de nous aider à attendre le nombre de millisecondes souhaité :[19659109]fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))De cette façon, vous pouvez éviter de mettre trop de pression sur le serveur ciblé et aussi, apportez une approche plus humaine du grattage Web.
Réflexions finales
Et voilà, un guide étape par étape pour créer votre propre scr Web aper pour les données produit d'Amazon ! Mais rappelez-vous, ce n'était qu'une situation. Si vous souhaitez scraper un autre site Web, vous devrez apporter quelques modifications pour obtenir des résultats significatifs. quelques lectures utiles pour vous :

Source link - Axios



{kind=link}
{kind=link}
{kind=link}
{kind=link}