


Dans l’écosystème de données moderne, la vitesse et l’efficacité sont primordiales. Que vous construisiez des pipelines d’analyse en temps réel ou que vous émettiez des systèmes distribués, le goulot d’étranglement réside souvent dans la sérialisation des données et le transport. Entrez le vol d’Apache Arrow – un cadre RPC haute performance conçu pour déplacer efficacement les grands ensembles de données à l’aide du format de mémoire fléchée.
Apache Arrow Flight est un framework RPC haute performance conçu pour un transfert de données rapide construit au-dessus du format de mémoire en colonne de flèche Apache. Il traite des goulots d’étranglement des méthodes d’échange traditionnelles d’échange de données (comme REST ou JDBC / ODBC) en permettant un streaming efficace, parallèle et zéro-copy de données formulées par la flèche entre les systèmes.
Les protocoles de transfert de données traditionnels comme REST ou GRPC luttent souvent avec de grands ensembles de données tabulaires en raison des frais généraux de sérialisation. Le vol d’Apache Arrow résout ceci par:
- Élimination des goulots d’étranglement de sérialisation via le format en mémoire en colory de Arrow.
- Utilisation de GRPC sous le capot pour une communication rapide et évolutive.
- Prendre en charge des flux de données parallèles, permettant des transferts à haut débit.
Cela le rend idéal pour les cas d’utilisation comme:
- Moteurs de requête distribués
- Pipelines de formation du modèle ML
- Tableaux de bord en temps réel
- Intégrations Data Lake
Voici une vue simplifiée de l’architecture d’Arrow Flight:

Architecture de vol Apache Arrow
1. Modèle client-serveur
Arrow Flight utilise une architecture client-serveur basée sur GRPC où:
- Flight Server héberge les points de terminaison des données
- Le client Flight se connecte au serveur pour demander ou envoyer des données
2. Composants de base
- Serveur de vol
- Implémente Arrow Flight Service
- Hôte des points de terminaison pour l’accès aux données
- Peut prendre en charge plusieurs flux parallèles
- Client de vol
- Initie des demandes au serveur
- Utilise des descripteurs pour identifier les ensembles de données
- Récupère les données à l’aide de billets
- Vol de vol
- Identifie l’ensemble de données ou la requête
- Peut être un chemin ou une commande (par exemple, requête SQL)
- Flightinfo
- Métadonnées sur l’ensemble de données
- Comprend le schéma, les points de terminaison et les billets
- Courant de vol
- Jeton utilisé pour récupérer des données
- Le canal de transfert de données réel à l’aide de disques Arrow.
- Le client envoie un FlightDescripteur au serveur.
- Le serveur répond avec FlightInfo, y compris les points de terminaison et le schéma.
- Le client initie un FlightStream pour récupérer ou télécharger des données.
- Les données sont transférées sous forme de disques de flèches, en évitant la sérialisation coûteuse.
Cette conception permet des lectures, du parallélisme et du streaming à copie zéro, ce qui le rend idéal pour les systèmes de données hautes performances

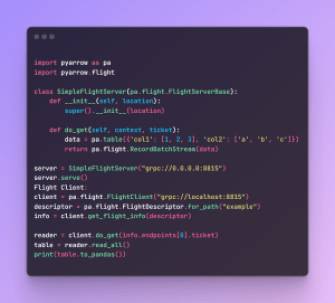
Extrait de code de vol de flèche
Arrow Flight a montré des améliorations de performances 10x à 100x par rapport aux API REST traditionnelles pour les grands ensembles de données. Cela est dû à:
- Format colonnel: optimisé pour le cache CPU et les opérations vectorisées.
- Streaming: évite de charger des ensembles de données entiers en mémoire.
- Parallélisme: plusieurs flux peuvent être utilisés simultanément.
Arrow Flight s’intègre parfaitement à:
- Apache Spark: pour le traitement des données distribuées.
- Pandas & Numpy: pour les workflows de science des données.
- DuckDB & Dremio: pour l’analyse en mémoire.
- Systèmes natifs du cloud: via le support GRPC et TLS.
Apache Arrow Flight change la donne pour les ingénieurs de données et les architectes système qui cherchent à optimiser le mouvement des données à travers les systèmes distribués. Sa combinaison du format de mémoire efficace d’Arrow et des capacités RPC de Flight en fait un outil puissant pour construire des plates-formes de données évolutives et hautes performances.
Si vous travaillez avec de grands ensembles de données, des pipelines en temps réel ou des analyses distribuées, il est temps de donner à Arrow Flight un look sérieux.
Source link